编码与字符集
知识点1
图片展示了一段 Python 代码,该代码演示了如何将一个包含中文字符的字符串使用不同的编码方式转换为字节序列(bytes)。具体来说,代码将字符串 "陈浩" 分别用 GBK 和 UTF-8 编码进行了编码,并打印出了编码后的结果。
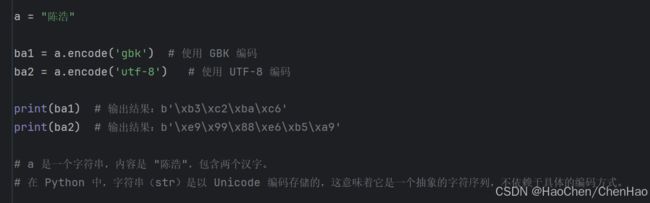
GBK 编码:
GBK 编码 GBK 是一种用于简体中文的字符编码,它扩展自 GB2312 编码,能够支持更多的中文字符。 "陈" 在 GBK 编码中的字节表示为 \xb3\xc2。 "浩" 在 GBK 编码中的字节表示为 \xba\xc6。 因此,当你使用 encode('gbk') 方法将 "陈浩" 编码为 GBK 时,得到的字节序列是 b'\xb3\xc2\xba\xc6'。
UTF-8编码
UTF-8 编码 UTF-8 是一种变长字符编码,可以表示 Unicode 字符集中的所有字符。它使用 1 到 4 个字节来表示一个字符,具体取决于字符的 Unicode 码点。 "陈" 的 Unicode 码点是 U+96C5,在 UTF-8 编码中占用 3 个字节,表示为 \xe9\x99\x88。 "浩" 的 Unicode 码点是 U+6F02,在 UTF-8 编码中也占用 3 个字节,表示为 \xe6\xb5\xa9。 因此,当你使用 encode('utf-8') 方法将 "陈浩" 编码为 UTF-8 时,得到的字节序列是 b'\xe9\x99\x88\xe6\xb5\xa9'。
解释字节序列
在 Python 中,字节序列(bytes)使用 b 前缀表示,每个字节用两个十六进制数字表示。 例如,b'\xe9\x99\x88' 表示三个字节,分别是 \xe9、\x99 和 \x88。
使用不同编码的原因:
不同的编码方式适用于不同的场景:
GBK:主要用于简体中文环境,可以很好地支持中文字符,但不支持其他语言的字符。
UTF-8:是一种通用的编码方式,可以表示世界上几乎所有的字符,是互联网上最常用的编码方式。
小结
字符串 "陈浩" 编码后得到特定的字节序列,是因为不同的编码方式将字符映射到不同的字节值。GBK 和 UTF-8 编码方式分别将 "陈浩" 映射到 b'\xb3\xc2\xba\xc6' 和 b'\xe9\x99\x88\xe6\xb5\xa9'。这些字节序列代表了字符在计算机中的存储形式,使得字符可以在不同的系统和网络中正确传输和显示。
知识点2

1. 解码 GBK 字节序列:
ba1.decode('gbk'):将 GBK 编码的字节序列 ba1 解码为字符串。这一步需要指定原始编码方式(这里是 GBK),以便正确地将字节转换为字符。
2. 打印解码后的字符串:
print(a):输出解码后的字符串,这是原始的中文字符。
3. 编码为 UTF-8 字节序列:
a.encode('utf-8'):将解码后的字符串重新编码为 UTF-8 编码的字节序列。这一步将字符串转换为可以在不同环境中传输和存储的字节形式。
4. 打印编码后的字节序列:
print(ba2):输出编码后的 UTF-8 字节序列,这是字符串在 UTF-8 编码下的字节表示。
知识点3
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是一种基于拉丁字母的字符编码标准,用于电子设备和计算机之间的文本数据交换。ASCII 是一种非常早期的字符编码系统,它使用7位或8位二进制数来表示字符,因此最多可以表示128个不同的字符。
ASCII 字符集特点:
1. 字符数量:
ASCII 编码可以表示 128 个不同的字符,包括: 大写英文字母(A-Z) 小写英文字母(a-z) 数字(0-9) 标点符号和控制字符(如空格、逗号、句号、换行符等)
2. 二进制表示:
每个字符由7位二进制数表示,范围从0到127。在计算机中,通常使用8位(一个字节)来存储 ASCII 字符,最高位(第8位)通常用作奇偶校验位或用于扩展 ASCII。
3. 控制字符:
ASCII 编码中包括一些控制字符,如换行(LF,ASCII码为10)、回车(CR,ASCII码为13)、制表符(Tab,ASCII码为9)等,这些字符用于控制文本的格式和布局。
ASCII 字符集示例:
大写字母 'A' 的 ASCII 码是 65,二进制表示为 01000001。
小写字母 'a' 的 ASCII 码是 97,二进制表示为 01100001。
数字 '0' 的 ASCII 码是 48,二进制表示为 00110000。
空格的 ASCII 码是 32,二进制表示为 00100000。
知识点4
1. ANSI编码概述 ANSI编码并不是一个单一的编码标准,
是指由美国国家标准协会(American National Standards Institute)制定的一系列字符集和编码标准。这些标准包括了多种语言的字符集,并且根据不同地区的需要发展出了不同的代码页(Code Pages)。
2. ANSI编码的特点:
与ASCII的关系:ANSI编码是对ASCII(0x00–0x7F)的扩展。ASCII字符用1个字节表示,范围是0x00–0x7F。ANSI的扩展部分使用0x80–0xFF,用单字节或多字节表示额外字符。 字节长度:英文环境下(如Windows-1252)每个字符用1个字节表示。中文环境下(如GB2312/GBK)ASCII字符用1个字节,汉字等扩展字符用2个字节。 地区依赖性:ANSI编码是基于区域设置的。例如,在英文Windows中,ANSI使用Windows-1252。在中文Windows中,ANSI使用GB2312或GBK。
常见ANSI代码页
CP1252:主要用于西欧国家,支持拉丁文字符。
CP936:中文简体编码,常用于Windows简体中文版。
CP950:中文繁体编码,常用于Windows繁体中文版。
CP1251:主要用于西里尔字母国家。
ANSI编码与Unicode编码的区别
范围:ANSI编码通常基于单字节编码,最多能表示256个字符,而Unicode编码支持全球所有字符(码点范围U+0000–U+10FFFF)。
字节数:ANSI编码使用单字节或双字节,而Unicode编码可变长度(UTF-8)或固定长度(UTF-16/UTF-32)。
地区依赖性:ANSI编码是地区相关的,字符集取决于操作系统区域设置。Unicode编码无地区依赖,统一字符集。
支持语言:ANSI编码仅支持部分语言(如英语、部分中文),而Unicode编码支持所有语言。
编码方式:ANSI编码单字节为主,扩展到多字节(如GBK双字节编码)。Unicode编码有UTF-8、UTF-16、UTF-32等多种编码方式
知识点5
Unicode 是一个国际标准,旨在为世界上所有的书写系统提供一个统一的编码方案。Unicode 让每个字符,无论它属于哪种语言或符号集,都有一个唯一的数字编码。这个标准支持超过 100,000 个字符,涵盖了世界上几乎所有的书写系统,包括拉丁字母、希腊字母、阿拉伯字母、汉字、日文假名、韩文谚文等。
Unicode 的重要性
全球通信:Unicode 使得不同语言和文化之间的数字通信成为可能,无需担心字符无法显示或错误显示。
软件国际化:Unicode 支持使软件能够处理多种语言,这对于开发全球软件产品至关重要。
数据存储:Unicode 提供了一种统一的方式来存储文本数据,无论文本使用哪种语言或符号。
Unicode 编码形式
Unicode 字符可以用不同的编码形式表示,常见的有:
UTF-8:
变长编码,使用1到4个字节来表示一个字符。 兼容ASCII,英文字符使用1个字节,其他字符使用更多字节。 网络传输中最常用的编码,因为它对英文文本来说非常高效。
UTF-16:
变长编码,使用2个或4个字节来表示一个字符。 主要用于需要固定宽度字符集的系统,如某些旧的操作系统。
UTF-32:
固定长度编码,始终使用4个字节来表示一个字符。 由于其固定长度的特性,处理起来较为简单,但在存储空间上可能不够高效。
Unicode 在编程中的应用
在编程中,Unicode 通常用于处理文本数据,特别是在需要支持多语言的环境中。不同的编程语言提供了不同的方法来处理 Unicode 字符和字符串:
Python:从Python 3开始,所有的字符串都是Unicode字符串。可以使用encode()和decode()方法在Unicode和不同的UTF编码之间转换。
Java:Java使用String类来处理Unicode字符串,内部使用UTF-16编码。
C#:C#中的字符串也是基于Unicode的,使用UTF-16编码。
Unicode 的挑战
尽管Unicode提供了一个强大的解决方案来统一字符编码,但在实际应用中仍然面临一些挑战:
兼容性:旧系统和软件可能不支持Unicode,导致兼容性问题。
性能:UTF-8等变长编码在处理大量文本时可能比固定长度编码更高效,但在某些情况下(如内存对齐)可能会影响性能。
混淆:由于Unicode字符可以有多种表示方式(如不同的规范化形式),这可能导致文本比较和处理上的混淆。