视觉中的transformer:ViT
《》
摘要
transformer已经是NLP的标准。但是在cv领域用的很少,视觉里一般是和cnn一起用或者把某些conv替换成transformer(整体还是CNN)
本篇文章证明纯的transformer直接在图片分类上也做得很好:在大量数据集上进行预训练的前提上,迁移到小数据集(作者说ImageNet是小数据集-_-)上也很好。
Intro
启发
现在NLP里的transformer都是在大量数据集上进行预训练,然后迁移到小数据集(BERT),现在已经可以训练千亿级别的参数了(GPT3),甚至现在还没有出现性能饱和过拟合的问题
transformer用到视觉里的难处
自注意力要求每个元素需要和其他元素运算,N^2的,复杂度太高
如何把图片编成seq,如果直接拉长太大
(比如分类任务224*224图片就50k多了,BERT的100倍,检测和分割的输入更大)
现在的做法:
-
把某些conv替换成transformer,相当于把特征图输入transformer来降低长度
-
不用整张图,用某些窗口,类似卷积。
-
轴自注意力:把2D的图片换成两个1D向量(长和宽)(类似TTF?),然后对向量进行自注意力
这些自注意力都很特殊,也没有硬件加速,导致现在的模型很小,效果不好
我们想做的
直接用一个纯的标准的transformer,直接用到视觉领域,那就要解决很长的seq的问题,解决方法:
把每个图片(224)拆成16X16的patch,那么图片W=H=224/16=14,如此seq长度就是14X14=196(对普通transformer是可以接受的)
把每个patch用FC连起来,然后输入trans(每个patch相当于一个单词)
然后使用有监督的训练,如果不加比较强的约束,是不如CNN的,原因:缺少CNN有的归纳偏置
归纳偏置:一种假设,一种先验知识
比如在CNN上有的两个归纳偏置:
- locality本地行:相邻的像素会有相邻的特征(如桌子和椅子经常在一起)
- translation equivalence 平移同变性:F(Gx)=G(Fx)(F可以理解为卷积G可以理解为平移,先卷积还是先平移结果是一样的)
相关工作
在NLP里的应用,先大数据集预训练再小数据微调(BERT和GPT)
方法
模型结构
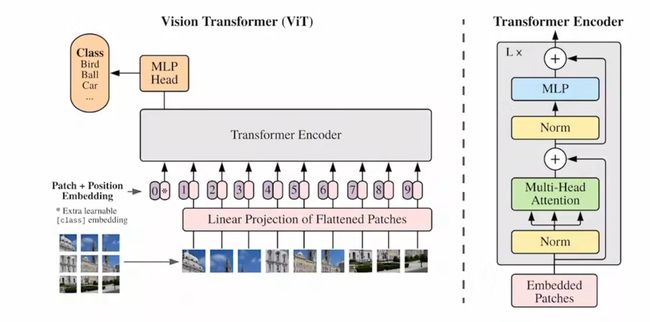
关于编码
图片是一个整体,patch是有顺序的,把patch emb+pos emb作为一个token
上面已经算了,一个224图片分成196个patch,每个是16X16X3(=768)
Linear Projection 其实就是FL,文章用E表示,维度是768(patch的)X768(作者定的),文章用D表示。LP计算:X·D = 196(数量)X768(每个patch)X (768X768)
中间两个维度抵消 => 196X768(经过全连接后有196个token,每个维度是768)
也就是成功的把2D的图片转换成了1D的token
CLS:0号token,特殊字符,class embedding,它能够从其他token中学到有用的东西,作为全局的图片特征。
CLS [Class token]
在BERT中提出,原本用于NLP,用作理解整句特征,在ViT中用于理解图片全局特征。
在传统视觉任领域,如Res50,一般用GAP(Global average pooling 全局平均池化)得到一个向量作为全局特征
Q:为什么不直接用N个token的输出用作特征?
A:可以的。可以吧输出的N个特征做GAP作为总体的特征(文中给出了实验)。但是本文是为了和原始的transformer尽可能的相近,以证明标准的transformer是可以做视觉的。
位置编码
有一个表(196X768大小),每一行就是这个token的pos信息。初始为0,通过反向传播进行学习更新。具体的直接token+pos运算,不改变维度
把CLS+196个token=197个token加上位置编码作为输入(右图粉色,embedded patched)
位置编码方法
1D:1-9编号 2D:横纵坐标 相对编码:用图像块的offset表示
位置编码方式没有大差别(文里给出了实验),但是要有(本文用了1D的,和传统保持一致)
Encoder内部
纬度变化图
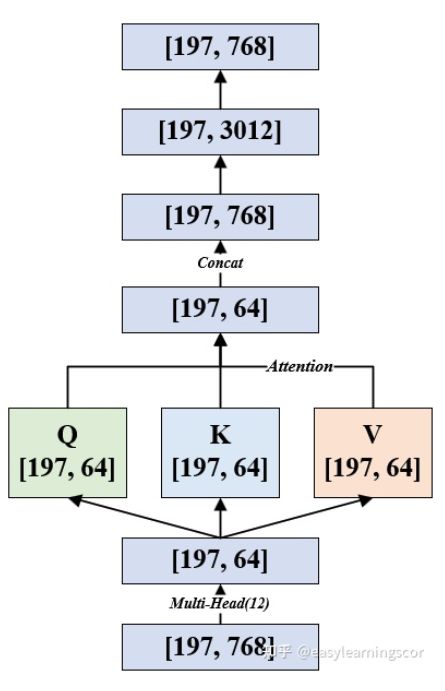
-
197X768的tensor首先进行LN,维度不变
-
然后多头自注意力,每个头形成Q、K、V,每一个都是197X768
ps:如果用的是base版本,有12个头,那么每个头上是197X64,最后再把12个64拼接成768
-
残差
-
LN
-
然后MLP
全连接层+GELU激活函数+Dropout
(这里会把维度先放大(一般是4倍,197X3072),再缩小回去还是768),输出197X768
-
残差
公式总结
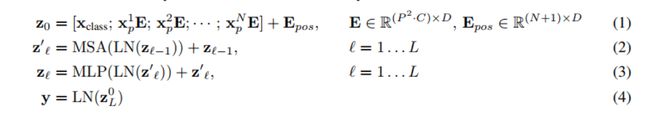
(1)z0是输入=xp是patch, x·E是全连接,xclss是拼接的cls,然后加pos编码
(2)zt本层输出=MSA多头注意力(LN(zt-1是本层输入))+zt-1是残差
(3)类似(2)做MLP
(4)最后LN
高分辨率图像下的微调
在用更大的图时如果还用16的patch,seq长度会增大,但是训练好的位置编码的信息可能失效了,需要对位置编码做一个插值处理
实验
patch越小,训练成本越高
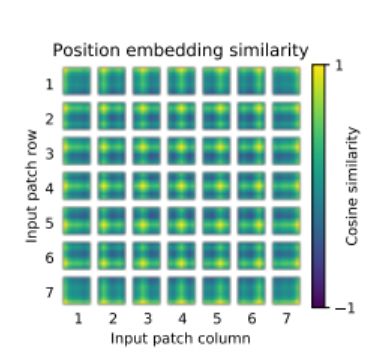
学到了位置关系

学到了全局的特征
结论
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NQjxo8Ab-1680491330854)(C:\Users\zhang\AppData\Roaming\Typora\typora-user-images\image-20230311122236316.png)]
和intro差不多
抛出问题:
- 除了分类,transformer在检测和分割方面如何工作
- 如何用自监督的预训练方式,像NLP那样
参考资料:
https://zhuanlan.zhihu.com/p/498034711
【ViT论文逐段精读【论文精读】】 https://www.bilibili.com/video/BV15P4y137jb/?share_source=copy_web&vd_source=99a5c65ddf3bece3b0e640affd3db506