VARGPT:将视觉理解与生成统一在一个模型中,北大推出支持混合模态输入与输出的多模态统一模型
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发非常感兴趣,我会每日分享大模型与 AI 领域的最新开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术,欢迎关注我哦!
微信公众号|搜一搜:蚝油菜花
快速阅读
- 模型简介:VARGPT是北京大学推出的多模态大语言模型,专注于视觉理解和生成任务。
- 主要功能:支持混合模态输入输出、高效视觉生成和广泛的多模态任务。
- 技术原理:基于自回归框架,采用三阶段训练策略,包含专门的视觉解码器。
正文(附运行示例)
VARGPT是什么
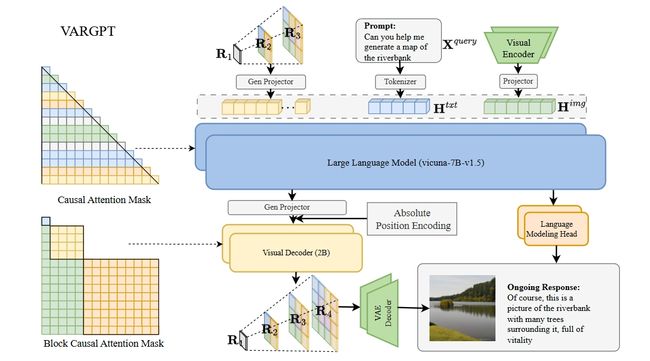
VARGPT是北京大学推出的一款创新的多模态大语言模型,专注于视觉理解和生成任务。该模型基于自回归框架,将视觉生成与理解统一在一个模型中,避免了任务切换的复杂性。
VARGPT在LLaVA架构基础上进行扩展,通过next-token预测实现视觉理解,通过next-scale预测实现视觉生成,能够高效处理混合模态输入和输出。
VARGPT采用三阶段训练策略:预训练阶段学习语言和视觉特征,混合视觉指令微调阶段进一步对齐视觉和文本特征并增强指令遵循能力。这使得模型在视觉问答、推理等任务上表现出色,同时在视觉生成任务中展现出强大的能力,能够自然地生成高质量图像。
VARGPT的主要功能
- 视觉理解与生成的统一:VARGPT在单一的自回归框架内实现视觉理解和视觉生成。通过next-token预测范式完成视觉理解任务,如视觉问答和推理,基于next-scale预测范式实现视觉生成。
- 混合模态输入与输出:VARGPT支持文本和图像的混合模态输入,能同时输出文本和图像。在处理复杂的视觉-语言任务时更加灵活和高效。
- 高效视觉生成:VARGPT配备了专门的视觉解码器,包含20亿参数,用于高质量的视觉生成。能根据文本指令生成图像,在自回归过程中逐步构建图像内容。
- 多模态任务的广泛适用性:VARGPT在多个视觉中心的基准测试中表现优于其他模型,能自然地支持指令到图像的合成,适用于多种视觉-语言任务。
VARGPT的技术原理
- 统一的自回归框架:VARGPT将视觉理解和生成任务统一在一个自回归框架内。对于视觉理解,模型采用next-token预测范式,即通过预测下一个文本标记来完成视觉问答和推理任务;对于视觉生成,采用next-scale预测范式,逐步预测图像的下一个尺度信息。使模型能在单一框架内高效处理视觉和语言任务。
- 视觉解码器与特征映射:VARGPT包含一个专门的视觉解码器,拥有20亿参数,用于高质量的视觉生成。解码器由30个Transformer块组成,每个块包含30个注意力头,宽度为1920,采用自适应归一化(AdaLN)。
- 多尺度标记化:为了支持视觉生成,VARGPT使用了多尺度变分自编码器(VAE)架构,类似于VAR模型。架构通过多尺度量化方案将图像分解为不同尺度的标记,词汇表大小为4090,训练数据为OpenImages数据集。
- 混合模态输入与输出:VARGPT支持文本和图像的混合模态输入,能同时输出文本和图像。模型通过特殊的标记和提示格式,灵活地在文本和视觉模态之间切换,实现混合模态生成。
- 三阶段训练策略:
- 预训练阶段:学习文本和视觉特征之间的映射关系。
- 混合视觉指令微调阶段:通过构造视觉生成指令数据集,结合多轮对话指令数据集进行混合训练,增强模型在视觉问答和指令到图像合成任务中的能力。
如何运行 VARGPT
1. 环境配置
首先,设置环境:
pip3 install -r requirements.txt
2. 多模态理解
执行以下命令进行多模态理解的推理演示:
python3 inference/understanding_vargpt.py
或者执行以下代码:
import requests
from PIL import Image
import torch
from transformers import AutoProcessor, AutoTokenizer
from vargpt_llava.modeling_vargpt_llava import VARGPTLlavaForConditionalGeneration
from vargpt_llava.prepare_vargpt_llava import prepare_vargpt_llava
from vargpt_llava.processing_vargpt_llava import VARGPTLlavaProcessor
from patching_utils.patching import patching
model_id = "VARGPT-family/VARGPT_LLaVA-v1"
prepare_vargpt_llava(model_id)
model = VARGPTLlavaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.float32,
low_cpu_mem_usage=True,
).to(0)
patching(model)
tokenizer = AutoTokenizer.from_pretrained(model_id)
processor = VARGPTLlavaProcessor.from_pretrained(model_id)
conversation = [
{
"role": "user",
"content": [
{"type": "text", "text": "Please explain the meme in detail."},
{"type": "image"},
],
},
]
prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
image_file = "./assets/llava_bench_demo.png"
print(prompt)
raw_image = Image.open(image_file)
inputs = processor(images=raw_image, text=prompt, return_tensors='pt').to(0, torch.float32)
output = model.generate(
**inputs,
max_new_tokens=2048,
do_sample=False)
print(processor.decode(output[0], skip_special_tokens=True))
3. 文本到图像生成
执行以下命令进行文本到图像生成的推理演示:
python3 inference/generation_vargpt.py
或者执行以下代码:
import requests
from PIL import Image
import torch
from transformers import AutoProcessor, AutoTokenizer
from vargpt_llava.modeling_vargpt_llava import VARGPTLlavaForConditionalGeneration
from vargpt_llava.prepare_vargpt_llava import prepare_vargpt_llava
from vargpt_llava.processing_vargpt_llava import VARGPTLlavaProcessor
from patching_utils.patching import patching
model_id = "VARGPT-family/VARGPT_LLaVA-v1"
prepare_vargpt_llava(model_id)
model = VARGPTLlavaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.float32,
low_cpu_mem_usage=True,
).to(0)
patching(model)
tokenizer = AutoTokenizer.from_pretrained(model_id)
processor = VARGPTLlavaProcessor.from_pretrained(model_id)
conversation = [
{
"role": "user",
"content": [
{"type": "text", "text": "Please design a drawing of a butterfly on a flower."},
],
},
]
prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
print(prompt)
inputs = processor(text=prompt, return_tensors='pt').to(0, torch.float32)
model._IMAGE_GEN_PATH = "output.png"
output = model.generate(
**inputs,
max_new_tokens=2048,
do_sample=False)
print(processor.decode(output[0], skip_special_tokens=True))
资源
- 项目官网:https://vargpt-1.github.io/
- GitHub 仓库:https://github.com/VARGPT-family/VARGPT
- HuggingFace 仓库:https://huggingface.co/VARGPT-family/VARGPT_LLaVA-v1
- arXiv 技术论文:https://arxiv.org/pdf/2501.12327
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发非常感兴趣,我会每日分享大模型与 AI 领域的最新开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术,欢迎关注我哦!
微信公众号|搜一搜:蚝油菜花