机器学习01
机器学习的基本过程如下:
1.数据获取
2.数据划分
3.特征提取
4.模型选择与训练
5.模型评估
6.模型调优
一、特征工程(重点)
0. 特征工程步骤为:
-
特征提取(如果不是像dataframe那样的数据,要进行特征提取,比如字典特征提取,文本特征提取)
-
无量纲化(预处理)
-
归一化
-
标准化
-
-
降维
-
底方差过滤特征选择
-
主成分分析-PCA降维
-
1. 特征工程API
-
实例化转换器对象,转换器类有很多,都是Transformer的子类, 常用的子类有:
DictVectorizer 字典特征提取
CountVectorizer 文本特征提取
TfidfVectorizer TF-IDF文本特征词的重要程度特征提取
MinMaxScaler 归一化
StandardScaler 标准化
VarianceThreshold 底方差过滤降维
PCA 主成分分析降维fit() 方法s
在 scikit - learn 库中,fit 方法计算的内容与具体的转换器(如数据预处理、特征提取等工具)以及输入的数据密切相关。
- 功能:
fit()方法的主要作用是从输入数据中学习统计信息或模式。具体来说,它会根据输入的数据计算出一些必要的参数,这些参数将用于后续的转换操作。例如,在StandardScaler中,fit()方法会计算输入数据的均值和标准差
transform() 方法
- 功能:
transform()方法使用fit()方法学习到的参数对输入数据进行转换。它会根据之前计算得到的统计信息或模式,将输入数据转换为新的表示形式。例如,在StandardScaler中,transform()方法会使用之前计算的均值和标准差对输入数据进行标准化处理
fit_transform() 方法
- 功能:
fit_transform()方法是fit()和transform()方法的组合。它首先调用fit()方法从输入数据中学习参数,然后立即使用这些参数对输入数据进行转换。这个方法通常用于在训练数据上进行特征工程,因为它可以更简洁地完成学习和转换的过程。
2. DictVectorizer 字典列表特征提取
(1) API
-
创建转换器对象:
sklearn.feature_extraction.DictVectorizer(sparse=True)参数:
sparse=True返回类型为csr_matrix的稀疏矩阵
sparse=False表示返回的是数组,数组可以调用.toarray()方法将稀疏矩阵转换为数组
-
转换器对象:
转换器对象调用fit_transform(data)函数,参数data为一维字典数组或一维字典列表,返回转化后的矩阵或数组
转换器对象get_feature_names_out()方法获取特征名
稀疏矩阵转为数组
稀疏矩阵对象调用toarray()函数, 得到类型为ndarray的二维稀疏矩阵
3. CountVectorizer 文本特征提取
(1)API
sklearn.feature_extraction.text.CountVectorizer
构造函数关键字参数stop_words,值为list,表示词的黑名单(不提取的词)
fit_transform函数的返回值为稀疏矩阵
4. TfidfVectorizer TF-IDF文本特征词的重要程度特征提取
(1) 算法
词频(Term Frequency, TF), 表示一个词在当前篇文章中的重要性
逆文档频率(Inverse Document Frequency, IDF), 反映了词在整个文档集合中的稀有程度

(2) API
sklearn.feature_extraction.text.TfidfVectorizer()
构造函数关键字参数stop_words,表示词特征黑名单
fit_transform函数的返回值为稀疏矩阵
5. 无量纲化-预处理
无量纲,即没有单位的数据
(1) MinMaxScaler 归一化
通过对原始数据进行变换把数据映射到指定区间(默认为0-1)
<1>归一化公式:
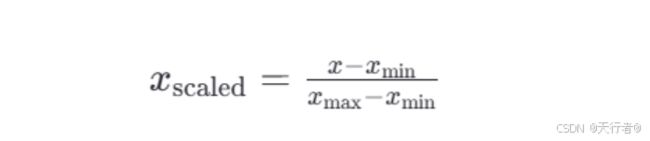
这里的 min 和 max 分别是每种特征中的最小值和最大值,而 是当前特征值,scaled 是归一化后的特征值。
若要缩放到其他区间,可以使用公式:x=x*(max-min)+min;
<2>归一化API
sklearn.preprocessing.MinMaxScaler(feature_range)
参数:feature_range=(0,1) 归一化后的值域,可以自己设定
fit_transform函数归一化的原始数据类型可以是list、DataFrame和ndarray, 不可以是稀疏矩阵
fit_transform函数的返回值为ndarray
<3>缺点
最大值和最小值容易受到异常点影响,所以鲁棒性较差。所以常使用标准化的无量纲化
(2)normalize归一化
API
from sklearn.preprocessing import normalize
normalize(data, norm='l2', axis=1)
#data是要归一化的数据
#norm是使用那种归一化:"l1" "l2" "max<1> L1归一化
绝对值相加作为分母,特征值作为分子
<2> L2归一化
平方相加再开方作为分母,特征值作为分子
<3> max归一化
绝对值max作为分母,特征值作为分子
(3)StandardScaler 标准化
在机器学习中,标准化是一种数据预处理技术,也称为数据归一化或特征缩放。它的目的是将不同特征的数值范围缩放到统一的标准范围,以便更好地适应一些机器学习算法,特别是那些对输入数据的尺度敏感的算法。
<1>标准化公式
最常见的标准化方法是Z-score标准化,也称为零均值标准化。它通过对每个特征的值减去其均值,再除以其标准差,将数据转换为均值为0,标准差为1的分布。这可以通过以下公式计算:
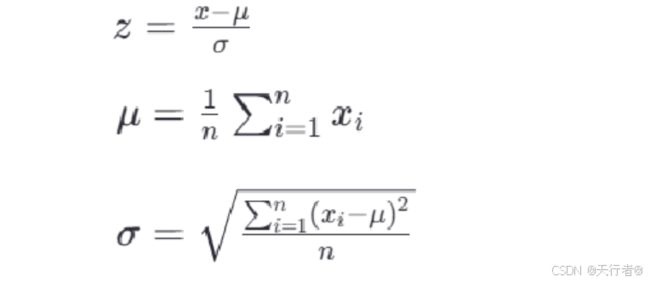
<2> 标准化 API
sklearn.preprocessing.StandardScale与MinMaxScaler一样,原始数据类型可以是list、DataFrame和ndarray
fit_transform函数的返回值为ndarray, 归一化后得到的数据类型都是ndarray
from sklearn.preprocessing import StandardScaler
#不能加参数feature_range=(0, 1)
transfer = StandardScaler()
data_new = transfer.fit_transform(data) #data_new的类型为ndarray注意点:
一旦scaler对象在X_train上被fit,它就已经知道了如何将数据标准化。这时,对于测试集X_test,我们只需要使用transform方法,因为我们不希望在测试集上重新计算任何统计信息,也不希望测试集的信息影响到训练过程。如果我们对X_test也使用fit_transform,测试集的信息就可能会影响到训练过程。
总结来说:我们常常是先fit_transform(x_train)然后再transform(x_text)
稀疏矩阵处理
- 不适用稀疏矩阵:
StandardScaler会将数据进行中心化处理,这会破坏稀疏矩阵的稀疏性,导致内存占用大幅增加。如果数据是稀疏矩阵,应该使用MaxAbsScaler或Normalizer等更适合稀疏数据的缩放方法。
6. 特征降维
特征降维其目的:是减少数据集的维度,同时尽可能保留数据的重要信息。
特征降维的好处:
减少计算成本:在高维空间中处理数据可能非常耗时且计算密集。降维可以简化模型,降低训练时间和资源需求。
去除噪声:高维数据可能包含许多无关或冗余特征,这些特征可能引入噪声并导致过拟合。降维可以帮助去除这些不必要的特征。
特征降维的方式:
-
特征选择
-
从原始特征集中挑选出最相关的特征
-
-
主成份分析(PCA)
-
主成分分析就是把之前的特征通过一系列数学计算,形成新的特征,新的特征数量会小于之前特征数量
-
1 .特征选择
(a) VarianceThreshold 低方差过滤特征选择
-
Filter(过滤式): 主要探究特征本身特点, 特征与特征、特征与目标 值之间关联
-
方差选择法: 低方差特征过滤
如果一个特征的方差很小,说明这个特征的值在样本中几乎相同或变化不大,包含的信息量很少,模型很难通过该特征区分不同的对象,比如区分甜瓜子和咸瓜子还是蒜香瓜子,如果有一个特征是长度,这个特征相差不大可以去掉。
-
计算方差:对于每个特征,计算其在训练集中的方差(每个样本值与均值之差的平方,在求平均)。
-
设定阈值:选择一个方差阈值,任何低于这个阈值的特征都将被视为低方差特征。
-
过滤特征:移除所有方差低于设定阈值的特征
-
-
(b) 根据相关系数的特征选择
scipy.stats.personr(x, y) 计算两特征之间的相关性
返回对象有两个属性:
statistic皮尔逊相关系数[-1,1]
pvalue零假设(了解),统计上评估两个变量之间的相关性,越小越相关
2.主成份分析(PCA)
主成分分析的核心思想是通过线性变换将原始数据投影到一组新的正交坐标轴上,这些新的坐标轴被称为主成分。第一个主成分方向是数据方差最大的方向,第二个主成分方向是与第一个主成分正交且方差次大的方向,以此类推。通过保留方差较大的主成分,可以在尽量保留数据信息的前提下,减少数据的维度。
PCA
-
from sklearn.decomposition import PCA
-
PCA(n_components=None)
-
主成分分析
-
n_components:
-
实参为小数时:表示降维后保留百分之多少的信息
-
实参为整数时:表示减少到多少特征
-
-
计算步骤
- 数据标准化:对原始数据进行标准化处理,使得每个特征的均值为 0,标准差为 1。这是因为 PCA 是基于数据的协方差矩阵进行计算的,如果特征的尺度不同,会导致协方差矩阵受尺度较大的特征影响较大。
- 计算协方差矩阵:计算标准化后数据的协方差矩阵,协方差矩阵反映了各个特征之间的相关性。
- 特征分解:对协方差矩阵进行特征分解,得到特征值和特征向量。特征值表示对应主成分的方差大小,特征向量表示主成分的方向。
- 选择主成分:根据特征值的大小对特征向量进行排序,选择前 k 个特征值对应的特征向量作为主成分,其中 k 是降维后数据的维度。
- 数据投影:将标准化后的数据投影到选择的主成分上,得到降维后的数据。
优缺点
优点:
- 数据降维:可以有效减少数据的维度,降低计算复杂度,同时保留数据的主要信息。
- 去除相关性:通过将数据投影到主成分上,消除了特征之间的相关性,使得数据更加易于分析和处理。
- 数据可视化:对于高维数据,可以通过保留前 2 个或 3 个主成分,将数据可视化到二维或三维空间中,便于观察数据的分布和结构。
缺点:
- 信息损失:降维过程中会不可避免地损失一部分信息,尤其是当选择的主成分数量较少时,损失的信息可能会较多。
- 解释性较差:主成分通常是原始特征的线性组合,其物理意义可能不明确,导致模型的解释性较差。
- 对异常值敏感:PCA 是基于数据的协方差矩阵进行计算的,异常值会对协方差矩阵产生较大影响,从而影响主成分的计算结果。
应用场景
- 数据降维:在处理高维数据时,如基因数据、图像数据等,PCA 可以将数据的维度降低,减少计算量和存储需求。
- 特征提取:通过提取主成分,可以得到数据的主要特征,用于后续的分类、回归等任务。
- 数据可视化:将高维数据降维到二维或三维空间,便于直观地观察数据的分布和聚类情况。
二、KNN算法
K-近邻算法(K-Nearest Neighbors,简称KNN),根据K个邻居样本的类别来判断当前样本的类别;
如果一个样本在特征空间中的k个最相似(最邻近)样本中的大多数属于某个类别,则该类本也属于这个类别
KNN缺点
对于大规模数据集,计算量大,因为需要计算测试样本与所有训练样本的距离。
对于高维数据,距离度量可能变得不那么有意义,这就是所谓的“维度灾难”
需要选择合适的k值和距离度量,这可能需要一些实验和调整
API
class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, algorithm='auto')
参数:
(1)n_neighbors:
int, default=5, 默认情况下用于kneighbors查询的近邻数,就是K
(2)algorithm:
{‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}, default=’auto’。找到近邻的方式,注意不是计算距离 的方式,与机器学习算法没有什么关系,开发中请使用默认值'auto'
方法:
(1) fit(x, y)
使用X作为训练数据和y作为目标数据
(2) predict(X) 预测提供的数据,得到预测数据 在葡萄酒分类代码示例中,只对特征矩阵 X 进行标准化处理,而没有对目标变量 Y 进行标准化,主要有以下几方面原因:
目标变量的性质
- 分类问题的目标变量:在这个葡萄酒分类任务中,目标变量
Y代表葡萄酒的类别标签(例如不同的葡萄酒品种),属于离散的分类数据。标准化通常是针对连续的数值型数据,目的是让数据具有零均值和单位方差。而对于分类数据,每个类别都有其特定的含义,不存在数值上的大小、距离等连续的概念,对其进行标准化没有实际意义。例如,葡萄酒的类别 1、2、3 只是不同类别之间的区分标识,对这些数字进行标准化处理并不会改变类别之间的本质差异,也不会对模型的分类性能产生积极影响。 - 标准化对分类结果无帮助:分类模型(如 K 近邻分类器)是基于特征之间的距离或相似性来判断样本所属的类别,目标变量的类别信息是明确的分类标识,不需要通过标准化来调整。只要模型能够正确学习到特征与类别之间的映射关系,就可以进行准确的分类预测。
模型的要求
- 分类模型的输入要求:大多数分类模型(包括 K 近邻分类器)都可以直接处理离散的类别标签作为目标变量。这些模型在训练过程中会根据特征和类别标签之间的对应关系来构建分类规则,而不需要对类别标签进行额外的转换或标准化。如果对目标变量进行标准化,可能会破坏类别之间的原有信息,导致模型无法正确理解和处理这些数据。
对比回归问题
- 回归问题的目标变量:在回归问题中,目标变量通常是连续的数值型数据,如预测房价、股票价格等。在这种情况下,对目标变量进行标准化可能有助于提高模型的训练效率和性能,因为标准化可以使目标变量的取值范围更加合理,避免某些数值过大或过小对模型训练产生不良影响。但对于分类问题,目标变量的性质与回归问题不同,因此不需要进行标准化处理。
综上所述,在分类任务中,一般不需要对目标变量进行标准化处理,重点是对特征矩阵进行适当的预处理,以提高模型的性能和稳定性。