DeepSeek 开源狂欢周(四)DualPipe与EPLB双弹齐发,训练效率的“双引擎”加速器!
在 DeepSeek 开源周 的第四天,DualPipe和EPLB这两项全新技术一同亮相,它们不仅为DeepSeek的低成本、高效训练大模型提供了强大支持,还为全球AI爱好者和从业者送上了两份“技术大礼包”。这些创新技术展示了DeepSeek如何以600万美元成本,训练出能与GPT-4o、Claude 3.5 Sonnet等先进模型一较高下的顶级AI模型。

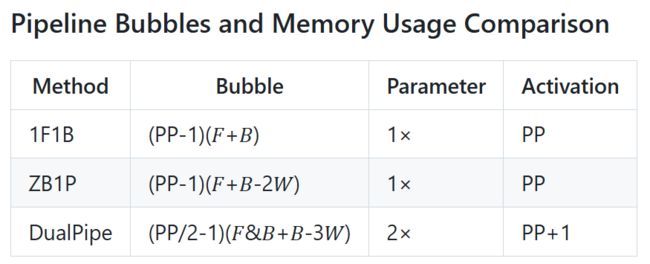
DualPipe:管道气泡的“终结者”
训练大模型时,管道并行(Pipeline Parallelism)通常是不可避免的,它通过将模型分层并分配到多个GPU上来加速训练。然而,传统的管道并行方法,如经典的1F1B(一个前向,一个后向),存在一个显著问题——GPU常因通信延迟而处于“空闲”状态,从而形成“管道气泡”,严重影响训练效率。
DualPipe的诞生,正是为了解决这一问题。它通过创新的双向流水线并行算法,彻底消灭了管道气泡,让GPU的空闲时间几乎降到零。DualPipe的核心优势有以下几点:
-
精细拆分,调度更灵活:通过将模型计算块拆分得更加细致(例如注意力、all-to-all分派、MLP等),大大提高了后续调度的灵活性和空间。
-
双向调度,效率翻倍:DualPipe采用双向调度策略,前向和后向计算及通信阶段可以实现完全重叠。通过同时处理微批次,大幅度减少GPU的空闲时间,提升训练效率。
-
通信优化,带宽拉满:DualPipe还定制了跨节点的all-to-all通信内核,充分利用高带宽网络如InfiniBand和NVLink,大大降低了通信开销。

从DeepSeek-V3技术报告中的对比可以看出,DualPipe显著减少了传统方法中的管道气泡,极大提高了训练效率,尤其在大规模并行处理时表现尤为突出。
EPLB:MoE模型的“负载均衡大师”
接下来,我们看一下EPLB(Expert Parallel Load Balancer),这是一种专门为Mixture-of-Experts(MoE)模型设计的负载均衡算法。MoE模型利用动态路由将输入分配给不同的专家(子网络),但由于各专家的负载不均,往往会导致GPU负载失衡,进而拖慢训练速度。
EPLB的核心设计理念非常简单且高效:
-
复制专家,分流压力:对于负载较重的专家,EPLB会复制其副本并将其分配到其他GPU上,从而平衡负载。
-
启发式打包,智能分配:EPLB会根据专家的实时负载计算出最优的复制和分配方案,确保每个GPU的任务负载“刚刚好”。
-
组内优化,通信减负:EPLB会尽量将同一组的专家安排在同一个节点上,减少跨节点的数据传输,进一步提升训练效率。
通过这种策略,EPLB能够有效提高GPU的利用率,最大限度地减少训练时间,特别是在大规模专家并行的应用中,效果尤为明显。

计算-通信重叠分析:效率的“秘密配方”
无论是DualPipe还是EPLB,它们成功的背后都离不开计算与通信的重叠优化。DeepSeek还公开了训练和推理阶段的性能分析数据,帮助开发者更直观地了解这些优化措施如何提升整体训练效率。
-
训练阶段:通过DualPipe的双向调度,前向和后向计算块的重叠,使得GPU能够持续工作,最大化并行计算的效率。

-
推理阶段:使用两个微批次重叠计算和通信,平衡GPU负载,确保每个GPU的工作时间被充分利用。
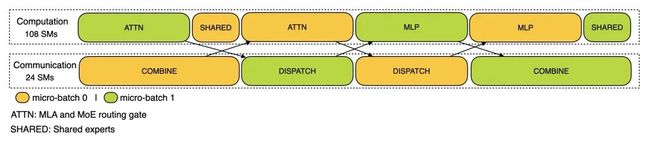
DeepSeek通过PyTorch Profiler捕捉的分析数据为开发者提供了丰富的可视化工具,帮助更好地理解这些优化技术的效果。
OpenCSG 社区开源加速计划
作为OpenCSG社区的一部分,我们一直致力于为开发者提供优质的开源资源。此次DeepSeek的DeepEP项目已同步到OpenCSG社区,欢迎大家访问并使用该项目。
DualPipe项目原始GitHub地址:
https://github.com/deepseek-ai/DualPipe
eplb项目原始GitHub地址:
https://github.com/deepseek-ai/eplb
profile-data项目原始GitHub地址:
https://github.com/deepseek-ai/profile-data
OpenCSG社区同步的DualPipe项目地址:
https://opencsg.com/codes/deepseek-ai/DualPipe
OpenCSG社区同步的eplb项目地址:
https://opencsg.com/codes/deepseek-ai/eplb
OpenCSG社区同步的profile-data项目地址:
https://opencsg.com/codes/deepseek-ai/profile-data
如果您遇到网络问题无法快速访问GitHub,可以通过我们的服务轻松同步该项目,确保不受网络限制影响。
OpenCSG为您提供了DeepSeek R1和V3系列模型的万兆网络高速下载服务,帮助您快速获取所需模型,避免因文件过大造成下载困难。
DeepSeek R1下载:
https://opencsg.com/models/DeepseekAI/DeepSeek-R1
DeepSeek V3下载:
https://opencsg.com/models/deepseek-ai/DeepSeek-V3
同时,我们还提供了各种蒸馏版、量化版,您可以访问我们的awesome DeepSeek合集来找到最适合的模型版本。
awesome-deepseek-r1-collection:
https://opencsg.com/collections/85/
awesome-deepseek-v3-collection:
https://opencsg.com/collections/86/
awesome-deepseek-Janus-collection:
https://opencsg.com/collections/87/
开源狂欢 继续期待
DualPipe与EPLB不仅是DeepSeek在大规模模型训练中的技术突破,更是对开源社区的又一次真诚回馈。作为DeepSeek-V3和R1等超大规模模型训练中的核心技术,这两项创新已在严苛的生产环境中经历了全面验证,性能和稳定性无可挑剔,值得每一位开发者和企业关注!
长期以来,AI社区在训练超大规模模型时面临着诸多挑战,尤其是在高效并行计算和负载均衡方面。传统的流水线并行方法常常遭遇“管道气泡”问题,导致GPU资源浪费,而专家并行模型中负载不均也让训练速度受限。DualPipe与EPLB的诞生,为这些难题提供了完美的解决方案。DualPipe通过双向流水线并行算法,成功消除了管道气泡,大幅提升了GPU利用率,而EPLB则利用智能负载均衡技术,优化了MoE架构中的专家分配,确保每个GPU的计算负载都能保持均衡。
更重要的是,随着DualPipe与EPLB的开源,全球的开发者和企业能够快速将这些先进的技术集成到他们的训练框架中,推动DeepSeek-V3和R1等大型模型在各个领域的广泛应用。这不仅加速了AI技术的普及,也为各种AI应用场景提供了高效、低成本的技术支撑。
未来,随着DualPipe和EPLB在社区和行业中的不断推广,我们有理由相信,这两项技术将成为大规模AI训练中的标配工具,推动AI技术的进一步发展,并为更多开发者和企业带来巨大的创新机会和商业价值。
OpenAI 社区与您同行
OpenAI 社区 将继续关注并为您带来 DeepSeek 的最新开源成果,让我们共同期待更多激动人心的技术创新!