1-刷力扣问题记录
25.1.19
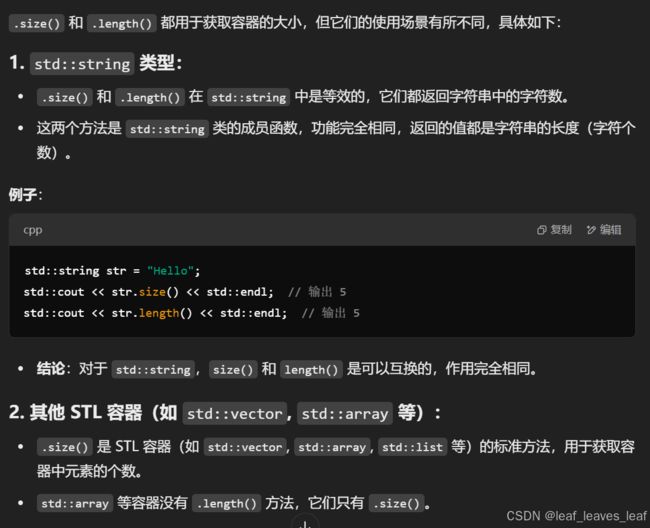
1.size()和.length()有什么区别
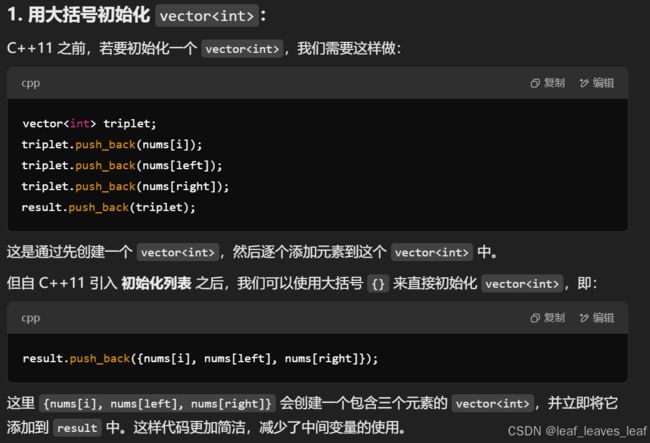
2.result.push_back({nums[i], nums[left], nums[right]});为什么用大括号?
使用大括号 {} 是 C++11 引入的 初始化列表 语法,它允许我们在构造或初始化对象时直接传入一组值。大括号的使用在许多情况下都能让代码更加简洁和直观。
{nums[i], nums[left], nums[right]} 是一个 初始化列表,用于初始化一个 vector 类型的对象,这个 vector 对象包含三个元素:nums[i]、nums[left] 和 nums[right]。
2. 为什么使用大括号而不是小括号?
在 C++ 中,小括号 () 用于函数调用或者对象的构造,而大括号 {} 则用于初始化列表。使用大括号 {} 初始化列表的优势在于:
- 简洁性:代码更简洁,直接用大括号传递多个参数。
- 类型推导:C++11 允许类型推导(比如
vector类型可以通过初始化列表自动推导出),减少了显式的类型声明。 - 防止意外构造:大括号
{}语法更具表达性,避免了潜在的构造问题或不必要的类型转换。
4. 大括号 {} 和小括号 () 的区别:
-
小括号
()用于:- 函数调用。
- 构造函数的参数传递。
- 转型时显式指定类型,如
int(x)。
-
大括号
{}用于:- 初始化列表(C++11 引入)。
- 函数体、循环体等代码块。
总结:
使用大括号 {} 是 C++11 引入的初始化列表语法,它可以用来创建并初始化对象(例如 vector),使代码更加简洁、可读。
25.1.20
1.vector> fourSum(vector& nums, int target) { 为什么要写&
在 C++ 中,& 用在参数类型后面,表示传递引用(pass by reference)。具体到你问的 vector,这表示传递 nums 这个 vector 类型的参数时,是通过引用传递的,而不是通过值传递。让我们详细了解为什么使用 &。
1. 传值 vs 传引用:
- 传值:函数参数
vector如果不加nums &,表示通过值传递。这意味着将nums数组的一个副本传递给函数,函数内的修改不会影响原始的nums数组。 - 传引用:函数参数
vector表示通过引用传递,这意味着你传递的是& nums nums本身的引用,函数内对nums的修改将直接影响原始的nums数组。
2. 为什么使用 &:
- 避免复制大数组:
vector是一个动态数组,当你通过值传递时,会将整个数组复制一份到函数内部。这样对于较大的数组,会浪费大量的内存和时间。通过引用传递(&),你只传递数组的内存地址,不需要复制整个数组。 - 修改原数组:如果你想在函数中修改原数组,必须使用引用传递。通过值传递,你只操作的是数组的副本,无法修改原始数组。
- 效率:如果不加
&,每次调用函数都会复制整个vector,这在处理大数据时会非常低效,尤其是像vector这样动态分配内存的数据结构。
2.reverse(s.begin(), s.end())和 reverse(0, s.size());有区别吗
是的,reverse(s.begin(), s.end()) 和 reverse(0, s.size()) 有区别,它们的使用方式和参数类型不同。
1. reverse(s.begin(), s.end()):
reverse(s.begin(), s.end())是通过 迭代器 来指定需要反转的范围。s.begin()是一个指向s第一个字符的迭代器。s.end()是一个指向s最后一个字符 后面位置 的迭代器。- 因此,
reverse(s.begin(), s.end())会反转字符串s中从第一个字符到最后一个字符的所有字符。
string s = "hello";
reverse(s.begin(), s.end());
cout << s; // 输出 "olleh"
2. reverse(0, s.size()):
reverse(0, s.size())使用的是 整数索引 来指定反转的范围,假设reverse函数是使用整数索引而不是迭代器。0表示字符串的第一个字符的索引,s.size()表示字符串的长度。这里的s.size()代表的是最后一个字符之后的位置,而不是实际的字符索引。注意,如果直接这样写,reverse(0, s.size())并不直接适用于std::string,因为标准库的reverse算法并不接受整数值,而是接受迭代器。
示例(如果 reverse 支持整数索引):
// 如果自定义了 reverse 函数
string s = "hello";
reverse(0, s.size()); // 这里假设 reverse 函数接受索引
cout << s; // 输出 "olleh"
区别:
-
参数类型:
reverse(s.begin(), s.end())使用的是迭代器,标准库的reverse函数要求参数为迭代器类型。reverse(0, s.size())使用的是整数索引,这种方式在标准库中不直接适用。
-
范围表示:
reverse(s.begin(), s.end())表示从第一个元素到最后一个元素的范围(注意s.end()是一个指向容器末尾后一个位置的迭代器)。reverse(0, s.size())如果是整数索引,通常是表示从索引 0 到索引s.size(),这意味着反转的范围应该是从第一个字符到 最后一个字符之后 的位置。这可能会导致越界或错误的行为,除非你使用了自定义的reverse函数来处理这种情况。
结论:
- 正确的用法是
reverse(s.begin(), s.end()),这是 C++ 标准库reverse函数的标准用法。 reverse(0, s.size())不是 C++ 标准库的有效用法,除非你自定义了一个支持整数索引的reverse函数。
25.1.21
1.定义函数void getNext(int* next, string& s)和引用该函数getNext(&next[0], needle)
在这段代码中,int* next 和 getNext(&next[0], needle) 涉及到如何通过传递数组的指针来修改数组内容。我们逐步解释这两部分的含义:
1. int* next 的含义:
int* next 是一个指针变量,用来接收 next 数组的首地址。具体来说,next 数组存储的是模式串(needle)的部分匹配表(或称为 KMP 算法的 next 数组)。
在 C++ 中,数组名本身就代表数组的首地址。因此,如果我们定义一个数组 next,则 &next[0] 是数组 next 的首地址。
2. getNext(&next[0], needle) 的含义:
getNext(&next[0], needle) 调用了一个函数 getNext,该函数的作用是计算并填充 next 数组。&next[0] 传递的是 next 数组的首地址,即该数组的指针。
在 getNext 函数内,next 数组的值会根据 needle(模式串)的内容被修改,从而帮助后续字符串匹配时跳过已经匹配的部分,提高匹配效率。
代码中传递 &next[0] 的原因:
next是一个vector类型的容器,&next[0]返回的是vector内部的数组的首地址(即int*类型)。- 因为
next是一个vector类型的对象,而getNext函数的参数是int* next(指针类型),所以需要传递&next[0],即next数组的指针。 - 这样传递指针的好处是
getNext可以直接修改next数组的内容,而不需要返回一个新的数组。
2.t.erase(t.begin())和t.erase(t[0])有什么区别
t.erase(t.begin()) 和 t.erase(t[0]) 这两行代码看起来很相似,但实际上它们是 完全不同的。它们的行为有很大的差别。
1. t.erase(t.begin())
-
t.begin()返回的是指向字符串t第一个字符的 迭代器。 -
erase方法用于删除字符串中的元素,而它接受的参数是一个 迭代器,指向要删除的字符。 -
t.erase(t.begin())会删除字符串t的第一个字符,等同于t[0]被删除。
2. t.erase(t[0])
-
t[0]是字符串t中第一个字符的 值,而不是指向该字符的迭代器。 -
erase方法要求传入一个 迭代器 或者一个 下标,而t[0]是一个字符,不能作为erase的参数。因此,t.erase(t[0])会导致编译错误,因为t[0]返回的是一个字符值,而不是迭代器。
总结
t.erase(t.begin()):删除字符串t中第一个字符,通过迭代器指定要删除的位置。t.erase(t[0]):这是错误的,t[0]返回的是字符值,不是迭代器,因此不能作为erase函数的参数。
正确的做法是使用 t.erase(t.begin()) 来删除字符串中的第一个字符。
25.1.31
1.栈的基本操作都有哪些,介绍一下
- push(x) -- 元素 x 入栈
- pop() -- 移除栈顶元素
- top() -- 获取栈顶元素
- empty() -- 返回栈是否为空
栈(Stack)是一种线性数据结构,遵循后进先出(LIFO,Last In First Out)原则,即最后加入栈的元素最先被移除。栈的基本操作主要包括以下几种:
1. push(x) – 入栈
- 功能:将元素
x添加到栈顶。 - 时间复杂度:O(1),即常数时间操作。
示例:
stack st;
st.push(10); // 将10压入栈顶
st.push(20); // 将20压入栈顶
2. pop() – 出栈
- 功能:移除并返回栈顶元素。
- 前提:栈不能为空,否则调用
pop()时会引发错误(如访问空栈时可能导致未定义行为或运行时错误)。 - 时间复杂度:O(1),即常数时间操作。
示例:
stack st;
st.push(10);
st.push(20);
int top = st.pop(); // 移除栈顶元素20
3. top() – 获取栈顶元素
- 功能:返回栈顶的元素,但不移除它。栈顶元素是最后一次被加入的元素。
- 前提:栈不能为空,否则调用
top()时会引发错误。 - 时间复杂度:O(1),即常数时间操作。
示例:
stack st;
st.push(10);
st.push(20);
int top = st.top(); // 获取栈顶元素20
4. empty() – 判断栈是否为空
- 功能:检查栈是否为空,若为空返回
true,否则返回false。 - 时间复杂度:O(1),即常数时间操作。
示例:
stack st;
bool isEmpty = st.empty(); // 判断栈是否为空
5. size() – 获取栈中元素个数
- 功能:返回栈中元素的个数。
- 时间复杂度:O(1),即常数时间操作。
示例:
stack st;
st.push(10);
st.push(20);
int size = st.size(); // 获取栈中元素个数,结果是2
栈的操作总结:
| 操作 | 描述 | 时间复杂度 |
|---|---|---|
push(x) |
将元素 |
O(1) |
pop() |
移除并返回栈顶元素 | O(1) |
top() |
返回栈顶元素但不移除它 | O(1) |
empty() |
判断栈是否为空 | O(1) |
size() |
获取栈中的元素个数 | O(1) |
peek() 操作是栈(stack)数据结构中的一个常见操作,用于查看栈顶元素,但不移除它。也就是说,peek() 让我们能够访问栈顶的元素,同时保持栈的状态不变。
peek() 操作的主要作用:
返回栈顶元素:它返回栈中最上面的元素。
不改变栈的状态:与 pop() 操作不同,peek() 只是查看栈顶元素,并不会将其移除,所以栈中的元素个数保持不变。
在 C++ 的 STL(标准模板库)中,stack 类自带 top() 方法,这个方法的作用与 peek() 方法相同,都是返回栈顶元素。注意,top() 方法只是查看栈顶元素,不会改变栈的状态
2.队列首部和队列尾部;栈顶和栈底
栈(Stack)是一种线性数据结构,遵循后进先出(LIFO,Last In First Out)原则,即最后加入栈的元素最先被移除。栈的基本操作主要包括以下几种
栈的基本结构:
- 栈顶:栈最上面的元素,是最近压入栈的元素,栈的操作(
push、pop)都作用于栈顶。 - 栈底:栈最底部的元素,是最早压入栈的元素,通常在栈的操作过程中不会直接访问
1. 队列的基本定义:
队列是一种**先进先出(FIFO,First In First Out)**的数据结构,意味着最先加入队列的元素会最先被移除。队列可以通过两端来进行操作:入队(enqueue)和出队(dequeue)
队列的首部和尾部:
- 队列的首部(Front):指队列中最前面的元素,也就是最先被移除的元素(出队时移除的元素)。首部是**出队操作(dequeue)**发生的位置。
- 队列的尾部(Rear/Tail):指队列中最末尾的元素,也就是最近加入的元素(入队时插入的元素)。尾部是**入队操作(enqueue)**发生的位置。
入队和出队操作:
- 入队(enqueue):将一个元素添加到队列的尾部。
- 出队(dequeue):将队列首部的元素移除。
3.队列的基本操作都有哪些,介绍一下
push(x) -- 将一个元素放入队列的尾部。
pop() -- 从队列首部移除元素。
peek() -- 返回队列首部的元素。
empty() -- 返回队列是否为空。
队列(Queue)是一种**先进先出(FIFO, First In First Out)**的数据结构。它支持从两端进行操作:从队列尾部添加元素(入队),从队列首部移除元素(出队)。
队列的基本操作通常包括以下几种:
1. 入队(enqueue)
- 定义:将一个元素添加到队列的尾部。
- 时间复杂度:O(1)(常数时间)
- 示例:
enqueue(10)将元素10加入队列的尾部
void enqueue(int x) {
queue.push(x); // 假设queue是一个标准队列
}
2. 出队(dequeue)
- 定义:从队列的首部移除并返回元素。
- 时间复杂度:O(1)(常数时间)
- 示例:
dequeue()将从队列首部移除一个元素并返回。
int dequeue() {
int front = queue.front(); // 获取队列首部元素
queue.pop(); // 移除队列首部元素
return front; // 返回移除的元素
}
3. 查看队列首部元素(peek/front)
- 定义:返回队列首部的元素,但不移除它。
- 时间复杂度:O(1)(常数时间)
- 示例:
peek()返回队列首部的元素,但不从队列中移除它
int peek() {
return queue.front(); // 返回队列首部元素
}
4. 检查队列是否为空(isEmpty)
- 定义:检查队列是否为空,如果为空返回
true,否则返回false。 - 时间复杂度:O(1)(常数时间)
- 示例:
isEmpty()检查队列是否为空
bool isEmpty() {
return queue.empty(); // 如果队列为空,返回true
}
5. 获取队列的大小(size)
- 定义:返回队列中元素的数量。
- 时间复杂度:O(1)(常数时间)
- 示例:
size()返回队列中元素的个数
int size() {
return queue.size(); // 返回队列中的元素个数
}
6. 清空队列(clear)
- 定义:移除队列中的所有元素。
- 时间复杂度:O(n)(线性时间,取决于队列的大小)
- 示例:
clear()移除所有元素
void clear() {
while (!queue.empty()) {
queue.pop(); // 移除队列中的所有元素
}
}
7. 查看队列尾部元素(back)
- 定义:返回队列尾部的元素,但不移除它。
- 时间复杂度:O(1)(常数时间)
- 示例:
back()返回队列尾部的元素
int back() {
return queue.back(); // 返回队列尾部元素
}
25.2.2
1.什么时候用双引号“”,什么时候用单引号‘’
在 C++ 中,"" 和 '' 都是用来表示字符或者字符串的,但它们的用途有所不同。
-
""(双引号):用于表示字符串(std::string)。例如:"+":这是一个包含一个字符+的字符串。"123":这是一个包含数字字符的字符串。
""用于包含多个字符(甚至是一个字符),并且在 C++ 中,字符串是以std::string类型表示的,字符串类型是一个类,可以调用其成员函数。 -
''(单引号):用于表示单个字符(char)。例如:'+':这是一个字符+,而不是一个字符串。'a':这是字符a。
''只能用于表示单个字符,它会创建一个char类型的值。
总结:
- 双引号
""用于表示字符串,可以包含一个或多个字符。 - 单引号
''用于表示单个字符。 - 在你的代码中,
tokens[i]是一个字符串,所以需要使用 双引号 来比较运算符
25.2.3
1.priority_queue, vector>, mycomparison> pri_que; 什么意思
这行代码定义了一个 优先队列 (priority_queue) 变量 pri_que,它用于存储一组元素,并确保可以快速访问具有最大(或最小)优先级的元素。具体来说,它是一个小顶堆(因为我们定义的比较函数使得堆顶是频率最小的元素)。
让我们逐一解释这个声明:
priority_queue, vector>, mycomparison> pri_que;
1. priority_queue
priority_queue 是 C++ STL 提供的容器适配器(container adapter)。它是一个基于堆(heap)的数据结构,用于维护一个集合,其中的元素总是按照优先级顺序排列。通过堆操作(插入和删除),它可以确保总是快速地访问具有最大(或最小)优先级的元素。
- 默认情况下,
priority_queue实现的是 最大堆,即堆顶元素是当前队列中的最大元素。 - 如果要实现 最小堆(如在本代码中),需要通过自定义比较器来实现。
2. pair
在这里,priority_queue 存储的是 pair 类型的元素。每个元素是一个二元组,由两个 int 类型的值组成:
pair.first:通常存储的是某个值(例如,数字)。pair.second:通常存储的是该值的 频率 或者某个权重,表示优先级。
例如,在这段代码中,我们使用它来存储频率对:
- 第一个
int表示数组中的元素(数字)。 - 第二个
int表示该元素出现的频率。
3. vector
这部分指定了 priority_queue 内部的底层容器类型。默认情况下,priority_queue 使用的是 vector 作为底层容器,但也可以使用其他容器(如 deque)。在这里,vector 表示堆将使用一个 vector 来存储 pair 类型的元素。
4. mycomparison
mycomparison 是我们自定义的比较器类,用于定义堆元素的优先级。在这里,它用于将小顶堆的行为实现为基于频率的排序:
mycomparison类中重载了operator(),当我们将元素插入堆时,比较器会决定哪个元素优先。- 在这个比较器中,返回
lhs.second > rhs.second,意味着优先级是按 频率升序 排列的,即频率最小的元素会被放到堆顶,这使得堆是一个 小顶堆。
综上:
priority_queue 声明了一个小顶堆,它存储一系列的 pair 元素,并通过自定义的 mycomparison 比较器来保证堆顶始终是频率最小的元素。通过这种方式,我们可以确保堆中始终保持频率最高的 k 个元素。
示例:
假设有以下 nums 数组:{1, 1, 1, 2, 2, 3},在堆中,元素可能会以如下方式存储:
pair(1, 3)表示元素1的频率为3pair(2, 2)表示元素2的频率为2pair(3, 1)表示元素3的频率为1
最终堆中的元素将按频率升序排列,在堆顶将是频率最小的元素(如 pair(3, 1))
2.优先级队列是单边队列吗
优先级队列(priority_queue)并不是单边队列。它和队列有不同的工作方式和数据结构特性。
区别:
-
队列(Queue):队列是一种 先进先出(FIFO) 数据结构,即元素按顺序插入和移除。你通常会从队列的尾部插入元素,从队列的头部移除元素。
- 基本操作:
push(x):将元素x插入队列的尾部。pop():从队列的头部移除元素。front():查看队列头部的元素。
- 基本操作:
-
优先级队列(
priority_queue):优先级队列是一种根据元素的优先级来决定其出队顺序的数据结构。并不像队列那样按插入顺序来移除元素,而是按照元素的优先级来移除。在 C++ 中,默认情况下priority_queue是一个 大顶堆,即每次移除元素时,都会移除优先级(通常是数值)最高的元素。你可以通过提供一个自定义的比较器来改变优先级队列的排序规则(例如变成小顶堆)。- 基本操作:
push(x):将元素x插入队列中,插入后会自动进行排序。pop():移除优先级最高的元素(对于大顶堆来说,是最大元素)(对于小顶堆来说,是最小元素)。top():查看优先级队列顶部的元素(优先级最高的元素)。
- 基本操作:
优先级队列 vs 单边队列:
-
单边队列(deque):单边队列是指具有双端操作的队列,可以在队列的两端插入或移除元素(
push_front(),push_back(),pop_front(),pop_back())。它并不按照元素的优先级排序,插入和移除的顺序是由操作顺序决定的。 -
优先级队列:与 单边队列 的双端操作不同,优先级队列只会从队列顶部按照优先级顺序移除元素,并没有显式的两端操作。它通常是一个 堆 数据结构,基于元素的优先级排序。
总结:
- 优先级队列 不是 单边队列,它的元素是按照优先级排序的,并且只有一端(堆顶)能进行元素的移除。
- 单边队列(deque) 支持两端的插入和删除,而 优先级队列 只关注优先级,移除和查看元素总是按照优先级顺序进行。
3.单边队列和双端队列有什么区别
单边队列(Queue) 和 双端队列(Deque) 都是线性数据结构,但它们在操作方式上有一些显著的区别。让我们详细看看它们之间的区别:
1. 定义:
-
单边队列(Queue):队列是一种 先进先出(FIFO) 的数据结构。元素只能在队列的一端(尾部)插入,在另一端(头部)移除。队列的操作遵循 FIFO(First In First Out) 原则,即先插入的元素会先被移除。
- 基本操作:
enqueue(x):将元素x添加到队列的尾部(插入)。dequeue():从队列的头部移除并返回元素。front():返回队列头部的元素,但不移除它。empty():检查队列是否为空。
- 基本操作:
-
双端队列(Deque):双端队列是一个可以在 两端(头部和尾部)插入和移除元素的队列。它支持 先进先出(FIFO) 和 后进先出(LIFO) 两种操作方式,因此它是 双端 的。
- 基本操作:
push_front(x):将元素x插入队列的前端。push_back(x):将元素x插入队列的后端。pop_front():从队列的前端移除并返回元素。pop_back():从队列的后端移除并返回元素。front():返回队列前端的元素。back():返回队列后端的元素。empty():检查队列是否为空。
- 基本操作:
2. 操作范围:
-
单边队列(Queue) 只有 一端插入,一端删除。即只能在队列的尾部插入元素,在队列的头部删除元素。
-
双端队列(Deque) 允许 两端插入和删除 元素,具有更大的灵活性。你可以选择在队列的前端或后端进行插入或删除。
3. 常见应用:
-
单边队列(Queue):
- 用于 任务调度、消息传递、缓冲区管理 等场景。
- 适用于需要 FIFO 顺序的应用,如打印任务管理、任务队列等。
-
双端队列(Deque):
- 用于需要两端插入和删除的场景,比如 滑动窗口 算法、缓存、双端队列排序 等。
- 适用于可以从两端操作数据的情况,如双端队列的应用包括双向消息队列、实现栈和队列的操作等。
4. 内存结构:
-
单边队列(Queue):通常使用 数组 或 链表 来实现。插入和删除操作只涉及队列的头部和尾部,时间复杂度是常数级别的(
O(1))。 -
双端队列(Deque):可以使用 双向链表 或 环形数组 来实现。由于可以在两端进行插入和删除,操作时间复杂度仍然是常数级别(
O(1))。
5. 空间复杂度:
-
单边队列(Queue):如果是基于 数组 实现,空间复杂度是
O(n),其中n是队列中的元素数目。如果是基于 链表 实现,空间复杂度也是O(n)。 -
双端队列(Deque):如果是基于 双向链表 或 环形数组 实现,空间复杂度同样是
O(n),因为它仍然需要存储n个元素。
6. 总结:
| 特性 | 单边队列(Queue) | 双端队列(Deque) |
|---|---|---|
| 插入位置 | 只能在队列尾部插入 | 可以在队列的前端或尾端插入 |
| 删除位置 | 只能从队列头部删除 | 可以从队列的前端或尾端删除 |
| 操作类型 | 只支持 FIFO(先进先出) | 支持 FIFO(先进先出)和 LIFO(后进先出) |
| 常见应用 | 任务调度、消息传递、缓冲区 | 滑动窗口、缓存、双端队列排序 |
4.优先级队列是大顶堆小顶堆吗
是的,优先级队列(priority_queue) 默认是基于 大顶堆(Max Heap) 实现的,也可以通过自定义比较规则实现 小顶堆(Min Heap)。
1. 大顶堆(Max Heap)
- 大顶堆是一种完全二叉树,根节点的值最大,且每个父节点的值都大于或等于其子节点的值。
- C++ 中的
priority_queue默认实现就是大顶堆,也就是说,优先级队列会优先处理最大值。 - 默认情况下,
priority_queue按照 元素值的大小 从大到小排序,也就是最大的元素优先出队。
大顶堆的特点:
- 堆顶的元素是最大的。
- 每次
pop操作都会删除并返回堆顶的最大元素。
2. 小顶堆(Min Heap)
- 小顶堆是一种完全二叉树,根节点的值最小,且每个父节点的值都小于或等于其子节点的值。
- 如果想要使用小顶堆,我们可以自定义比较规则,使得优先级队列按照 最小的元素优先出队。
- 为了实现小顶堆,我们需要反转默认的比较规则,通常通过自定义比较器来实现。
小顶堆的特点:
- 堆顶的元素是最小的。
- 每次
pop操作都会删除并返回堆顶的最小元素。
3. C++ 中如何使用大顶堆和小顶堆
-
默认的大顶堆:
priority_queue pq; // 默认是大顶堆
pq.push(5);
pq.push(1);
pq.push(3);
// 堆顶是最大的元素
cout << pq.top(); // 输出 5
pq.pop(); // 删除 5
- 小顶堆: 如果我们想要使用小顶堆,需要自定义一个比较规则。可以通过自定义
compare类或 lambda 表达式来实现。
// 小顶堆(Min Heap)
class mycomparison {
public:
bool operator()(int lhs, int rhs) {
return lhs > rhs; // 小顶堆:升序排列
}
};
priority_queue, mycomparison> pq; // 使用自定义比较器
pq.push(5);
pq.push(1);
pq.push(3);
// 堆顶是最小的元素
cout << pq.top(); // 输出 1
pq.pop(); // 删除 1
也可以使用 lambda 表达式简化代码:
priority_queue, greater> pq; // 使用 C++ STL 提供的 greater 比较器
pq.push(5);
pq.push(1);
pq.push(3);
// 堆顶是最小的元素
cout << pq.top(); // 输出 1
pq.pop(); // 删除 1
4. 总结:
- 优先级队列(
priority_queue) 在 C++ 中默认是 大顶堆(Max Heap),即堆顶是 最大 的元素。 - 如果需要 小顶堆(Min Heap),可以通过自定义比较规则来实现。
- 小顶堆是 根节点是最小元素,优先级队列会优先出队最小的元素。
通过自定义比较器或使用 C++ 标准库中的 greater 函数,我们可以轻松地实现小顶堆