23. AI-大语言模型
文章目录
- 前言
- 一、LLM
-
- 1. 简介
- 2. 工作原理和结构
- 3. 应用场景
- 4. 最新研究进展
- 5. 比较
- 二、Transformer架构
-
- 1. 简介
- 2. 基本原理和结构
- 3. 应用场景
- 4. 最新进展
- 三、开源
-
- 1. 开源概念
- 2. 开源模式
- 3. 模型权重
- 四、再谈DeepSeek
前言
AI
一、LLM
LLM(Large Language Model,大语言模型)
1. 简介
LLM(Large Language Model,大语言模型)是指使用大量文本数据训练的深度学习模型,能够生成自然语言文本或理解语言文本的含义。
LLM的核心思想是通过大规模无监督训练学习自然语言的模式和结构,模拟人类的语言认知和生成过程。
2. 工作原理和结构
LLM通常采用Transformer架构和预训练目标(如Language Modeling)进行训练。通过层叠的神经网络结构,LLM学习并模拟人类语言的复杂规律,达到接近人类水平的文本生成能力。这种模型在自然语言处理领域具有广泛的应用,包括文本生成、文本分类、机器翻译、情感分析等。
3. 应用场景
LLM在多种应用场景下表现出色,不仅能执行拼写检查和语法修正等简单的语言任务,还能处理文本摘要、机器翻译、情感分析、对话生成和内容推荐等复杂任务。近期,GPT-4和LLaMA等大语言模型在自然语言处理等领域取得了巨大的成功,并逐步应用于金融、医疗和教育等特定领域。
4. 最新研究进展
最近的研究进展包括AI系统自我复制的能力和自回归搜索方法。复旦大学的研究表明,某些开源LLM具备自我克隆的能力,这标志着AI在自主进化方面取得了重大突破。此外,MIT、哈佛大学等机构的研究者提出了行动-思维链(COAT)机制,使LLM具备自回归搜索能力,提升了其在数学推理和跨领域任务中的表现。
5. 比较
大语言模型采用与小模型类似的Transformer架构和预训练目标(如 Language Modeling),与小模型的主要区别在于增加模型大小、训练数据和计算资源 。
相比传统的自然语言处理(Netural Language Processing, NLP)模型,大语言模型能够更好地理解和生成自然文本,同时表现出一定的逻辑思维和推理能力。
二、Transformer架构
1. 简介
Transformer是一种在自然语言处理(NLP)领域具有革命性意义的神经网络架构,主要用于处理和生成语言相关的任务。
Transformer架构由Google的研究团队在2017年提出,并在BERT等预训练模型中得到了广泛应用。
2. 基本原理和结构
Transformer架构主要由以下几个部分组成:
- 输入部分:包括源文本嵌入层和位置编码器,用于将源文本中的词汇转换为向量表示,并生成位置向量以理解序列中的位置信息。
- 编码器部分:由多个编码器层堆叠而成,每个编码器层包含多头自注意力子层和前馈全连接子层,并通过残差连接和层归一化操作进行优化。
- 解码器部分:由多个解码器层组成,每个解码器层包含带掩码的多头自注意力子层、多头注意力子层(编码器到解码器)和前馈全连接子层。
- 输出部分:包括线性层和Softmax层,用于将解码器的输出转换为最终的预测结果。
3. 应用场景
Transformer架构在NLP领域有着广泛的应用,包括但不限于:
- 机器翻译:将一种语言自动翻译成另一种语言。
- 文本生成:根据给定的文本生成新的文本内容。
- 情感分析:分析文本的情感倾向,如积极、消极或中性。
- 问答系统:根据问题生成答案。
- 语言模型:如GPT系列,用于生成文本。
4. 最新进展
最新的研究和发展方向包括探索如何通过扩展测试时计算量来提升模型推理能力,例如通过深度循环隐式推理方法,显著提升模型在复杂推理任务上的性能。此外,Transformer架构也在其他领域如图像处理和语音识别中展现出强大的应用潜力。
三、开源
1. 开源概念
为了适应时代发展,OSI(Open Source Initiative,开源代码促进会)专门针对 AI 提出了三种开源概念,分别是:
- 开源 AI 系统:包括训练数据、训练代码和模型权重。代码和权重需要按照开源协议提供,而训练数据只需要公开出处(因为一些数据集确实无法公开提供)。
- 开源 AI 模型:只需要提供模型权重和推理代码,并按照开源协议提供。
- 开源 AI 权重:只需要提供模型权重,并按照开源协议提供。
所谓推理代码,就是让大模型跑起来的代码,或者说大模型的使用代码,这也是一个相当复杂的系统性工程,涉及到了 GPU 调用和模型架构。
DeepSeek 只开源了权重,并没有开源训练代码、数据集和推理代码,所以属于第三种开源形式。DeepSeek 官方一直都在说自己开源了模型权重,用词精确。
其实第二种和第三种区别不大,因为在实际部署中,一般都会借助 Ollama 工具包,它已经包含了推理代码(llama.cpp),所以即使官方公布了推理代码,也不一定会被使用。
2. 开源模式
即使获取到训练代码和数据集,复现出类似的模型权重,成本极高,花费几百万几千万甚至几个亿。一般对于大模型用户而言,直接把官方开源的模型权重拿来使用即可。
当然,开源训练代码和数据集,对于学术研究还是有重大帮助的,它能快速推动产业进步,让人类早点从 AGI 时代进入 ASI 时代,所以第一种开源模式的意义也不能被忽视。
3. 模型权重
所谓大模型,就是超大规模的神经网络,它类似于人类的大脑,由无数个神经元(权重/参数)构成。
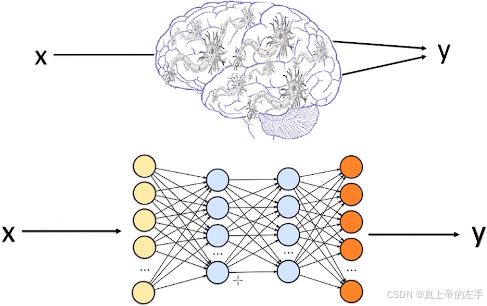
刚开始的时候,大模型的所有权重都是随机的,就类似于婴儿刚出生时大脑一片空白。训练大模型的过程,就是不断调整权重的过程,这和人类通过学习来调整神经元的连接是一个道理。把训练好的大模型开源,就相当于把学富五车的大脑仍给你,你可以让它做很多事情。
满血版 DeepSeek R1(671B 版本,一个 B 等于 10 个亿)有 6710 亿个参数,模型文件的体积达到了 720GB,相当恐怖。别说个人电脑了,单台服务器都无法运行,只能依赖集群了。
为了方便大家部署,官方又在满血版 R1 的基础上蒸馏出了多个小模型,减少了参数的数量,具体如下:
- 70B 版本,模型体积约 16GB;
- 32B 版本,模型体积约 16GB;
- 7B 版本,模型体积约 4.7GB;
- 1.5B 版本,模型体积约 3.6GB。
最后两个模型在配置强大的个人电脑上勉强能跑起来。
模型权重都是超大型文件,而且有指定的压缩格式(比如 .safetensors 格式),一般都是放在 Hugging Face(抱抱脸)上开源,而不是放在传统的 GitHub 上。
DeepSeek R1 的开源地址(需要梯子才能访问)
四、再谈DeepSeek
虽然 DeepSeek 只开源了模型权重,没有开源模型代码,但是官方通过技术报告/论文公布了很多核心算法,以及降本增效的工程解决方案,同时也为强化学习指明了一种新的范式,打破了 OpenAI 对推理技术的封锁(甚至是误导),让业界重新看到了 AI 持续进步的希望。
另外,DeepSeek 还允许二次蒸馏,不管是商业的还是公益的,你可以随便玩,这让小模型的训练变得更加简单和廉价。你再看看 OpenAI,明确写着不允许竞品进行二次蒸馏,并且妄图以此来指控 DeepSeek。
DeepSeek 的格局是人类,OpenAI 的格局是自己!
总之,对于一家商业公司来说,DeepSeek 的开放程度可以说是非常透明,透明到了毁灭自己的地步。包括 Hugging Face、伯克利大学、香港大学在内的某些机构,已经在尝试复现 DeepSeek 了。
本文的引用仅限自我学习如有侵权,请联系作者删除。
参考知识
抱歉,DeepSeek并没有开源代码,别被骗了!