仅用10张图片,AI就能学会识别万物?多模态小样本学习颠覆传统!
小样本学习与多模态结合是当前人工智能领域的热门研究方向,旨在通过结合多模态数据(如视觉、语言、音频等)来提高模型在数据稀缺情况下的学习效率和性能。
例如,ZS-DeconvNet方法在Nature上发表,展示了其在极低训练数据需求下,将图像分辨率提升超过1.5倍衍射极限的能力。此外,CPE-CLIP和MMFL等方法通过利用预训练模型和冻结的大规模视觉语言模型,实现了跨会话的迁移学习和快速适应新样本。
这些创新不仅在医疗诊断、自动驾驶等重要领域展现出巨大潜力,也为解决数据稀缺问题提供了新的思路和方法。
我整理了11篇【小样本学习+多模态】相关论文,全部论文PDF版,工中号【沃的顶会】回复“小样多模态”即可领取
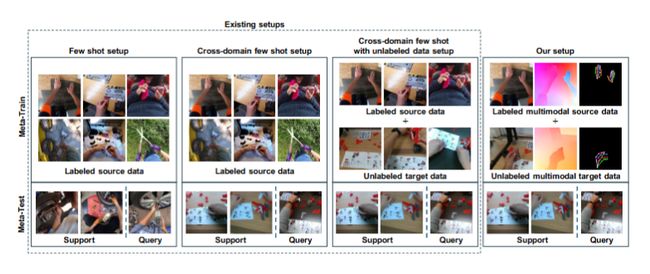
Multimodal Cross-Domain Few-shot Learning for Egocentric ActionRecognition
文章解析
本文提出了一种名为MM-CDFSL的方法,该方法通过多模态蒸馏和掩码推理集成技术解决了第一人称视角视频中跨域少样本学习任务中的两个关键挑战:极端领域差距和实际应用中的计算成本问题。
该方法利用教师模型进行多模态蒸馏,并引入了掩码推理集成技术来减少输入标记的数量,从而提高了目标领域的适应性和推理速度。
创新点
1.提出了多模态蒸馏技术以增强学生模型对目标领域的适应性。
2.引入了掩码推理集成技术,有效降低了性能下降并提高了推理速度。
3.在多个第一人称视角数据集上显著超越了现有CD-FSL方法。
研究方法
1.利用教师模型进行独立训练并在多模态蒸馏过程中仅使用未标注的目标数据。
2.通过掩码技术减少输入标记数量,同时使用集成预测来缓解性能下降。
3.在元训练阶段利用多模态数据,在元测试阶段仅使用RGB视频作为输入。
研究结论
1.提出的MM-CDFSL方法在多个第一人称视角数据集上取得了显著的性能提升。
2.该方法在1-shot和5-shot设置下分别提高了平均6.12/6.10个百分点,并实现了2.2倍的更快推理速度。
3.多模态蒸馏和掩码推理集成技术有效解决了跨域少样本学习中的关键挑战。
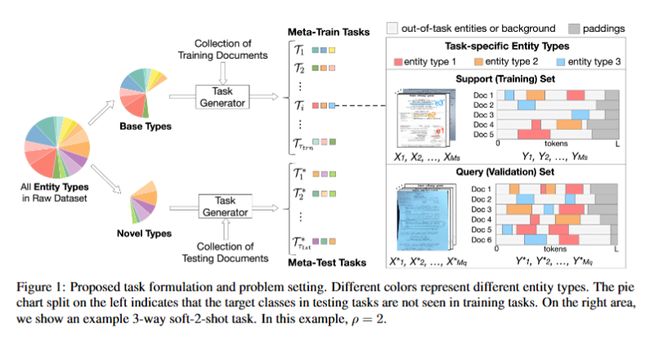
On Task-personalized Multimodal Few-shot Learning for Visually-rich Document Entity Retrieval
文章解析
本文研究了视觉丰富文档实体检索(VDER)中的少样本问题,提出了一种面向任务的元学习框架,通过对比学习和层次解码器等技术,实现了对任务特定标签空间的有效个性化,并处理了分布外内容。
此外,引入了一个新的数据集FewVEX,以促进未来在实体级少样本VDER领域的研究。
创新点
1.首次研究了实体级别的少样本VDER问题,提供了与现有文档级别工作互补的研究视角。
2.提出了面向任务的元学习框架,通过处理分布外内容增强任务个性化。
3.引入了新的数据集FewVEX,包含数千个实体级别的少样本VDER任务,促进了未来研究的发展。
研究方法
1.提出了N-way软K-shot VDER任务设置,模拟了每个少样本任务的应用场景。
2采用预训练语言模型和元学习框架,结合对比学习和层次解码器等技术,实现任务个性化。
3.设计了自动数据集生成算法XDR,用于扩展文档类型和实体类型的数量,确保软平衡的少样本注释。
研究结论
1.实验结果表明,所提出的任务感知元学习方法显著提高了基线方法的性能。
2.面向任务的元学习框架有效减少了预训练模型与新型FVDER任务之间的领域差距,促进了更快更有效的微调。
3.新的数据集FewVEX为未来研究提供了丰富的资源。