【从零打造高通平台hexagon dsp profiling性能分析工具-3】
从零打造高通平台hexagon dsp profiling性能分析工具-3
前言
高通hexagon dsp现有性能分析工具有各种不足,要想打造合手的”如意金箍棒”只能自研,自己构建,不断扩展完善,后续在线roofline 分析加进去,不受制与人。
能开发工具的人,他对性能指标的理解程度是很深的,对算法性能优化,系统级优化会更有敏锐的观察判断力。
自研不是闭门造车,要充分了解现有工具的工作原理、存在的问题,思考怎么解决这些不足。
结合本系列文档第一篇的分析,模仿itrace进行工具构建是一个比较好的选择,即可以cpu/dsp/ddr/cache等横向联合分析,又可以roi分析,定制化能力强。
itrace内部的实现机制
1. pmu_event的后处理模式
根据pmu类型的不同,有三种处理模式。
- 非running counters类型的pmu event如主频信息,用ITRACE_PM_RAW模式记录原始数据
- running counters类型的pmu event如ITRACE_DSP_EVENT_PMU_COMMITTED_PKT_ANY默认用ITRACE_PM_DELTA模式处理,也即保存当前值与上一次记录值的差值。
- 如果采样时间不均匀,则可以将pmu delta val这个增量值除以实际相邻间隔时间进行归一化,引出ITRACE_PM_NORMALIZED模式。
typedef enum {
ITRACE_PM_DEFAULT, /*!< Use ITRACE_PM_DELTA for running counters and ITRACE_PM_RAW otherwise */
ITRACE_PM_RAW, /*!< Event value unmodified. */
ITRACE_PM_DELTA, /*!< Difference with previously measured event value */
ITRACE_PM_NORMALIZED /*!< Difference with previously measured event value, normalized by elapsed time */
} itrace_processing_mode_t;
2. 先通过api add 我们关心的pmu event再register
2.1 add events:
由于cdsp硬件一次只能同时get 8 PMUs,而我们要分析的指标可能比较多,这里就要仔细权衡了。
将必须同一时间抓的events指标分配到同一组,用ITRACE_NEW_EVENT_SET来标识,否则结果会异常。个别pmu events可以设置自定义processing_mode。
我们在使用linux perf抓pmu events是也同样有这个问题,也要注意合理分组的问题。
例如arm v8.5有多达30个64bit pmu event counters,所以arm cpu上这个影响相对小一点。
/*! Maximum number of events to be registered (in multiple passes if necessary) */
#define ITRACE_MAX_NUMBER_EVENTS_TO_REGISTER 2056
/*! Maximum number of events that can be registered at a time */
#define ITRACE_MAX_NUMBER_REGISTERED_EVENTS 40
#define TIMELOG_SIZE (1024*1024)
int num_dsp_events=0;
itrace_event_t attempted_to_register_dsp_events[ITRACE_MAX_NUMBER_REGISTERED_EVENTS+1]; // +1 to account for event set start marker
int num_attempted_to_register_events=0;
itrace_logger_handle_t logger_handle=NULL;
itrace_profiler_handle_t cpu_profiler_handle=NULL;
itrace_profiler_handle_t dsp_profiler_handle=NULL;
itrace_event_t dsp_events_array[ITRACE_MAX_NUMBER_EVENTS_TO_REGISTER] = {0};
itrace_open_logger(CPU_DOMAIN_ID,&logger_handle);
itrace_open_profiler(logger_handle, CPU_DOMAIN_ID, TIMELOG_SIZE, &cpu_profiler_handle);
itrace_open_profiler(logger_handle, CDSP_DOMAIN_ID, 4*TIMELOC_SIZE, &dsp_profiler_handle);
//此处可以设置processing_mode,如果不显式设置则按默认规则处理,也是能满足大部分要求的
//pmu events可以在后续的组中重复设置
dsp_events_array[num_dsp_events].event_id=ITRACE_DSP_EVENT_STACK_USED_B;
dsp_events_array[num_dsp_events++].processing_mode=ITRACE_PM_DELTA;
dsp_events_array[num_dsp_events++].event_id=ITRACE_DSP_EVENT_PMU_COMMITTED_FPS;
dsp_events_array[num_dsp_events++].event_id=ITRACE_DSP_EVENT_PMU_AXI_WRITE_REQUEST;
dsp_events_array[num_dsp_events].event_id=ITRACE_DSP_EVENT_PMU_COMMITTED_PKT_ANY;
dsp_events_array[num_dsp_events++].processing_mode=ITRACE_PM_NORMALIZED;
dsp_events_array[num_dsp_events++].event_id=ITRACE_DSP_EVENT_PMU_AXI_LINE128_READ_REQUEST;
dsp_events_array[num_dsp_events++].event_id=ITRACE_NEW_EVENT_SET;
//用ITRACE_NEW_EVENT_SET标识下一组开始
//new group set
//关注硬件线程并行性
dsp_events_array[num_dsp_events++].event_id=ITRACE_DSP_EVENT_PMU_COMMITTED_PKT_1_THREAD_RUNNING;
dsp_events_array[num_dsp_events++].event_id=ITRACE_DSP_EVENT_PMU_COMMITTED_PKT_2_THREAD_RUNNING;
dsp_events_array[num_dsp_events++].event_id=ITRACE_DSP_EVENT_PMU_COMMITTED_PKT_3_THREAD_RUNNING;
dsp_events_array[num_dsp_events++].event_id=ITRACE_DSP_EVENT_PMU_COMMITTED_PKT_4_THREAD_RUNNING;
dsp_events_array[num_dsp_events++].event_id=ITRACE_DSP_EVENT_PMU_COMMITTED_PKT_5_THREAD_RUNNING;
dsp_events_array[num_dsp_events++].event_id=ITRACE_DSP_EVENT_PMU_COMMITTED_PKT_6_THREAD_RUNNING;
dsp_events_array[num_dsp_events++].event_id=ITRACE_DSP_EVENT_PMU_COMMITTED_PKT_ANY;
dsp_events_array[num_dsp_events++].event_id=ITRACE_DSP_EVENT_PMU_HVX_ACTIVE;
dsp_events_array[num_dsp_events++].event_id=ITRACE_NEW_EVENT_SET;
//new group set
//关注dsp-ddr总线情况
dsp_events_array[num_dsp_events++].event_id=ITRACE_DSP_EVENT_PMU_AXI_LINE256_READ_REQUEST;
dsp_events_array[num_dsp_events++].event_id=ITRACE_DSP_EVENT_PMU_AXI_LINE128_READ_REQUEST;
dsp_events_array[num_dsp_events++].event_id=ITRACE_DSP_EVENT_PMU_AXI_LINE64_READ_REQUEST;
dsp_events_array[num_dsp_events++].event_id=ITRACE_DSP_EVENT_PMU_AXI_LINE32_READ_REQUEST;
dsp_events_array[num_dsp_events++].event_id=ITRACE_DSP_EVENT_PMU_AXI_LINE256_WRITE_REQUEST;
dsp_events_array[num_dsp_events++].event_id=ITRACE_DSP_EVENT_PMU_AXI_LINE128_WRITE_REQUEST;
dsp_events_array[num_dsp_events++].event_id=ITRACE_DSP_EVENT_PMU_AXI_LINE64_WRITE_REQUEST;
dsp_events_array[num_dsp_events++].event_id=ITRACE_DSP_EVENT_PMU_AXI_LINE32_WRITE_REQUEST;
dsp_events_array[num_dsp_events++].event_id=ITRACE_NEW_EVENT_SET;
itrace_add_events(dsp_profiler_handle, dsp_events_array, num_dsp_events);
#这里是难点
ITRACE_MULTI_PASS_START_LOOP(logger_handle, dsp_profiler_handle);
itrace_register_events(dsp_profiler_handle, &attempted_to_register_events, &num_attempted_to_register_events);
do_dsp_process...
ITRACE_MULTI_PASS_END_LOOP(logger_handle, dsp_profiler_handle);
2.2 register events:
上一小节add events步骤只是组织数据结构,巧妙的地方在register events环节,但这也是受限与max 8的无奈之举。
ITRACE_MULTI_PASS_START_LOOP与ITRACE_MULTI_PASS_END_LOOP实际上是宏函数,是一个循环,每次循环,会换另外一组之前定义好的pmu event监控组进行监控,待测试的代码段会重新跑一遍,每跑一遍都会独立存一个文件,然后merg合并成为一个pmu记录文件。
/*! Indicate the start of the code block that needs monitoring with more events than supported in a single pass.
*
* The code block identified between @ref ITRACE_MULTI_PASS_START_LOOP and @ref ITRACE_MULTI_PASS_END_LOOP
* will be executed as many times as is required to monitor all the events that have been added.
*
* @param[in] logger_handle Handle to the logger instance to use.
* @param[in] profiler_handle Handle to the profiler instance to use.
*/
#define ITRACE_MULTI_PASS_START_LOOP(logger_handle, profiler_handle) \
char itracemp_root_filename[64]; \
itrace_get_root_filename(logger_handle, itracemp_root_filename); \
int itracemp_file_index=0; \
while(1) { /* event loop */ \
int num_events_left_to_register=0; \
itrace_get_num_events_left_to_register(profiler_handle, &num_events_left_to_register); \
if (num_events_left_to_register==0) { \
break; \
} \
char itracemp_root_filename_loop[64]; \
snprintf(itracemp_root_filename_loop,64,"%s_%d",itracemp_root_filename,itracemp_file_index++); \
itrace_set_root_filename(logger_handle, itracemp_root_filename_loop); \
printf("Processing new set into root filename %s. %d events and set separators left to process.\n", itracemp_root_filename_loop, num_events_left_to_register);
/*! Indicate the end of the code block that needs monitoring
*
* @param[in] logger_handle Handle to the logger instance to use.
* @param[in] profiler_handle Handle to the profiler instance to use.
*/
#define ITRACE_MULTI_PASS_END_LOOP(logger_handle, profiler_handle) \
itrace_flush_logs(logger_handle); \
} \
2.3 periodic_events_reader:
只靠ITRACE_MULTI_PASS_START_LOOP与ITRACE_MULTI_PASS_END_LOOP实现的是多于8个pmu的监控,在每次分析过程中时间颗粒度比较粗,如果想更精细的分析,需要结合periodic sampler机制。
可以调用下面api启动一个sampler线程来固定间隔周期性获取注册的pmu events事件值。
itrace_start_periodic_events_reader(dsp_profiler_handle, EVENT_READER_PERIOD_US, EVENT_READER_THREAD_PRIORITY);
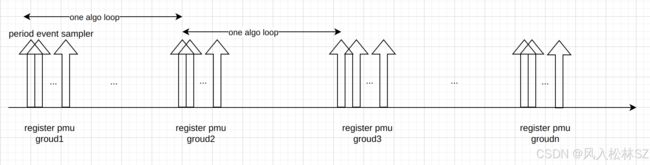
下面这个图展示了itrace中MULTI_PASS机制与periodic event sample机制配合下的效果。
MULTI_PASS机制实际上是一个循环,通过多次运行同样的algo算法程序,每次切换一组pmu配置来完成多pmu监控。
periodic event sample机制实现一次循环中比较细颗粒度的pmu监控,发现一下瞬变事件及其关联关系,例如cache miss增加、core stall 、ddr总线活跃事件的先后关系。
总结
本文介绍了高通dsp itrace 的add events功能、register events功能、 periodic sampler功能及相互关联。
高通itrace 提供了libitrace.so 及libritrace_skel.so两个库进行了上述功能的封装,待分析的工程cpu及dsp代码需要分别链接这两个库才行。
add event过程起配置的作用,相关信息会通过fastrpc调用传到dsp侧,dsp skel库会创建线程,调用qurt pmu接口实现相应的功能cfg/get功能,并将结果回传cpu,由cpu进行数据后处理及存json,csv,txt等文件格式。
后面文章会进一步介绍itrace marker功能,cpu/dsp都能用,接口通一,非常类似android atrace marker。
只不过区别在于dsp itrace 使用的是dsp时间qtime,而android atrace使用的是android time,两个时间域是不一样的。
如果谁有atrace与itrace的联合分析需求,这就比较复杂了,到底是itrace往atrace上靠呢,还是反过来。不过也有方法。