Transformer模型量化Quantization 笔记
模型参数与显存占用计算基础
为了详细说明模型的参数数量和每个参数在显存中占用的空间大小,我们以 facebook OPT-6.7B 模型为例。 逐步推理计算过程:
1. 估计参数总量:OPT-6.7B 模型指一个含有大约 6.7 Billion(67亿)个参数的模型。
2. 计算单个参数的显存占用:OPT-6.7B 模型默认使用 Float16,每个参数占用16位(即2字节)的显存。
3. 计算总显存占用 = 参数总量 × 每个参数的显存占用。 代入公式计算:
67亿参数×2字节/参数=134亿字节=13.4×109字节
4. 换算单位:1GB = 230B ≈ 109 字节
综上,OPT-6.7B 以 float16 精度加载到GPU需要使用大约13.5GB显存。 如果使用 int8 精度,则只需要大约7GB显存
GPTQ: 面向 Transformer 模型量化技术
GPTQ:Accurate Post-Training Quantization for Generative Pre-trained Transformers 是一个高效、精准的 量化技术,特别适用于大规模GPT模型,能够在显著降低模型大小和计算需求的同时,保持高准确度和推理速度。
GPTQ算法具有以下技术特点:
1. 专为GPT模型设计:GPTQ针对大规模GPT模型(如1750亿参数规模的模型)进行优化,解决了这类模型因 规模庞大导致的高计算和存储成本问题。
2. 一次性权重量化方法:GPTQ是一种基于近似二阶信息的权重量化方法,能够在一次处理中完成模型的量化。
3. 高效率:GPTQ能在大约四个GPU小时内完成1750亿参数的GPT模型的量化。
4. 低位宽量化:通过将权重位宽降至每个权重3或4位,GPTQ显著减少了模型的大小。
5. 准确度保持:即便在进行显著的位宽减少后,GPTQ也能保持与未压缩模型相近的准确度,减少性能损失。
6. 支持极端量化:GPTQ还可以实现更极端的量化,如2位或三元量化,同时保持合理的准确度。
7. 推理速度提升:使用GPTQ量化的模型在高端GPU(如NVIDIA A100)上实现了大约3.25倍的推理速度提升, 在成本效益更高的GPU(如NVIDIA A6000)上实现了大约4.5倍的速度提升。
8. 适用于单GPU环境:GPTQ使得在单个GPU内执行大规模模型的生成推理成为可能,显著降低了部署这类模 型的硬件要求
GPTQ 量化算法核心流程 核心步骤
使用存储在Cholesky(切尔斯基)分解中的逆Hessian(海森) 信息量化连续列的块(加粗表示),并在步骤结束时更新剩余的权重 (蓝色表示),在每个块内递归(白色中间块)地应用量化过程。 GPTQ量化过程的关键步骤操作,具体描述如下:
1.块量化:选择一块连续的列(在图中加粗表示),并将其作为当前步骤 的量化目标。
2.使用Cholesky分解:利用Cholesky分解得到的逆Hessian信息来量化选定 的块。Cholesky分解提供了一种数值稳定的方法来处理逆矩阵,这对于维 持量化过程的准确性至关重要。
3.权重更新:在每个量化步骤的最后,更新剩余的权重(在图中以蓝色表 示)。这个步骤确保了整个量化过程的连贯性和精确性。
4.递归量化:在每个选定的块内部,量化过程是递归应用的。这意味着量 化过程首先聚焦于一个较小的子块,然后逐步扩展到整个块。
通过这种方式,GPTQ方法能够在保持高度精度的同时,高效地处理大量 的权重,这对于大型模型的量化至关重要。这种策略特别适用于处理大 型、复杂的模型,如GPT系列,其中权重数量巨大,且量化过程需要特别 小心以避免精度损失。
激活感知权重量化(AWQ)算法 ( Activation-aware Weight Quantization, AWQ)
激活感知权重量化(AWQ)算法,其原理不是对模型中的所有权重进行量化,而是仅保留小部分(1%)对LLM性能 至关重要的权重。 其算法主要特点如下:
1. 低位权重量化:AWQ专为大型语言模型(LLMs)设计,支持低位(即少位数)的权重量化,有效减少模型大小。
2. 重点保护显著权重:AWQ基于权重重要性不均的观察,只需保护大约1%的显著权重,即可显著减少量化误差。
3. 观察激活而非权重:在确定哪些权重是显著的过程中,AWQ通过观察激活分布而非权重分布来进行。
4. 无需反向传播或重构:AWQ不依赖于复杂的反向传播或重构过程,因此能够更好地保持模型的泛化能力,避免对 特定数据集的过拟合。
5. 适用于多种模型和任务:AWQ在多种语言建模任务和领域特定基准测试中表现出色,包括指令调整的语言模型和 多模态语言模型。
6. 高效的推理框架:与AWQ配套的是一个为LLMs量身定做的高效推理框架,提供显著的速度提升,适用于桌面和 移动GPU。
7. 支持边缘设备部署:这种方法支持在内存和计算能力有限的边缘设备(如NVIDIA Jetson Orin 64GB)上部署大 型模型,如70B Llama-2模型。
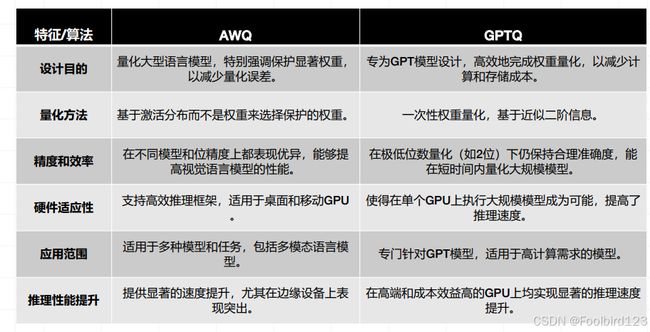
AWQ与GPTQ对比
使用 BitsAndBytes (bnb)快速实现参数精度量化
BitsAndBytes(BNB)是自定义 CUDA 函数的轻量级包装器,特别是 8 比特优化器、矩阵乘法和量 化函数。
主要特征如下:
• 具有混合精度分解的 8 比特矩阵乘法 • LLM.int8() 推理
• 8 比特优化器:Adam、AdamW、RMSProp、LARS、LAMB、Lion(节省 75% 内存)
• 稳定的嵌入层:通过更好的初始化和标准化提高稳定性
• 8 比特量化:分位数、线性和动态量化 • 快速的分位数估计:比其他算法快 100 倍 在 Transformers 量化方案中,BNB 是将模型量化为8位和4位的最简单选择。
• 8位量化将fp16中的异常值与int8中的非异常值相乘,将非异常值转换回fp16,然后将它们相加以 返回fp16中的权重。这减少了异常值对模型性能产生的降级效果。
• 4位量化进一步压缩了模型,并且通常与QLoRA一起用于微调量化LLM(低精度语言模型)。