Chrome中的GPU加速合成
原文链接:https://www.chromium.org/developers/design-documents/gpu-accelerated-compositing-in-chrome
简介:为什么要进行硬件合成?
传统上,Web浏览器完全依靠CPU来呈现网页内容。如今,即使是最小的设备,功能强大的GPU也已成为不可或缺的一部分,人们的注意力已转移到寻找更有效地使用此基础硬件以实现更好的性能和节能的方法。使用GPU合成网页内容可以大大提高速度。
硬件合成的好处有以下三种:
- 在涉及大量像素的绘图和合成操作中,在GPU上合成页面层可以获得比CPU更高的效率(在速度和功耗方面)。硬件专门针对这些类型的工作负载而设计。
- 对于GPU中已经存在的内容(例如加速视频,Canvas2D或WebGL),无需进行昂贵的回读。
- CPU和GPU之间的并行性可以同时运行以创建有效的图形管线
第1部分:Blink渲染基础知识
Blink渲染引擎的源代码庞大,复杂,几乎没有文档记录。为了了解GPU加速在Chrome中的工作原理,首先必须了解Blink呈现页面的基本结构。
节点和DOM树
在Blink中,网页的内容在内部存储为称为DOM树的Node对象树。页面上的每个HTML元素以及元素之间出现的文本都与一个节点相关联。 DOM树的顶级节点始终是文档节点。
从节点到RenderObjects
DOM树中产生可视输出的每个节点都有一个对应的RenderObject。 RenderObject存储在称为Render Tree的并行树结构中。 RenderObject知道如何在显示表面上绘制Node的内容。通过向GraphicsContext发出必要的绘制调用来实现。 GraphicsContext负责将像素写入位图,最终将其显示在屏幕上。在Chrome中,GraphicsContext包装了我们的2D图形库Skia。
传统上,大多数GraphicsContext调用都变成了对SkCanvas或SkPlatformCanvas的调用,即立即绘制到软件位图中。但是为了将绘画从主线程上移开,现在将这些命令记录到SkPicture中。 SkPicture是可序列化的数据结构,可以捕获和随后重播命令,类似于显示列表。
从RenderObjects到RenderLayers
每个RenderObject都直接或通过祖先RenderObject间接与RenderLayer关联。
共享相同坐标空间(例如,受相同CSS转换影响)的RenderObject通常属于同一RenderLayer。存在RenderLayers以便按正确的顺序组合页面的元素以正确显示重叠的内容,半透明的元素等。有许多条件会触发为特定的RenderObject创建新的RenderLayer,如RenderBoxModelObject :: requiresLayer()并为某些派生类覆盖。保证创建RenderLayer的RenderObject的常见情况:
- 它是页面的根对象
- 它具有明确的CSS位置属性(相对,绝对或转换)
- 它是透明的
- 有溢出,alpha蒙版或反射
- 有一个CSS过滤器
- 对应具有3D(WebGL)上下文或加速2D上下文的
- 对应于
注意,RenderObjects和RenderLayers之间没有一一对应的关系。特定的RenderObject与为其创建的RenderLayer(如果有)关联,或者与具有一个的第一个祖先的RenderLayer关联。
RenderLayers也形成树层次结构。根节点是与页面中根元素相对应的RenderLayer,并且每个节点的后代都是可见地包含在父层中的层。
Layer Squashing
就内存和其他资源而言,GraphicsLayers可能会很昂贵(例如,某些关键操作的CPU时间复杂度与GraphicsLayer树的大小成正比)。可以为RenderLayers创建许多其他图层,这些图层将RenderLayer与它自己的底面重叠,这可能会很昂贵。
我们将固有的合成原因(例如,具有3D转换的图层)称为“直接”合成原因。为了防止由于直接合成原因而在图层上放置许多元素时发生“图层爆炸”,Blink会将多个RenderLayers与直接合成原因RenderLayer重叠,然后将它们“挤压”到单个后备存储中。这样可以防止重叠引起的层爆炸。可以在此演示文稿中找到更详细的激励层压缩,以及在此演示文稿中可以找到有关RenderLayers和合成层之间的代码的更多详细信息;两者都是截至2014年1月的最新版本,尽管该法规在2014年发生了重大变化。
从GraphicsLayers到WebLayers再到CC层
在我们开始使用Chrome的合成器实现之前,只需要再进行几层抽象即可! GraphicsLayers可以通过一个或多个Web * Layers表示其内容。这些是WebKit端口需要实现的接口。有关诸如WebContentsLayer.h或WebScrollbarLayer.h之类的界面,请参见Blink的public / platform目录。 Chrome的实现位于src / webkit / renderer / compositor_bindings中,这些实现使用Chrome合成器层类型实现抽象的Web * Layer接口。
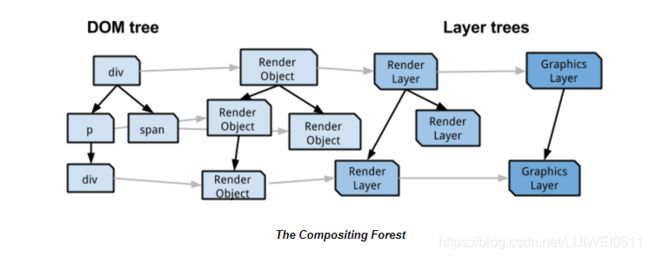
Putting it Together: The Compositing Forest
总而言之,概念上存在四个并行的树结构,它们的呈现目的略有不同:
- DOM树,这是我们的基本保留模型
- RenderObject树,其中1:1映射到DOM树的可见节点。 RenderObjects知道如何绘制其相应的DOM节点。
- RenderLayer树,由映射到RenderObject树上的RenderObject的RenderLayers组成。映射是多对一的,因为每个RenderObject要么与其自己的RenderLayer关联,要么与其第一祖先的RenderLayer关联。 RenderLayer树保留层之间的z顺序。
- GraphicsLayer树,映射GraphicsLayers一对多的RenderLayers。
每个GraphicsLayer都有在Chrome中使用Chrome合成器层实现的Web * Layers。合成器知道如何操作这些最终“ cc层”(cc = Chrome合成器)。
从本文开始,“层”将指代通用cc层,因为对于硬件合成而言,这些是最有趣的-但不要上当,在其他人说“层”时,它们可能是指任何以上构造.
现在,我们已经简要地介绍了将DOM链接到合成器的Blink数据结构,我们已经准备好认真研究合成器本身。
第2部分:The Compositor 合成器
Chrome的合成器是一个软件库,用于管理GraphicsLayer树和协调框架生命周期。它的代码位于Blink之外的src / cc目录中。
介绍合成器
回想一下,渲染分为两个阶段:首先进行绘制,然后进行合成。这允许合成器在每个合成层的基础上执行其他工作。例如,合成器负责在合成之前对每个合成层的位图应用必要的转换(由图层的CSS转换属性指定)。此外,由于层的绘画与合成是分离的,因此使这些层之一无效只会导致仅重新绘画该层的内容并进行合成。每当浏览器需要制作新框架时,合成器都会绘制。注意这个(令人困惑的)术语区别:绘图是将图层组合成最终屏幕图像的合成器;而绘画则是层的支持(具有软件光栅化的位图;具有硬件光栅化的纹理)。
还有GPU吗?
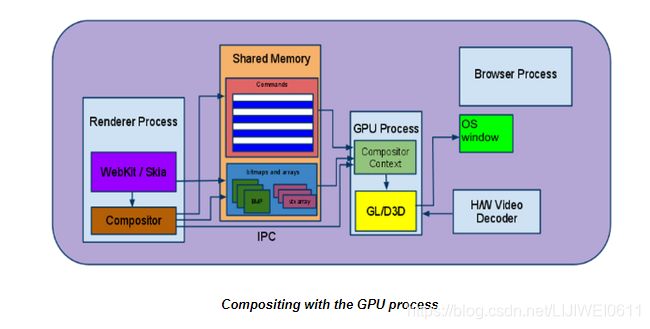
那么GPU如何发挥作用呢?合成器可以使用GPU来执行其绘制步骤。这与旧的软件渲染模型有很大的不同,在旧的软件渲染模型中,Renderer进程(通过IPC和共享内存)将带有页面内容的位图传递到Browser进程进行显示(有关更多信息,请参见“旧版软件渲染路径”附录)。如何运作)。
在硬件加速架构中,合成是通过调用特定于平台的3D API(Windows上为D3D;其他任何地方为GL)在GPU上进行的。渲染器的合成器实质上是使用GPU将页面的矩形区域(即根据图层树的转换层次结构相对于视口定位的所有那些合成层)绘制为单个位图,即最终页面图像。
建筑插曲:GPU进程
在进一步研究合成器生成的GPU命令之前,了解renderer进程如何将所有命令发布给GPU至关重要。在Chrome的多进程模型中,我们有专门的流程来执行此任务:GPU进程。 GPU进程的存在主要是出于安全原因。请注意,Android是一个例外,其中Chrome使用进程内GPU实现,该实现在浏览器进程中作为线程运行。否则,Android上的GPU线程的行为与其他平台上的GPU进程相同。受其沙箱限制,Renderer进程(包含Blink和cc的实例)无法直接向操作系统(GL / D3D)提供的3D API发出调用。因此,我们使用单独的进程来访问设备。我们称此过程为GPU进程。 GPU进程经过专门设计,可从Renderer沙箱或更为严格的Native Client“ jail”中访问系统的3D API。它通过客户端-服务器模型工作,如下所示:客户端(在Renderer或NaCl模块中运行的代码)不是直接向系统API发出调用,而是对其进行序列化,然后将其放入位于自身和服务器进程之间共享的内存中的环形缓冲区(命令缓冲区)中。服务器(运行在限制较少的沙箱中的GPU进程,允许访问平台的3D API)从共享内存中提取序列化的命令,解析它们并执行适当的图形调用。
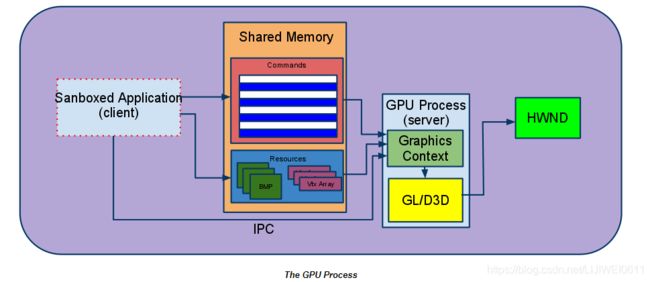
命令缓冲区
GPU进程接受的命令在GL ES 2.0 API之后进行了紧密模式化(例如,有一个命令与glClear相对应,一个与glDrawArrays相对应,等等)。由于大多数GL调用都没有返回值,因此客户端和服务器几乎可以异步工作,从而使性能开销相当低。客户端和服务器之间的任何必要同步(例如客户端通知服务器还有其他工作要做)都通过IPC机制处理。
从客户端的角度来看,应用程序可以选择将命令直接写入命令缓冲区,也可以通过我们提供的客户端库使用GL ES 2.0 API,该库可以处理后台的序列化。为了方便起见,合成器和WebGL当前都使用GL ES客户端库。在服务器端,通过命令缓冲区接收的命令将通过ANGLE转换为对桌面OpenGL或Direct3D的调用。
资源共享与同步
除了为命令缓冲区提供存储外,Chrome还使用共享内存在客户端和服务器之间传递较大的资源,例如纹理位图,顶点数组等。有关命令格式和数据传输的更多信息,请参见命令缓冲区文档。
另一种称为邮箱的构造提供了一种在命令缓冲区之间共享纹理并管理其生存期的方法。邮箱是一个简单的字符串标识符,可以将其附加(使用)到任何命令缓冲区的本地纹理ID,然后通过该纹理ID别名进行访问。以这种方式附加的每个纹理id都在基础真实纹理上保留了一个引用,并且通过删除本地纹理id释放了所有引用之后,真实纹理也会被破坏。
同步点用于在要通过邮箱共享纹理的命令缓冲区之间提供非阻塞同步。在命令缓冲区A上插入一个同步点,然后在命令缓冲区B上的同步点上“等待”可确保您随后在B上插入的命令不会在同步点之前在A上插入的命令之前运行。
命令缓冲区多路复用
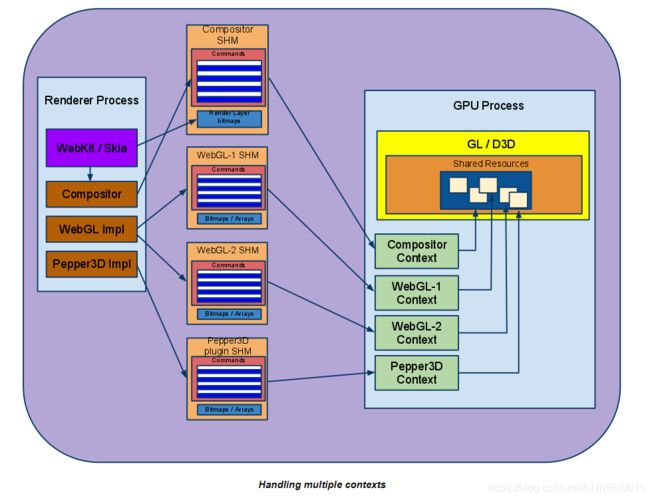
目前,Chrome中 浏览器实例使用一个GPU进程处理来自所有渲染器进程和任何插件进程的请求。 GPU进程可以在多个命令缓冲区之间进行多路复用,每个命令缓冲区都与其自己的呈现上下文相关联。
每个渲染器可以具有多个GL来源,例如WebGL Canvas元素直接创建GL命令流。直接在GPU上创建其内容的图层的组成如下:代替直接渲染到后缓冲区中,它们渲染成纹理(使用帧缓冲区对象),该纹理由合成器上下文在渲染该GraphicsLayer时捕获并使用。重要的是要注意,为了使合成器的GL上下文能够访问由屏幕外GL上下文(即,用于其他GraphicsLayers的FBO的GL上下文)生成的纹理,GPU过程使用的所有GL上下文都必须创建为他们共享资源。
产生的架构如下所示:
总结:
GPU流程体系结构具有以下优点:
- 安全性:大部分渲染逻辑仍保留在沙盒renderer进程中,并且对平台3D API的访问仅限于GPU进程。
- 稳健性:GPU进程崩溃(例如,由于错误的驱动程序导致)不会导致浏览器崩溃。
- 统一性:无论平台如何,都可以将OpenGL ES 2.0标准化为浏览器的呈现API,从而可以跨Chrome的所有OS端口轻松维护单个代码库。
- 并行性:渲染器可以快速将命令发布到命令缓冲区中,并返回到CPU密集型渲染活动,而由GPU进程处理。借助此管道,我们可以充分利用多核计算机上的两个进程以及GPU和CPU。
顺便说一句,我们可以回到解释渲染器的合成器如何生成GL命令和资源的方式。
第3部分:线程合成器
合成器在GL ES 2.0客户端库的顶部实现,该客户端库代理对GPU进程的图形调用(使用上述方法)。当页面通过合成器渲染时,其所有像素均通过GPU进程直接绘制(记住,绘制!=绘画)到窗口的后缓冲区中。
合成器的体系结构随着时间的推移不断发展:最初它位于Renderer的主线程中,然后移至其自己的线程(所谓的合成器线程),然后在绘制颜料时承担了其他责任(编排)(所谓的“侧面绘画”) )。本文档将重点关注最新版本。有关可能仍在使用较旧版本的信息,请参阅GPU架构路线图。
从理论上讲,线程合成器的基本任务是从主线程中获取足够的信息,以响应将来的用户输入而独立生成帧,即使主线程很忙并且无法请求其他数据。实际上,这实际上意味着它会为视口当前位置周围区域中的图层区域复制cc图层树和SkPicture记录。
录制:从Blink的角度绘画
兴趣区域是视口周围记录SkPictures的区域。当DOM更改时,例如因为某些元素的样式现在与之前的主线程框架不同,并且已经失效,所以Blink将感兴趣区域内无效层的区域绘制到SkPicture支持的GraphicsContext中。实际上并不会产生新像素,而是会产生产生这些新像素所需的Skia命令的显示列表。该显示列表将在以后由合成者酌情使用,以生成新的像素。
提交:移交给合成线程
线程合成器的key属性是对主线程状态副本的操作,因此它可以生成帧而无需向主线程询问任何内容。因此,线程化合成器有两个方面:主线程侧和(俗称的)“ impl”侧,即合成器线程的一半。主线程有一个LayerTreeHost,它是它的层树副本,而impl线程有一个LayerTreeHostImpl,它是它的层树副本。始终遵循类似的命名约定。
从概念上讲,这两层树是完全分开的,并且可以使用合成器(impl)线程的副本来生成帧,而无需与主线程进行任何交互。这意味着主线程可能正在忙于运行JavaScript,并且合成器仍可以在GPU上重新绘制以前提交的内容而不会中断。
为了产生有趣的新帧,合成器线程需要知道如何修改其状态(例如,响应于滚动之类的事件来更新图层变换)。因此,一些输入事件(如滚动)首先从浏览器进程转发到合成器,再从那里转发到渲染器主线程。通过在其控制下的输入和输出,线程合成器可以保证对用户输入的视觉响应。除了滚动之外,该合成器还可以执行其他任何页面更新,而无需要求Blink重新绘制任何内容。到目前为止,CSS动画和CSS过滤器是其他主要的由合成器驱动的页面更新。
两层树通过一系列消息(称为提交)保持同步,这些消息由合成器的调度程序(在cc / trees / thread_proxy.cc中)介导。提交将主线程的世界状态转移到合成器线程(包括更新的图层树,任何新的SkPicture记录等),从而阻塞了主线程,因此可以进行此同步。这是主线程参与特定框架生产的最后一步。
在自己的线程中运行合成器可以使合成器的层树副本在不涉及主线程的情况下更新层变换层次结构,但是最终主线程最终需要例如以及滚动偏移信息(例如,JavaScript可以知道视口滚动到的位置)。因此,提交还负责将任何复合线程层树更新应用于主线程树和其他一些任务。
除了有趣的是,此体系结构是JavaScript触摸事件处理程序阻止合成滚动的原因,而滚动事件处理程序则不能。 JavaScript可以在触摸事件上调用preventDefault(),但不能在滚动事件上调用。因此,合成器必须先询问JavaScript(在主线程上运行)是否要取消传入的触摸事件,才能滚动页面。另一方面,滚动事件是无法避免的,而是异步传递给JavaScript的;因此,无论主线程是否立即处理滚动事件,合成器线程都可以立即开始滚动。
树激活
当合成器线程从主线程获取新的图层树时,它将检查该新树以查看哪些区域无效并重新栅格化这些图层。在此期间,活动树仍然是合成器线程先前拥有的旧层树,而挂起的树是其内容正在栅格化的新层树。
为了保持所显示内容的一致性,仅当待处理树的可见(即,在视口内)高分辨率内容被完全光栅化时才激活。从当前活动树交换到现在就绪的挂起树称为激活。等待栅格内容准备就绪的最终效果是,用户通常可以看到至少一些内容,但是该内容可能是陈旧的。如果没有可用的内容,Chrome将显示带有GL着色器的空白或棋盘图案。
请务必注意,由于Chrome仅记录感兴趣区域内图层区域的SkPictures,因此甚至可以滚动到活动树的栅格区域。如果用户向着未记录区域滚动,则合成器将要求主线程记录并提交其他内容,但是如果该新内容无法被记录,提交和栅格化以及时激活,则用户将滚动到棋盘格区域。
为了减轻棋盘格,Chrome还可以在高分辨率之前快速光栅化待处理树的低分辨率内容。如果视口中只有低分辨率内容的待处理树比当前屏幕上显示的要好(例如,待处理的活动树根本没有为当前视口栅格化的内容),则待激活的树将被激活。切片管理器(在下一节中说明)决定何时栅格化什么内容。
这种架构将光栅化与其余帧制作流程隔离开来。它启用了多种可改善图形系统响应能力的技术。图像解码和调整大小操作是异步执行的,这些操作以前是在绘制过程中执行的昂贵的主线程操作。本文档前面提到的异步纹理上载系统也已在impl-side绘画中引入。
平铺
光栅化页面上每一层的全部都是浪费CPU时间(用于绘画操作)和内存(用于该层所需的任何软件位图的RAM;用于纹理存储的VRAM)。合成器没有光栅化整个页面,而是将大多数Web内容层分解为图块,并逐个瓦片化层。
Web内容层图块会根据许多因素进行启发式优先排序,这些因素包括图块与视口的接近程度以及其到达屏幕的估计时间。然后,将GPU内存根据其优先级分配给图块,并从SkPicture记录中栅格化图块,以按优先级顺序填充可用的内存预算。当前(2014年5月)正在重新设计切片优先级的具体方法;有关更多信息,请参见图块优先级设计文档。
请注意,对于内容已经驻留在GPU上的图层类型(例如加速视频或WebGL),平铺不是必需的(出于好奇,图层类型在cc / layers目录中实现)。
栅格化:从cc / Skia的角度绘画
合成器线程上的SkPicture记录通过以下两种方式之一转换为GPU上的位图:由Skia的软件光栅化器绘制为位图,然后作为纹理上传到GPU,或由Skia的OpenGL后端(Ganesh)直接绘制为纹理GPU。
对于经过Ganesh栅格化的图层,将使用Ganesh回放SkPicture,并将生成的GL命令流通过命令缓冲区传递给GPU进程。当合成器决定栅格化任何图块时,就会立即生成GL命令,并且将图块捆绑在一起以避免GPU上的图块化栅格化产生过多开销。有关此方法的更多信息,请参见GPU加速栅格化设计文档。
对于软件栅格化的图层,绘画将目标指定为渲染器进程和GPU进程之间共享的内存中的位图。位图通过上述资源传输机制传递给GPU处理。由于软件光栅化可能非常昂贵,因此这种光栅化不会在合成器线程本身中发生(它可能会阻止为活动树绘制新框架),而是在合成器光栅工作线程中发生。可以使用多个栅格工作线程来加速软件栅格化;每个工作人员从优先的图块队列的最前面拉。完成的图块作为纹理上传到GPU。
在内存带宽受限的平台上,位图的纹理上载是一个不小的瓶颈。这阻碍了软件光栅化的层的性能,并且继续阻碍了硬件光栅化器(例如,对于图像数据或CPU渲染的掩模)所必需的位图的上传。 Chrome过去有多种不同的纹理上载机制,但是最成功的是异步上载器,该上载器在GPU进程的工作线程中执行上载(对于Android,则在Browser进程中的其他线程中上载)。防止其他操作必须阻止可能冗长的纹理上载。
完全消除纹理上传问题的一种方法是在暴露此类原语的统一内存体系结构设备上,在CPU和GPU之间共享零拷贝缓冲区。 Chrome当前不使用此构造,但将来会使用。有关更多信息,请参见GpuMemoryBuffer设计文档。
另请注意,在使用GPU进行栅格化时,可能会采用第三种方法来绘制内容:在绘制时将每一层的内容直接栅格化到后缓冲区中,而不是预先栅格化。这具有节省内存(无中间纹理)和一些性能改进(在绘制时将纹理的副本保存到后缓冲区)的优点,但是当纹理有效地缓存图层内容时(由于现在需要,所以它会降低性能)每帧重新绘制一次)。截至2014年5月,尚未实现这种“直接到后缓冲”或“直接Ganesh”模式,但有关其他注意事项,请参阅GPU栅格化设计文档。
在GPU,平铺和四边形上绘图
一旦填充了所有纹理,渲染页面内容就简单地完成了对图层层次结构的深度优先遍历并发出GL命令以将每个图层的纹理绘制到帧缓冲区中。
在屏幕上绘制图层实际上是绘制每个图块的问题。瓷砖以四边形(简单的4边形,即矩形;请参见cc / quads)表示,并填充了给定图层内容的子区域。合成器生成四边形和一组渲染通道(渲染通道是保存四边形列表的简单数据结构)。用于绘制的实际GL命令与四边形分开生成(请参见cc / output / gl_renderer.cc)。这是从Quad实现中抽象出来的,因此可以为合成器编写非GL后端(唯一重要的非GL实现是软件合成器,稍后介绍)。或多或少地绘制四边形,相当于为每个渲染过程设置视口,然后为该渲染过程设置变换并在渲染过程的四边形列表中绘制每个四边形。
请注意,进行深度优先遍历可确保cc层正确进行z排序,并且当某个层的RenderObjects遍历时,可通过顺序遍历RenderObject树来保证与该cc层关联的潜在多个RenderLayers的z排序被绘。
各种比例因子
impl-side绘画的一个显着优点是,合成器可以以任意比例因子重新渲染现有的SkPictures。这在两个主要情况下很有用:捏缩放并在快速扫射期间生成低分辨率的图块。
合成器将拦截输入事件以进行捏合/缩放,并在GPU上适当缩放已栅格化的图块,但是在发生这种情况时,它也会以更合适的目标分辨率进行栅格化。每当新的图块准备就绪(栅格化和上载)时,都可以通过激活挂起的树来交换它们,从而提高缩放/缩放屏幕的分辨率(即使缩放尚未完成)。
在使用软件进行栅格化时,合成器还会尝试快速生成低分辨率的图块(通常更便宜地绘制),如果尚未准备好高分辨率图块,则在滚动期间显示它们。这就是为什么某些页面在快速滚动过程中看起来模糊的原因-合成器在屏幕上显示低分辨率图块,而高分辨率图块栅格化。
附录
附录A:浏览器合成
本文档主要介绍Renderer进程中用于显示Web内容的活动。 Chrome的用户界面也使用了相同的基础合成基础架构,值得注意的是brower的参与程度。
浏览器与Aura / Ash合成
Chrome&ChromeOS具有由Ash和Aura组合而成的复合窗口管理器(Ash是窗口管理器本身,而Aura提供了诸如窗口和输入事件之类的基本原语)。窗口管理器Ash仅在ChromeOS和Win8的Metro模式下使用;在Linux和非Metro Windows上,Aura窗口包装了本机OS窗口。 Aura使用cc来制作Aura窗口,而Views使用cc到Aura来合成窗口的浏览器UI中的不同元素。尽管有些视图也可以弹出到自己的层中,但大多数“光环”窗口只有一层。这些反映了Blink使用cc来组合Web内容层的方式。有关Aura的更多信息,请参见Aura设计文档索引。
Übercompositor
最初,Blink会将Renderer的所有图层(即Web内容区域的图层)合成为纹理,然后在浏览器进程中通过cc的第二个副本将该纹理与浏览器UI的其余层进行合成。这很简单,但主要缺点是每帧都会产生视口大小的额外副本(因为内容层首先被合成为纹理,然后在浏览器合成器绘制时会复制该纹理)。
Übercompositor可以在一次绘图过程中完成浏览器UI和渲染器层的所有合成。渲染器没有将其四边形本身绘制,而是将所有四角形交给了浏览器,然后在浏览器合成器的层树中DelegatedRendererLayer的位置绘制了它们。有关此主题的更多详细信息,请参见übercompositor设计文档。
附录B:软件合成器
在某些情况下,硬件合成是不可行的,例如如果设备的图形驱动程序被列入黑名单,或者设备完全缺少GPU。对于这些情况,是GL渲染器的另一种实现,称为SoftwareRenderer(请参见src / cc / output / software_renderer)。当OutputSurface(请参见src / cc / output / output_surface)ContextProvider不可用时,许多其他地方(RasterWorkerPool,ResourceProvider等)也需要它们自己的软件后备。总之,在不使用GPU的情况下运行时,Chrome在软件上具有大致相同的功能,但在实现方面存在一些关键差异:
- 与其将四边形作为纹理上传到GPU,不如将它们留在系统内存中并作为共享内存穿梭在周围
- 该软件渲染器没有使用GL将内容纹理图块复制到后缓冲中,而是使用Skia的软件光栅化器来执行复制(以及执行任何必要的矩阵数学和剪切操作)
这意味着3D转换和复合CSS过滤器之类的操作可以与软件渲染器“一起使用”,而本质上依赖于GL(例如WebGL)的Web内容则不需要。对于WebGL的软件渲染,Chrome使用了SwiftGLder(一种软件GL光栅化器)。
附录C:Grafix 4 N00bs词汇表
- bitmap: a buffer of pixel values in memory (main memory or the GPU’s video RAM)
- texture: a bitmap meant to be applied to a 3D model on the GPU
- texture quad: a texture applied to a very simple model: a four-pointed polygon, e.g. a rectangle. Useful when all you want is to display the texture as a flat rectangular surface, potentially translated (either in 2D or 3D), which is exactly what we do when compositing.
- invalidation: region of the document marked dirty, usually meaning it requires repainting. The style system has a similar notion of invalidation, so style can be dirtied too, but most commonly this refers to a region needing repainting.
- painting: in our terms, the phase of rendering where RenderObjects make calls into the GraphicsContext API to make a visual representation of themselves
- rasterization: in our terms, the phase of rendering where the bitmaps backing up RenderLayers are filled. This can occur immediately as GraphicsContext calls are by the RenderObjects, or it can occur later if we’re using SkPicture record for painting and SkPicture playback for rasterization.
- compositing: in our terms, the phase of rendering that combines RenderLayer’s textures into a final screen image
- drawing: in our terms, the phase of rendering that actually puts pixels onto the screen (i.e. puts the final screen image onto the screen).
- backbuffer: when double-buffering, the screen buffer that’s rendered into, not the one that’s currently being displayed
- frontbuffer: when double-buffering, the screen buffer that’s currently being displayed, not the one that’s currently being rendered into
- swapbuffers: switching the front and back buffers
- Frame Buffer Object: OpenGL term for a texture that can be rendered to off-screen as if it were a normal screen buffer (e.g. the backbuffer). Useful for us because we want to be able to render to textures and then composite these textures; with FBOs we can pretend to give e.g. WebGL its own frame and it need not worry about anything else going on on the page.
- damage: the area of the screen that has been “dirtied” by user interaction or programmatic changes (e.g. JavaScript changing styles). This is the area of the screen that needs to be re-painted when updating.
- retained mode: a rendering method where the graphics system maintains a complete model of the objects to be rendered. The web platform is retained in that the DOM is the model, and the platform (i.e. the browser) keeps track of the state of the DOM and its API (i.e. JavaScript’s access to the DOM) can be used to modify it or query the current state of it, but the browser can render from the model at any time without any instruction from JavaScript.
- immediate mode: a rendering method where the graphics system doesn’t keep track of the overall scene state but rather immediately executes any commands given to it and forgets about them. To redraw the whole scene all commands need to be re-issued. Direct3D is immediate mode, as is Canvas2D.
- context virtualization: The GPU process does not necessarily create an actual driver-level GL context for a given command buffer client. It can also have a shared real context for multiple clients and restore the GL state to the expected state for a given client when it parses its GL commands -- we refer to this shadowed state as a “virtual context”. This is used on Android to work around bugs and performance problems with certain drivers (slow GL context switches, synchronization issues with FBO rendering across multiple contexts, and crashes when using share groups). Chrome enables context virtualization on a subset of drivers via the GPU blacklist file.