MySQL进阶篇 === 索引分类
目录
索引分类
思考题
语法
索引分类与使用总结
一、索引类型
二、InnoDB存储引擎的索引存储形式
三、聚集索引选取规则
四、思考题解答
五、索引的语法
六、案例分析
索引分类
| 分类 | 含义 | 特点 | 关键字 |
|---|---|---|---|
| 主键索引 | 针对于表中主键创建的索引 | 默认自动创建,只能有一个 | PRIMARY |
| 唯一索引 | 避免同一个表中某数据列中的值重复 | 可以有多个 | UNIQUE |
| 常规索引 | 快速定位特定数据 | 可以有多个 | |
| 全文索引 | 全文索引查找的是文本中的关键词,而不是比较索引中的值 | 可以有多个 | FULLTEXT |
在 InnoDB 存储引擎中,根据索引的存储形式,又可以分为以下两种:
| 分类 | 含义 | 特点 |
|---|---|---|
| 聚集索引(Clustered Index) | 将数据存储与索引放一块,索引结构的叶子节点保存了行数据 | 必须有,而且只有一个 |
| 二级索引(Secondary Index) | 将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键 | 可以存在多个 |
演示图:
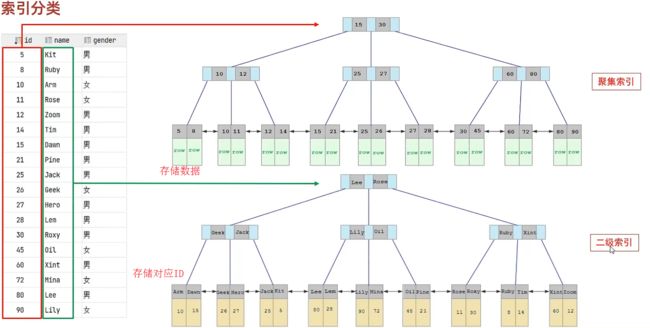
聚集索引选取规则:
- 如果存在主键,主键索引就是聚集索引
- 如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引
- 如果表没有主键或没有合适的唯一索引,则 InnoDB 会自动生成一个 rowid 作为隐藏的聚集索引
思考题
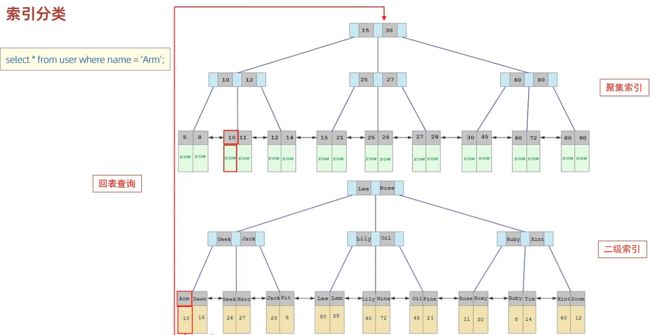
1. 以下 SQL 语句,哪个执行效率高?为什么?
select * from user where id = 10;
select * from user where name = 'Arm';
-- 备注:id为主键,name字段创建的有索引
答:第一条语句,因为第二条需要回表查询,相当于两个步骤。
2. InnoDB 主键索引的 B+Tree 高度为多少?
答:假设一行数据大小为1k,一页中可以存储16行这样的数据。InnoDB 的指针占用6个字节的空间,主键假设为bigint,占用字节数为8.
可得公式:n * 8 + (n + 1) * 6 = 16 * 1024,其中 8 表示 bigint 占用的字节数,n 表示当前节点存储的key的数量,(n + 1) 表示指针数量(比key多一个)。算出n约为1170。
如果树的高度为2,那么他能存储的数据量大概为:1171 * 16 = 18736;
如果树的高度为3,那么他能存储的数据量大概为:1171 * 1171 * 16 = 21939856。
另外,如果有成千上万的数据,那么就要考虑分表,涉及运维篇知识。
语法
创建索引:
CREATE [ UNIQUE | FULLTEXT ] INDEX index_name ON table_name (index_col_name, ...);
如果不加 CREATE 后面不加索引类型参数,则创建的是常规索引
查看索引:
SHOW INDEX FROM table_name;
删除索引:
DROP INDEX index_name ON table_name;
案例:
- Table: 表名,这里是
tb_user。 - Non_unique: 索引是否唯一,
0表示该索引是唯一的。 - Key_name: 索引名,这里显示为
PRIMARY,表示这是一个主键索引。 - Seq_in_index: 列在索引中的顺序,
1表示这是索引中的第一个列。 - Column_name: 索引列的名称,这里是
id。 - Collation: 索引列的排序规则,这里是
A,通常表示升序。 - Cardinality: 索引列中唯一值的估计数量,这里是
0,表示没有估计值或该值未知。 - Sub_part: 索引列的前缀长度,这里是
NULL,表示没有使用前缀索引。 - Packed: 索引是否被压缩存储,这里是
NULL,表示没有相关信息。 - Null: 索引列是否允许
NULL值,这里是NULL,表示没有相关信息。 - Index_type: 索引的类型,这里是
BTREE,表示使用的是B树索引。 - Index_comment: 索引的注释,这里是空的。
- Visible: 索引是否可见,
YES表示索引是可见的。 - Expression: 索引列的表达式,这里是
(NULL),表示没有使用表达式索引。
CREATE TABLE tb_user (
id INT PRIMARY KEY,
name VARCHAR(50),
phone VARCHAR(15),
email VARCHAR(50),
profession VARCHAR(50),
age INT,
gender TINYINT,
status TINYINT,
createtime DATETIME
);
INSERT INTO tb_user (id, name, phone, email, profession, age, gender, status, createtime) VALUES
(1, '吕布', '17799999000', '[email protected]', '软件工程', 23, 1, 6, '2001-02-02 00:00:00'),
(2, '曹操', '17799999001', '[email protected]', '通讯工程', 33, 1, 0, '2001-03-05 00:00:00'),
(3, '赵云', '17799999002', '17799990819.com', '英语', 34, 1, 2, '2002-03-02 00:00:00'),
(4, '孙尚香', '17799999003', '177999908sina.com', '工程造价', 54, 1, 0, '2001-07-02 00:00:00'),
(5, '花木兰', '17799999004', '[email protected]', '软件工程', 23, 2, 1, '2001-04-22 00:00:00'),
(6, '大乔', '17799999005', '[email protected]', '舞蹈', 22, 2, 0, '2001-02-07 00:00:00'),
(7, '露娜', '17799999006', '[email protected]', '应用数学', 24, 2, 0, '2001-02-08 00:00:00'),
(8, '程咬金', '17799999007', '[email protected]', '化工', 38, 1, 0, '2001-05-23 00:00:00'),
(9, '项羽', '17799999008', '[email protected]', '金属材料', 43, 1, 0, '2001-09-18 00:00:00'),
(10, '白起', '17799999009', '[email protected]', '机械工程及其自动化', 27, 1, 2, '2001-08-16 00:00:00'),
(11, '韩信', '17799999010', '[email protected]', '无机非金属材料工程', 27, 1, 0, '2001-06-12 00:00:00'),
(12, '荆轲', '17799999011', '[email protected]', '会计', 29, 1, 0, '2001-05-11 00:00:00'),
(13, '兰陵王', '17799999012', '[email protected]', '工程造价', 44, 1, 0, '2001-04-09 00:00:00'),
(14, '狂铁', '17799999013', '[email protected]', '应用数学', 22, 1, 0, '2001-04-10 00:00:00'),
(15, '貂蝉', '17799999014', '[email protected]', '软件工程', 40, 2, 3, '2001-02-12 00:00:00'),
(16, '妲己', '17799999015', '[email protected]', '软件工程', 31, 2, 0, '2001-01-30 00:00:00'),
(17, '芈月', '17799999016', '[email protected]', '工业经济', 35, 2, 0, '2000-05-03 00:00:00')
-- 查看索引
SHOW INDEX FROM tb_user;
-- name字段为姓名字段,该字段的值可能会重复,为该字段创建索引
CREATE INDEX idx_user_name ON tb_user(name)
-- phone手机号字段的值非空,且唯一,为该字段创建唯一索引
CREATE UNIQUE INDEX idx_user_phone ON tb_user(phone)
-- 为profession, age, status创建联合索引
CREATE INDEX idx_pro_age_sta ON tb_user(profession,age,status)
-- 为email建立合适的索引来提升查询效率
CREATE INDEX idx_user_email ON tb_user(email)
-- 删除索引
DROP INDEX idx_user_email ON tb_user
索引分类与使用总结
一、索引类型
-
主键索引:
-
特点:每个表只能有一个,且会自动创建。通常用于唯一标识表中的每一行记录。
-
用途:确保数据的唯一性,并且可以快速地定位特定数据行。
-
-
唯一索引:
-
特点:可以有多个,用于确保某列或多列中的数据的唯一性。
-
用途:避免数据重复,常用于需要保证唯一性的字段,如邮箱、手机号等。
-
-
常规索引:
-
特点:可以有多个,用于加速数据的查询速度。
-
用途:在需要频繁查询的字段上创建,以提高查询效率。
-
-
全文索引:
-
特点:可以有多个,专门用于在文本数据中进行关键词搜索。
-
用途:适用于需要对大量文本数据进行关键词查找的场景,如文章搜索、内容检索等。
-
二、InnoDB存储引擎的索引存储形式
-
聚集索引(Clustered Index):
-
特点:每个表只能有一个聚集索引,通常为主键索引。数据和索引存储在一起,叶子节点保存了完整的数据行。
-
用途:提供极快的主键查询速度,因为可以直接从索引中获取数据。
-
-
二级索引(Secondary Index):
-
特点:可以有多个,叶子节点存储的是主键值,需要通过主键再进行一次查找才能获取完整数据行。
-
用途:在非主键字段上创建,用于加速这些字段的查询。
-
三、聚集索引选取规则
-
如果存在主键,主键索引就是聚集索引。
-
如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。
-
如果表没有主键或没有合适的唯一索引,则 InnoDB 会自动生成一个
rowid作为隐藏的聚集索引。
四、思考题解答
-
以下 SQL 语句,哪个执行效率高?为什么?
sql复制
select * from user where id = 10; select * from user where name = 'Arm';-
答: 第一条语句执行效率高。因为
id是主键,主键索引是聚集索引,可以直接定位到数据行,不需要回表查询。而第二条语句需要先通过二级索引找到主键值,再回表查询完整数据行,多了一次I/O操作。
-
-
InnoDB 主键索引的 B+Tree 高度为多少?
-
答: 假设主键为
bigint(8字节),指针大小为6字节,页大小为16KB(约16384字节)。通过公式计算,每页可存储约1170个键值。树的高度与数据量有关,通常是2或3层。例如,高度为3层的树可存储约2000万条数据,能够满足大多数应用场景。
-
五、索引的语法
创建索引:
CREATE INDEX 索引名 ON 表名(列名);- 例如:
CREATE INDEX idx_user_name ON tb_user(name);为name字段创建普通索引。
查看索引:
SHOW INDEX FROM 表名;-
可以查看表中所有索引的信息,包括索引类型、列名等。
删除索引:
DROP INDEX 索引名 ON 表名;-
例如:
DROP INDEX idx_user_email ON tb_user;删除名为idx_user_email的索引。
六、案例分析
以 tb_user 表为例:
-
为
name字段创建普通索引idx_user_name,加速姓名查询。 -
为
phone字段创建唯一索引idx_user_phone,确保手机号唯一。 -
为
profession, age, status创建联合索引idx_pro_age_sta,优化多条件查询。 -
为
email字段创建索引idx_user_email,提高邮箱查询效率。
通过合理创建索引,可以显著提升数据库的查询性能,但需要注意避免过度索引,以免影响写入性能和占用过多存储空间。