Design Uber
Design Uber
Functional Requirement
- User is able to input a source & destination to get an estimate
- User is able to request and match a driver to get to the desination
- Driver will accept the request and drop off/ pick up the user
Non-Functional Request
- Matching is fast < 5s
-> Driver update location should be fast, fast to get surrounding locations - We need to maintain the constistency, 2 users can’t be matched to a single driver
- handle great throughput especially during rush hour
Core Entities
User, Driver, Location, Ride, Fare
API Design
User:
POST /fare
{
sourceLocation,
destination
}
->return Partial[Ride]
POST /match
{
FareId
}
-> return DriverId
POST /accept
{
Response
}
Driver
POST /locations
{
long,
lat,
}
注意这里我并没有加入userid, 因为这些data会成为JWT的一部分
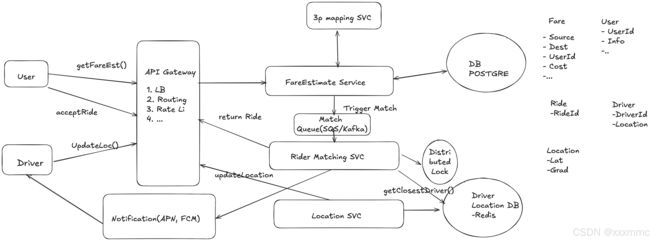
High level design
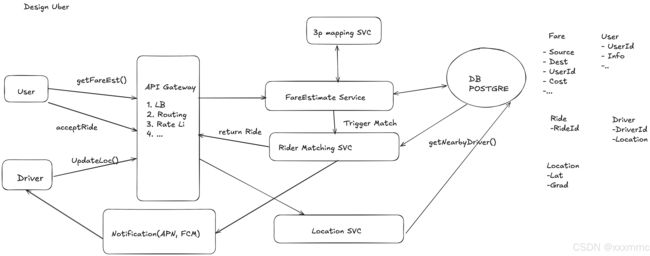
data flow介绍一下
Dive Deep
Q1:Driver update fast?
since the QPS is like pretty high, we need to seek some in-memory solutions.
We can use redis to update.
- Redis has TTL
- Redis has
GEORADIUSto get the nearby drivers
challenge, 是Redis是in-memory的然后我需要不断的持久化using redis dabase, 来防止redis service down了
在very high frequency 里面,
客户端也可以有一些优化,算法可以提前计算那些人到哪里,比如说速度比较低的时候,那我send的速度就慢一些,
上述的redis同样解决了matching need fast的问题,GEORADIUS is quick.
Q2:如何阻止2 users can’t be matched to a single driver?
我们用redis来做一个distributed lock. redis中存储id,然后有个ttl, 大概设置成10s(after 10s 自动释放这个锁),如果匹配成功那么database中的ride要写成accept,释放这个锁
Q3:如何确保在rush hour的时候no ride requests are dropped during peak demand periods?
我们需要一个message queue,比如kafka,确保消息被consume了(which allows us to commit the offset of the message in the queue only after we have successfully found a match)
没有成功处理完的请求会留在kafka中, match queue以一个priority queue来做(FIFO queue的话
Q4:我要怎么对整个系统reduce latency,提高throughput要怎么办?
我需要scale horizontally,增加更多的server,那么就要sharding based on geo,如果你想得到在边界上的点周围的司机,可能需要query multiple shards.
为了sharding evenly,我需要consistant hashing。
这里的话是先sharding based on geo,然后对每个geo,再分片的时候要用到consistant hashing.
consistant hashing是一种hash方法,把这个hash方法的output(32位/64位的数)映射到一个环上。
把服务器a,b,c以及数据 key1, key 2…一起放到环上,然后数据放在哪里取决于向下面找到的那个服务器的值。
更高阶的方法是,a,b,c 映射成a0, a1, a2, 这3个服务器对应300个环上的点,然后数据向上
一样的意思存放。负载均衡
Updated Design