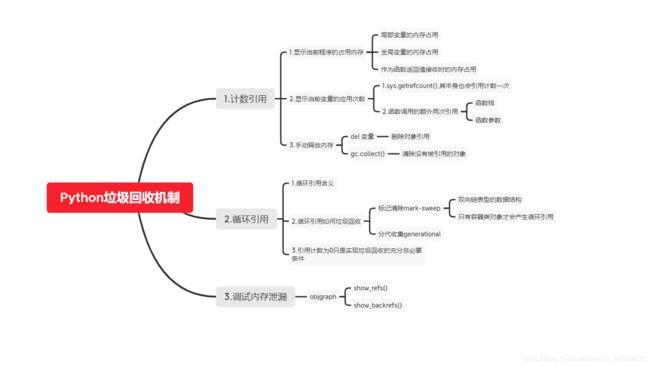
python垃圾回收
背景:
Python 程序在运行的时候,需要在内存中开辟出一块空间,用于存放运行时产生的临时变量,计算完成后,再将结果输出到永久性存储器中.如果数据量过大,内存空间管理不善就很容易出现 OOM(out of memory),俗称爆内存
简述python垃圾回收机制
python主要通过python垃圾器进行垃圾回收,python的垃圾回收主要基于引用计数,当一个对象的引用计数为0时,它会被回收,同时python还使用了标记清除和分代回收等自动回收算法解决python的循环引用,标记清除指定是python中维护着一个双向链表,通过遍历链表而进行标记,遍历结束,没有被标记的则会被清除,分带回收是指将所有对象分成三代,刚创立的对象是0代,经过一次垃圾回收后依然存在的对象就,便会依次上一代挪到下一代,当垃圾回收器中的新增对象减去删除对象达到相应阈值时,就会启动垃圾回收
1.引用计数
1.内存占用
局部变量
import os
import psutil
# 显示当前 python 程序占用的内存大小
def show_memory_info(hint):
pid = os.getpid()
p = psutil.Process(pid)
info = p.memory_full_info()
memory = info.uss / 1024. / 1024
print('{} memory used: {} MB'.format(hint, memory))
def func():
show_memory_info('initial')
a = [i for i in range(10000000)]
show_memory_info('after a created')
func()
show_memory_info('finished')
########## 输出 ##########
initial memory used: 47.19140625 MB
after a created memory used: 433.91015625 MB
finished memory used: 48.109375 MB
全局变量
def func():
show_memory_info('initial')
global a
a = [i for i in range(10000000)]
show_memory_info('after a created')
func()
show_memory_info('finished')
########## 输出 ##########
initial memory used: 48.88671875 MB
after a created memory used: 433.94921875 MB
finished memory used: 433.94921875 MB
函数返回值
def func():
show_memory_info('initial')
a = [i for i in derange(10000000)]
show_memory_info('after a created')
return a
a = func()
show_memory_info('finished')
########## 输出 ##########
initial memory used: 47.96484375 MB
after a created memory used: 434.515625 MB
finished memory used: 434.515625 MB
2.引用次数
1.getrefcount 本身也会引入一次计数
2.函数调用发生的时候,会产生额外的两次引用,一次来自函数栈,另一个是函数参数。
import sys
a = []
# 两次引用,一次来自 a,一次来自 getrefcount
print(sys.getrefcount(a))
def func(a):
# 四次引用,a,python 的函数调用栈,函数参数,和 getrefcount
print(sys.getrefcount(a))
func(a)
# 两次引用,一次来自 a,一次来自 getrefcount,函数 func 调用已经不存在
print(sys.getrefcount(a))
########## 输出 ##########
2
4
2
3.手动启动垃圾回收
1.del a 来删除对象的引用
2.gc.collect(),清除没有引用的对象
import gc
show_memory_info('initial')
a = [i for i in range(10000000)]
show_memory_info('after a created')
del a
gc.collect()
show_memory_info('finish')
print(a)
########## 输出 ##########
#
# initial memory used: 48.1015625 MB
# after a created memory used: 434.3828125 MB
# finish memory used: 48.33203125 MB
#
# ---------------------------------------------------------------------------
# NameError Traceback (most recent call last)
# in
# 11
# 12 show_memory_info('finish')
# ---> 13 print(a)
#
# NameError: name 'a' is not defined
2.循环引用
1.循环引用含义
如果有两个对象,它们互相引用,并且不再被别的对象所引用,引用计数始终不为0,导致不能被垃圾回收
2.循环引用如何垃圾回收
标记清除(mark-sweep)
对于一个有向图,如果从一个节点出发进行遍历,并标记其经过的所有节点,那么,在遍历结束后,所有没有被标记的节点,我们就称之为不可达节点,当然,每次都遍历全图,对于 Python 而言是一种巨大的性能浪费.所以在Python 的垃圾回收实现中,mark-sweep 使用双向链表维护了一个数据结构,并且只考虑容器类的对象(只有容器类对象才有可能产生循环引用)
分带回收(generational)
Python 将所有对象分为三代。刚刚创立的对象是第 0 代;经过一次垃圾回收后,依然存在的对象,便会依次从上一代挪到下一代。而每一代启动自动垃圾回收的阈值,则是可以单独指定的。当垃圾回收器中新增对象减去删除对象达到相应的阈值时,就会对这一代对象启动垃圾回收。
3.内存泄漏
objgraph一个非常好用的可视化引用关系的包,用于调试内存泄漏,第一个是 show_refs(),它可以生成清晰的引用关系图,另一个非常有用的函数,是 show_backrefs()
import objgraph
a = [1, 2, 3]
b = [4, 5, 6]
a.append(b)
b.append(a)
objgraph.show_refs([a])
objgraph.show_backrefs([a])
思考
实现一个垃圾回收判定算法:输入是一个有向图,给定起点,表示程序入口点,给定有向边,输出不可达节点
from typing import Set
class Graph:
def __init__(self, value, nodes=None):
self._value = value
self._nodes: list = [] if nodes is None else nodes
@property
def value(self):
return self._value
@property
def nodes(self):
return self._nodes
def node_add(self, node):
self._nodes.append(node)
def node_adds(self, nodes):
self._nodes.extend(nodes)
def node_del(self, node):
self._nodes.remove(node)
def __str__(self):
return "Graph {} nodes {}".format(self._value, [node.value for node in self.nodes])
def __repr__(self):
return self.__str__()
def dfs(start: Graph, includes: Set[Graph] = None) -> Set[Graph]:
if includes is None:
includes = set()
if start in includes:
return includes
includes.add(start)
for s in start.nodes:
includes.update(dfs(s, includes))
return includes
if __name__ == '__main__':
A = Graph('A')
B = Graph('B')
C = Graph('C')
D = Graph('D')
E = Graph('E')
F = Graph('F')
has_nodes = {A, B, C, D, E, F}
# A->B->E
# ->C->E
# B->A
# D->F
# F->D
A.node_adds([B, C])
B.node_adds([A, E])
C.node_adds([E])
D.node_adds([F])
F.node_adds([D])
graph_nodes = dfs(A, set())
# OUT: {Graph B nodes ['A', 'E'], Graph E nodes [], Graph C nodes ['E'], Graph A nodes ['B', 'C']}
print(graph_nodes)
# OUT: {Graph F nodes ['D'], Graph D nodes ['F']}
print(has_nodes - graph_nodes)