C++数据结构之哈希表
个人见解:
哈希表又叫做散列表,是一种用空间换取时间的一种数据结构,哈希表本质上是一个数组,通过访问下标来快速获取数据,时间复杂度接近于O(1)。下面介绍一下其存储数据的过程。
首先我们创建一个长度为7的数组
现在有一个数据7需要放到这个数组中,通过除留余数法(用数据除以哈希表长度),
7%7=0,余数即是数据存储在数组中的下标位置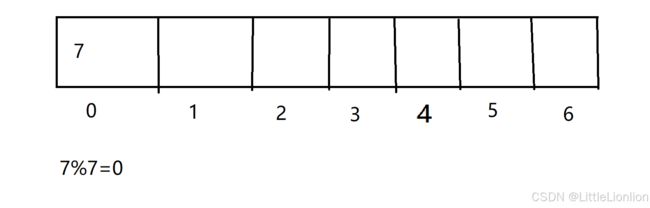
当想要获取数据7时,只需通过哈希函数(将数据进行除留余数并进行访问),获得数据存储的下标位置就可以直接访问到数据7,时间复杂度为0(1)。
现在继续插入几个数据
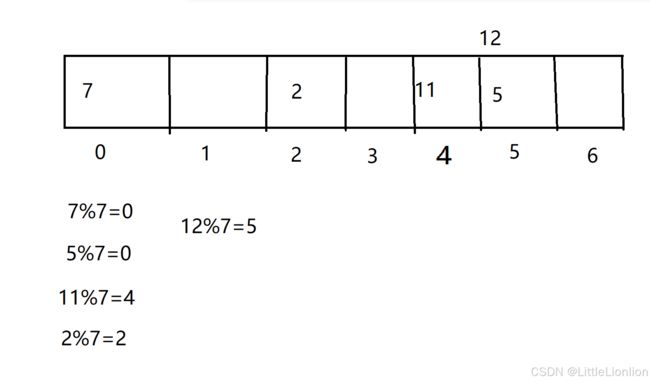
我们会发现当12%7=5,但是数组中下标为5的位置已经被占用了,没地方放了,这时就产生了哈希冲突。面对哈希冲突,我们一般有两种方法,线性探测(开放地址法)和链地址法。
线性探测法:
当产生哈希冲突时,我们会将产生冲突的数据放到数组中的下一个位置(尾部的下个位置为头部)
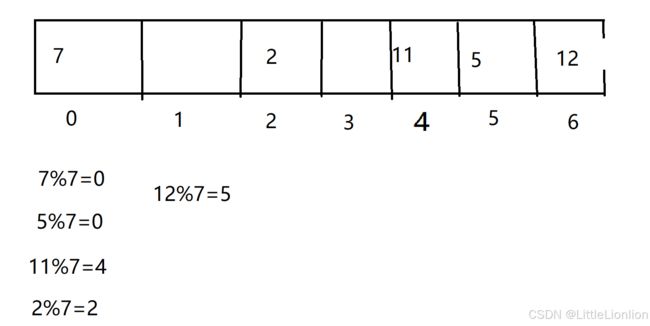
链地址法:
就像糖葫芦串,通过链表的形式将数据链接起来
但是当我们通过这两种方法一直往哈希表中存放数据时,会存在一种最坏情况,即当我们想要找一个数据时需要遍历整个哈希表那么这时的时间复杂度趋近与O(n)。为了避免出现这种情况,我们会
引入一个变量:装载因子,存放数据/哈希表的长度,一般我们规定当装载因子大于0.75的时候,就需要进行扩容,但是扩容以后需要重新哈希(因为5%7=5,但是5%23!=5)
官方说法:
散列表/哈希表的定义:
使关键字和其存储位置满足关系:存储位置=f(关键字),这就是一种新的存储技术————散列技术
散列技术是在记录的存储位置和它的关键字之间建立的对应关系f,使得每个关键字key对应一个存储位置分f(key),在查找时,根据这个确定的对应关系找到给定key的映射f(key),如果待查找集合中存在这个记录,则必定在f(key)这个位置上。
优势:使用与快速查找,时间复杂度为O(n)
劣势:占用空间较大
散列函数(哈希函数):
设计特点:
计算简单(复杂会降低查找时间),散列地址分布均匀(减少哈希冲突)
方法:
直接定址法:取关键字或关键字的某个线性函数值为散列地址。例如:f(key)=a*key+b(a,b为常数)。
数字分析法:使用key的一部分来计算散列码(包括为了减少哈希冲突而进行位移操作,数字叠加操作等)
平方取中法:取关键字key的平方后的中间部分数字作为散列地址
折叠法/随机数法:不做介绍、
除留余数法:f(key)key%p,不仅可以对关键字直接取模,也可以折叠,平方取中法等运算之后取模,p一般为素数
散列冲突处理:
线性探测(开放地址法):f(key)=(key+di)%m,(di=0,1,2,3,4.......m-1)
二次探测:f(key)=(key+di)%m,(di=1^2,-1^2,2^2,-2^2........q^2,-q^2)
q>=m/2
二次探测是对线性探测法的改进,在散列冲突位置的前后都可以查找空位置,di取平方是为了让数据更加散列的存储不会聚集
链地址法:
用链表存储组织产生哈希冲突的key
哈希表的代码实现:
线性探测法的哈希表:
首先用枚举来规定哈希桶的状态
enum State//哈希表中元素的状态
{
STATE_USING,//正在使用
STATE_UNUSE,//从未使用
STATE_DEL,//数据已删除
};接着创建一个结构体用来构建哈希桶(用vector也可以)
//哈希表的节点
struct Bucket
{
//构造函数用来初始化
Bucket(int val=0,State st=STATE_UNUSE):key_(val),state(st){}
int key_;//数据
State state;//数据当前状态
};创建一个类用来构造哈希表
class HashTable
{
public:
HashTable(int size = primes_[0], double loadFactor = 0.75)
{
this->useBucketNum_ = 0;
this->loadFactor = loadFactor;
this->primeIdx_ = 0;
//确保用户传入的size为素数
if (size != primes_[0])
{
for (;primeIdx_< PRIME_SIZE; primeIdx_++)
{
if (primes_[primeIdx_] > size)
{
break;
}
}
//用户传入值过大,调整为最后一个素数
if (primeIdx_ == PRIME_SIZE)
{
primeIdx_--;
}
}
this->tableSize_ = primes_[primeIdx_];
this->table_ = new Bucket[primes_[primeIdx_]];
}
//开始存放数据
bool insert(int key)
{
//考虑扩容
if (useBucketNum_ * 1.0 / tableSize_ > loadFactor)
{
expand();
}
int idx = key % tableSize_;
int i = idx;
do
{
if (table_[i].state != STATE_USING)
{
table_[i].state = STATE_USING;
table_[i].key_ = key;
this->useBucketNum_++;
double factor = useBucketNum_ * 1.0 / tableSize_;
cout << "Factor: " << factor << endl;
return true;
}
i = (i + 1) % tableSize_;
} while (i!=idx);
return false;
}
//删除元素
bool erase(int key)
{
int idx = key % tableSize_;
int i = idx;
do
{
if (table_[i].state ==STATE_USING&&table_[i].key_==key)
{
table_[i].state = STATE_DEL;
this->useBucketNum_--;
}
i = (i + 1) % tableSize_;
} while (i != idx&&table_[i].state!=STATE_UNUSE);
return true;
}
//查找元素
bool find(int key)
{
int idx = key % tableSize_;
int i = idx;
do
{
if (table_[i].state == STATE_USING && table_[i].key_ == key)
{
return true;
}
i = (i + 1) % tableSize_;
} while (i != idx && table_[i].state != STATE_UNUSE);
return false;
}
~HashTable()
{
delete[]table_;
this->table_ = NULL;
}
private:
void expand()
{
++primeIdx_;
if (primeIdx_ == PRIME_SIZE)
{
cout << "HashTable is too large,can not expand anymore!" << endl;
return;
}
Bucket* newtable = new Bucket[primes_[primeIdx_]];
for (int i = 0; i < tableSize_; i++)
{
if (table_[i].state == STATE_USING)
{
int idx = table_[i].key_ % tableSize_;
int j = idx;
do
{
if (table_[j].state != STATE_USING)
{
newtable[j].state = STATE_USING;
newtable[j].key_ = table_[i].key_;
}
j = (j + 1) % primes_[primeIdx_];
} while (j != idx);
}
}
this->tableSize_ = primes_[primeIdx_];
delete[]table_;
this->table_ = newtable;
}
private:
Bucket* table_;//指向动态开辟的哈希表
int tableSize_;//哈希表当前的长度
int useBucketNum_;//已经使用的桶的个数,里面已经装载了几个数据
double loadFactor;//哈希表的装载因子
static const int PRIME_SIZE = 10;//素数表的大小
static int primes_[PRIME_SIZE];//素数表
int primeIdx_;//当前使用的数组下标
};
int HashTable::primes_[PRIME_SIZE] = { 3,7,23,47,97,251,443,911,1471,42773 };最后测试
int main()
{
HashTable htable;
htable.insert(1);
htable.insert(2);
htable.insert(3);
htable.insert(4);
htable.insert(5);
htable.insert(6);
return 0;
}可以在插入数据时进行显示数据,这里只是在插入数据时显示了装载因子。
链地址法的哈希表
首先确定基本元素
private:
vector>table_;//哈希表容器
int useBucketNum;//桶的使用个数
double loadFactor;//装载因子
static const int PRIME_SIZE = 10;
static int primes[PRIME_SIZE];//素数表
int primeIdx;//数组使用的下标
构造函数初始化元素
public:
HashTable(int size = primes[0], double loadFactor = 0.75)
{
//确保size是个素数
if (size != primes[0])
{
for (; primeIdx < PRIME_SIZE; primeIdx++)
{
if (primes[primeIdx] >= size)
{
break;
}
}
if (primeIdx == PRIME_SIZE)
{
primeIdx--;
}
}
this->loadFactor = loadFactor;
this->useBucketNum = 0;
this->primeIdx = 0;
table_.resize(primes[primeIdx]);
}插入元素,这里解释一下useBucketNum是哈希桶的使用个数,并不是插入元素的数量,useBucketNum的最大值为哈希表的长度,auto可以自动识别类型,(加了一个查重的操作)
void insert(int key)
{
double factor = useBucketNum * 1.0 / table_.size();
cout << "Factor:" << factor << endl;
//考率扩容
if (factor > loadFactor)
{
expand();
}
int idx = key % table_.size();
if (table_[idx].empty())
{
this->useBucketNum++;
table_[idx].push_back(key);
cout << "Key:" << key << endl;
}
else
{
auto it = ::find(table_[idx].begin(), table_[idx].end(), key);
//vector>::iterator it = find(table_[idx].begin(), table_[idx].end(), key);
//查重
if (it != table_[idx].end())
{
table_[idx].push_back(key);
cout << "Key:" << key << endl;
}
}
} 删除元素,
void erase(int key)
{
int idx = key % table_.size();
auto it = ::find(table_[idx].begin(), table_[idx].end(), key);
if (it != table_[idx].end())
{
table_[idx].erase(it);
if (table_[idx].empty())
{
this->useBucketNum--;
}
}
}查找元素
bool find(int key)
{
int idx = key % table_.size();
auto it = ::find(table_[idx].begin(), table_[idx].end(), key);
return it != table_[idx].end();
}哈希表的扩容,这里的扩容实际上是在定义一个哈希表,将新哈希表与老哈希表内容交换,再重新哈希
void expand()
{
++primeIdx;
if (primeIdx > PRIME_SIZE)
{
cout << "can not expand" << endl;
return;
}
vector>newtable;
table_.swap(newtable);
table_.resize(primes[primeIdx]);
this->useBucketNum = 0;
/*for (vector>::iterator it = newtable.begin(); it != newtable.end(); it++)
{
for (list::iterator lit = (*it).begin(); lit != (*it).end(); lit++)
{
int idx = (*lit) % table_.size();
if (table_[idx].empty())
{
this->useBucketNum++;
}
table_[idx].push_back((*lit));
}
}*/
for (auto it : newtable)
{
for (auto lit : it)
{
int idx = lit % table_.size();
if (table_[idx].empty())
{
this->useBucketNum++;
}
table_[idx].push_back(lit);
}
}
} 补充
这里的push_back其实可以换成emplace_back,其实这两者在大多数情况下效果是等同的,但是对于vector