DBA面试总结(Oracle篇)
一、备份恢复
1. RMAN备份是一种用于备份和恢复数据库文件归档日志和控制文件的工具软件,主要执行的是物理备份,可以执行完全或不完全的数据库恢复。既能支持热备,在归档模式下,RMAN可以执行在线备份。在非归档模式下,RMAN备份通常在数据库处于mount状态下进行。RMAN备份具有以下优点:支持增量备份,可以节省备份时间和空间。自动管理备份文件,无需手动指定文件名或位置,自动化备份和恢复,无需手动执行复杂的步骤。不产生重做信息,减少I/O开销,支持映像复制可以直接使用操作系统命令拷贝或恢复文件。
2. 闪回技术:alter database flashback on;
二、Oracle性能优化
1. Oracle优化器:
是一种用于生成执行计划的组件,他可以根据不同的优化目标(如成本规则,选择性)选择最佳的访问路径和连接方法。
2.Oracle统计信息:
是一种用于收集和维护数据库对象(如表,索引,列)的特征信息 例如大小 技术分布等,他可以帮助优化器生成更准确的执行计划。
3.Oracle 自动工作负载存储库(AWR):
是一种用于收集好存储数据库的性能数据的工具,他可以定期生成快照记录数据库的活动和资源消耗情况
4.Oracle 自动数据库诊断监听器 ADDM:
是一种用于分析AWR数据并提供性能优化建议的工具它可以识别数据库中存在的瓶颈和等待事件。
5.Oracle企业管理器(OEM):
是一种用于监控和管理数据库的图形界面工具它可以提供多种寻个能优化功能,例如性能仪表板,sql调优顾问,sql访问顾问等
三、内存结构
内存结构:
SGA(System Global Area):
SGA是一块内存区域,用于存储数据库实例的共享数据和结构。它包括缓冲池、共享池、重做日志缓冲区等。AMM 是一种自动内存管理技术,它允许数据库实例根据需要自动调整和管理内存分配。
- 共享池(Shared Pool):这是内存中最关键的部分之一,用于缓存程序数据。共享池包括库高速缓存区(Library Cache),用于存储已经解析过的SQL的信息;数据字典缓存(Data Dictionary Cache),用于存放系统参数;以及结果高速缓存(Result Cache),用于存储和检索高速缓存的结果。
- 固定SGA(Fixed SGA):存储了内存中其他区的位置。
- 重做缓冲区(Redo Buffer):如果数据需要写到在线重做日志中,则在写至磁盘之前要在Redo Buffer中临时缓存这些数据。
此外,SGA还包括以下组件:
- 数据缓冲区(Database Buffer Cache):用于缓存数据库中的数据块,是Oracle读取磁盘数据时的重要缓存区域。
- 大型池(Large Pool):主要用于大型内存分配,如分布式数据库操作和多个实例的共享服务器。
- Java池(Java Pool):用于存储Java代码和数据,允许Oracle数据库在存储过程和函数中执行Java代码。
- 流池(Streams Pool):用于Oracle流复制操作,允许在数据库之间复制数据和更改。
通过设置 SGA_TARGET 参数,AMM 可以自动分配和释放共享池、数据库缓冲区和重做日志缓冲区等共享内存组件的大小,以适应实际工作负载的变化。AMM 简化了内存管理的过程,并且对于许多小型到中型数据库是一个方便且有效的选项。
ASMM 是 AMM 的一个特定功能,用于自动管理 SGA 内存中的共享池和数据库缓冲区的大小。ASMM 会根据实际需求动态调整这些内存组件的大小,以提供最佳性能和资源利用率。ASMM 主要关注 SGA 内存的管理,而没有涉及其他内存结构,比如 PGA(Program Global Area)。
总结来说,AMM 是一种更广义的自动内存管理技术,包括对SGA和PGA 的管理,而 ASMM 是 AMM 中专注于自动管理 SGA 内存的一个具体功能。选 择使用哪种技术取决于数据库管理员对内存管理的需求和偏好,以及数据库 的规模和工作负载。
PGA(Program Global Area):
PGA是每个用户进程独立使用的内存区域,用于存储会话特定的数据和变量
PGA主要包含以下几个部分:
-
排序区(Sort Area):当Oracle执行排序操作时(例如ORDER BY子句或GROUP BY子句),它会在排序区中分配内存。如果排序的数据量很大,不足以在排序区中容纳,Oracle会执行磁盘排序,这通常比内存排序慢得多。
-
哈希区(Hash Area):当执行哈希连接或哈希聚合操作时,Oracle会使用哈希区。与排序区类似,如果哈希操作需要的内存超过哈希区的大小,Oracle会回退到磁盘操作。
-
会话信息(Session Information):这部分内存包含了关于当前会话的元数据信息,例如当前打开的游标、变量绑定信息、事务信息等。
-
堆栈空间(Stack Space):用于存储进程调用栈的信息,包括函数和过程的局部变量等。
四、后台进程
DBWn(Database Writer):负责将数据库缓冲区中的数据写回磁盘,以保证数据的持久性。
LGWR(Log Writer):负责将日志缓冲区中的日志写入到磁盘上的在线重做日志文件,用于数据库的恢复和事务的持久性。
PMON(Process Monitor):负责监控和管理用户进程。当用户进程异常终止或断开连接时,PMON会清理相关资源,并发起必要的恢复操作。
SMON(System Monitor):负责系统级的维护任务,包括实例恢复、空间管理和垃圾回收等。
CKPT(Checkpoint Process):负责定期向数据文件和控制文件写入检查点,以确保数据库在恢复时可以从一致的状态开始。将数据库中的脏数据(已经被修改但尚未写入磁盘)刷新到磁盘,同时将当前的SCN(系统变化编号)更新到数据文件头部,以确保数据库在恢复时能够正确地还原到一致的状态。此外,checkpoint 也有助于控制数据库的恢复时间,并减少数据库在恢复过程中需要重做的工作量
五、OracleRAC中scan ip 和vip
vip一个数据库实例虚拟IP地址,主要用于提供数据库服务的访问入口。当实例故障时,VIP会自动切换到其他节点上的实例,VIP与实例绑定,客户端的tnsname.ora一般会配置指向节点的VIP;
scan ip作为RAC集群的一个虚拟IP地址,其作用是充当应用程序和数据库之间的桥梁。客户端可以通过SCAN IP地址连接到整个集群,客户端可以通过SCAN特性负载均衡地连接到RAC数据库SCAN提供一个域名来访问RAC,域名可以解析1个到3个(注意,最多3个)SCAN IP,我们可以通过DNS或者GNS来解析实现.
连接到 SCAN IP LISTENER,而SCAN IP LISTENER接收到连接请求时,会根据 LBA 算法将该客户端的连接请求,转发给对应的instance上的VIP LISTENER。
六、RAC集群的后台进程
-
LMSn (Global Cache Service Process):
- LMSn进程维护Global Resource Directory (GRD)中的数据文件以及每个cached block的状态。
- 它负责在RAC的实例间进行message以及数据块的传输,实现Global Cache Service (GCS)。
- LMSn是Cache Fusion的一个重要部分,确保数据在集群中的一致性。
- LMSn进程在RAC上非常活跃,可能会消耗较多的CPU资源。
- LMS进程还负责全局死锁的检测任务,并监控锁转换是否超时。
全局缓存服务(GCS)
LMSn后台进程使用GCS在全局buffer cache中维护缓存的一致性,SGA中可以存在同一个数据块的多份拷贝(当前版本只有一个),GCS对数据块的状态和位置进行跟踪,并通过内部连接将块传输到其他节点的实例中。
2.LMD (Global Enqueue Service Daemon):
1.LMD进程主要管理全局队列和资源的访问,确保资源在集群中的正确分配和使用。
2.它处理来自其他实例的资源请求,并更新队列的状态。
3.LMD还负责处理死锁情况,确保资源不会被长时间锁定而导致其他实例无法访问。
全局队列服务(GES)
和GCS类似,GES工作在块级别,管理集群中的全局队列。根据经验,如果一个操作没有涉及在全局buffer cache中控制/移动数据块,那么很可能是经过了GES的处理。全局队列服务负责所有的实例中的资源操作,比如对数据字典和库缓存的访问或事务的全局管理。它同样可以检测集群中的死锁。它跟踪多个实例同时访问资源时Oracle队列机制的状态。全局队列服务监控(LMON)和全局队列服务后台进程(LMD)组成全局队列服务的一部分。锁进程LCK0负责无缓存方式的访问,比如library和row cache请求。
3.LMON (LOCK Monitor Processes):
1.LMON进程也被称为Global enqueue service monitor,负责监控整个集群的状态。
2.它维护GCS的内存结构,监控非正常终止的进程和实例。
3.当实例离开或加入集群时,LMON负责锁和资源的重新配置。
4.它还管理全局的锁和资源,处理死锁和阻塞情况。
4.LCK (Lock Process):
1.LCK进程主要处理非cache fusion的资源请求,例如library和row cache请求。
2.它与其他进程合作,确保资源的正确分配和使用。
七、Oracle GI集群的启动顺序
- 启动OHASD组件:GI的启动必须首先启动OHASD组件。在Linux环境中,OHASD作为一个shell脚本存在,路径为
/etc/init.d/init.ohasd。这个脚本会随着操作系统的启动而被拉起。在Linux 7及更高版本中,init.ohasd可能会被systemd以服务的形式启动。确保init.ohasd脚本被正确调用,并且OS运行在正确的级别上。如果OHASD没有正确启动,可能会导致GI无法自动启动。 - 检查OLR和网卡:在OHASD启动后,OLR(Oracle Local Registry)会被访问。因此,需要确保OLR存在且能够正常访问。此外,还需要确定集群中的网卡支持多播,并且节点间的通信正常。
- 启动GI服务:GI的启动可以通过两种方式实现:一种是伴随着操作系统的启动而自动启动GI,另一种则是使用
crsctl start crs命令手动启动GI。不论采用哪种方式,都需要确保有init.ohasd进程存在。 - 确认GI是否正常启动:输入命令检查状态crsctl check cluster
八、大页的使用
大页(Hugepages)的使用是为了提高性能,减少页交换,特别在物理内存较大的系统中。大页占用的内存量取决于系统配置和可用的物理内存。每个大页的尺寸通常是标准页(通常为4K)的倍数,比如2M或更大。通过配置大页,Oracle可以更高效地管理内存,减少操作系统对页面状态的维护,并提高TLB(转换旁路缓冲区)缓存命中率。
九、磁盘组中的au_size
磁盘组中的au_size,AU(Allocate Unit)是磁盘组分配空间的最小单位。AU的大小可以通过设置AU_SIZE的属性值来指定。从Oracle 11.1版本开始,AU的大小可以是1MB、2MB、4MB、8MB、16MB、32MB或64MB。如果不指定AU的大小,默认值通常是1MB
十、RAC 集群的心跳机制
- 网络心跳:这是RAC心跳机制中最为核心的部分。通过LMON进程,每个实例会定期通过数据库的私网(即内存融合使用的网络)与其他所有实例进行通信,以确认彼此的状态。如果某个实例在一段时间内(默认是300秒)不能响应其他节点发送的网络心跳信息,那么数据库集群会进行重新配置。此外,除了LMON进程,本地实例的LMS、LMD和LCK0等进程也会与远程节点对应的进程进行通信,以检测彼此之间的状态。
- 磁盘心跳:RAC中的磁盘心跳主要用于检测存储层面的连通性和状态。虽然其基本原理与集群层面的磁盘心跳相似,但由于数据库层面没有VF(虚拟文件系统)存在,实现方式会有所不同。磁盘心跳能够确保节点在存储层面也能够保持连通和状态同步。
- 本地心跳:本地心跳是节点自我监控的一种方式。通过本地心跳,节点能够将自己的状态信息发送给CSSDAGENT和CSSDMONITOR等进程,实现自我监控。这样,当节点遇到问题时,能够自我处理,更好地维护节点的一致性。
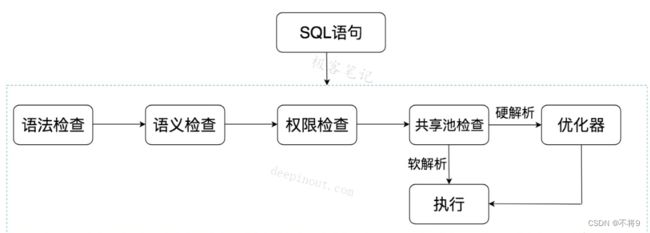
十一、Oracle SQL执行流程
1. 客户端提交SQL语句
Oracle语句执行流程第一步:客户端把语句发给服务器端执行当我们在客户端执行SQL语句时,客户端会把这条SQL语句发送给服务器端,让服务器端的进程来处理这语句。也就是说,Oracle 客户端是不会做任何的操作,他的主要任务就是把客户端产生的一些SQL语句发送给服务器端。服务器进程从用户进程把信息接收到后, 在PGA 中就要此进程分配所需内存,存储相关的信息,如:在会话内存存储相关的登录信息等。
2.服务器进程接收SQL语句
服务器通过Server Process接收SQL语句。在客户端也有一个数据库进程,但是,这个进程的作用跟服务器上的进程作用是不相同的,服务器上的数据库进程才会对SQL 语句进行相关的处理。不过,有个问题需要说明,就是客户端的进程跟服务器的进程是一一对应的。也就是说,在客户端连接上服务器后,在客户端与服务器端都会形成一个进程,客户端上的我们叫做客户端进程,而服务器上的我们叫做服务器进程。
3.语法检查
当客户端提交一个SQL语句到Oracle数据库时,首先会进行语法检查。Oracle会验证SQL语句是否符合SQL语言的语法规则。如果语法不正确,Oracle会立即返回一个错误消息,而不会进行后续的解析或执行步骤。
4.语义检查
检查SQL中的访问对象是否存在。比如我们在写SELECT语句的时候,列名写错了,系统就会提示错误。语法检查和语义检查的作用是保证SQL语句没有错误。
5.权限检查
看用户是否具备访问该数据的权限。
6.查询共享池(Shared Pool)中的高速缓存(library cache)
服务器进程在接到客户端传送过来的SQL语句时,不会直接去数据库查询。
服务器进程把这个SQL语句的字符转化为ASCII等效数字码,接着这个ASCII码被传递给一个HASH函数,并返回一个hash值,然后服务器进程将到shared pool中的library cache(高速缓存)中去查找是否存在相同的hash值。如果存在,服务器进程将使用这条语句已高速缓存在SHARED POOL的library cache中的已分析过的版本来执行,省去后续的解析工作,这便是软解析。若调整缓存中不存在,则需要进行后面的步骤,这便是硬解析。
7.硬解析
如果没有找到SQL语句和执行计划,Oracle就需要创建解析树进行解析,生成执行计划,进入“优化器”这个步骤,这就是硬解析。
8.优化器
优化器中就是要进行硬解析,也就是决定怎么做,比如创建解析树,生成执行计划。
9.执行器
当有了解析树和执行计划之后,就知道了SQL该怎么被执行,这样就可以在执行器中执行语句了。
下面这张图能够更好理解一些: