20250303-代码笔记-train_n100
文章目录
- 前言
- 一、参数
-
- 1. Machine Environment Config
- 2. Path Config
- 3. Imports
- 4. Parameters
-
- 环境参数 (`env_params`):
- 模型参数 (model_params):
- 优化器参数 (`optimizer_params`):
- 训练器参数 (trainer_params):
- 加载预训练模型的设置 (`model_load`):
- 日志文件参数 (`logger_params`):
- 代码
- 二、main()函数
-
- 函数解析
- 代码
- 三、子函数
-
- def _set_debug_mode():
-
- 函数分析
- 函数代码
- def _print_config():
-
- 函数分析
- 函数代码
- 其他
-
- 函数分析
- 函数代码
- 附录
-
- 代码(全)
前言
一、参数
1. Machine Environment Config
DEBUG_MODE: 控制是否启用调试模式。False表示不开启调试模式,True启用调试模式。USE_CUDA: 是否使用 GPU 加速计算,默认值为True,即在非调试模式下使用 CUDA(GPU)。CUDA_DEVICE_NUM: 指定要使用的 GPU 编号。1表示使用第二个 GPU,0表示使用第一个 GPU。-1表示不使用 GPU。
2. Path Config
os.chdir: 将当前工作目录切换到当前脚本所在的目录。
sys.path.insert(0, "..") 和 sys.path.insert(0, "../.."): 将上级和上上级目录添加到 sys.path 中,这样可以导入其他目录下的 Python 模块。
3. Imports
logging: 用于设置日志记录器,跟踪代码执行过程。
utils.utils: 从 utils/utils.py 中导入 create_logger 和 copy_all_src 方法。
CVRPTrainer: 导入 CVRPTrainer 类,这个类包含了核心训练逻辑。
4. Parameters
环境参数 (env_params):
problem_size: 问题规模,在 VRP(车辆路径问题)中,代表节点的数量(例如 100 个节点)。
pomo_size: POMO 算法中的多智能体数量,通常等于问题规模。
模型参数 (model_params):
embedding_dim: 嵌入维度,表示节点特征向量的维度大小。128 维表示每个节点特征的向量长度为 128。
sqrt_embedding_dim: 嵌入维度的平方根,通常用于正则化操作。
encoder_layer_num: Transformer 编码器的层数,这里设置为 6 层。
qkv_dim: 查询(Q)、键(K)和值(V)向量的维度,用于多头注意力机制。
head_num: 多头注意力机制中的头数。8 表示使用 8 个注意力头。
logit_clipping: logits 剪切范围,用于防止值过大导致数值不稳定。
ff_hidden_dim: 前馈神经网络的隐藏层维度,用于计算中间层的特征。
eval_type: 模型评估方式,这里是贪心搜索(argmax),表示选择概率最高的动作。
优化器参数 (optimizer_params):
optimizer: 定义优化器的超参数。
lr: 学习率,控制每次参数更新的步长,设为 1e-4。
weight_decay: 权重衰减,防止模型过拟合,设为 1e-6。
scheduler: 学习率调度器的超参数。
milestones: 学习率下降的时间点(即训练的 epoch 数)。这里设置了 8001 和 8051。
gamma: 学习率衰减系数,当达到 milestones 时,学习率乘以此值(0.1)。
训练器参数 (trainer_params):
use_cuda: 是否使用 CUDA 加速,等于 USE_CUDA 配置。
cuda_device_num: 使用的 GPU 设备编号。
epochs: 总训练轮数,这里设为 100 轮(用于测试)。
train_episodes: 总训练实例数量,设置为 10 * 100,即 1000 个训练实例。
train_batch_size: 每批训练的数据大小,设置为 64。
prev_model_path: 预训练模型路径,如果为 None,则从头开始训练。
logging: 配置训练过程中的日志记录和保存:
model_save_interval: 每隔多少个 epoch 保存一次模型。img_save_interval: 每隔多少个 epoch 保存一次训练图像。log_image_params_1和log_image_params_2: 日志中图像样式的配置,指定用于生成训练过程中的图像样式文件。
加载预训练模型的设置 (model_load):
enable: 是否启用加载预训练模型,False表示不加载。
path: 预训练模型的路径,如果启用加载模型时使用。
epoch: 指定加载模型的 epoch 号。
日志文件参数 (logger_params):
log_file: 配置日志文件的描述和文件名。
desc: 描述日志文件的名称。filename: 日志文件的实际文件名。
代码
##########################################################################################
# Machine Environment Config
DEBUG_MODE = False
USE_CUDA = not DEBUG_MODE
CUDA_DEVICE_NUM = 1
# CUDA_DEVICE_NUM = 0
##########################################################################################
# Path Config
import os
import sys
os.chdir(os.path.dirname(os.path.abspath(__file__)))
sys.path.insert(0, "..") # for problem_def
sys.path.insert(0, "../..") # for utils
##########################################################################################
# import
import logging
from utils.utils import create_logger, copy_all_src
#核心:训练函数
from CVRPTrainer import CVRPTrainer as Trainer
##########################################################################################
# parameters
env_params = {
'problem_size': 100, # 问题规模,例如 VRP(车辆路径问题)中,节点数量为 100
'pomo_size': 100, # POMO 算法的多智能体数量,通常等于问题规模
}
model_params = {
'embedding_dim': 128, # 嵌入维度,表示节点特征向量的维度大小
'sqrt_embedding_dim': 128**(1/2), # 嵌入维度的平方根,用于某些正则化计算
'encoder_layer_num': 6, # Transformer 编码器层数
'qkv_dim': 16, # 查询 (Q)、键 (K) 和值 (V) 向量的维度
'head_num': 8, # 多头注意力机制中的头数
'logit_clipping': 10, # logits 剪切范围,防止过大导致数值不稳定
'ff_hidden_dim': 512, # 前馈神经网络隐藏层维度
'eval_type': 'argmax', # 模型的评估方式 ('argmax' 表示贪心搜索)
}
optimizer_params = {
'optimizer': {
'lr': 1e-4, # 学习率,控制权重更新的步长
'weight_decay': 1e-6 # 权重衰减,用于防止过拟合
},
'scheduler': {
'milestones': [8001, 8051], # 学习率下降的时间点(epoch 数)
'gamma': 0.1 # 学习率衰减系数
}
}
trainer_params = {
# 是否使用 CUDA
'use_cuda': USE_CUDA,
# 指定使用的 GPU 设备编号
'cuda_device_num': CUDA_DEVICE_NUM,
# 总训练轮数 (epochs)
# 'epochs': 8100,
'epochs': 100,# test-01
# 总训练实例数量 (episodes)
# 比如在每个实例中模型学习一个完整的优化问题
# 'train_episodes': 10 * 1000,
'train_episodes': 10 * 100,# test-01
# 每批训练的数据大小 (batch size)
'train_batch_size': 64,
# 预训练模型路径(设置为 None 表示从头开始训练)
'prev_model_path': None,
# 日志配置
'logging': {
# 模型保存的间隔(每隔多少个 epoch 保存一次)
'model_save_interval': 50,
# 训练图片生成间隔(每隔多少个 epoch 保存一次图片)
'img_save_interval': 50,
# 日志图片样式 1 的配置
'log_image_params_1': {
'json_foldername': 'log_image_style', # 样式配置文件的文件夹名
'filename': 'style_cvrp_20.json' # 样式配置文件的文件名
},
# 日志图片样式 2 的配置
'log_image_params_2': {
'json_foldername': 'log_image_style', # 样式配置文件的文件夹名
'filename': 'style_loss_1.json' # 样式配置文件的文件名
},
},
# 是否加载预训练模型
'model_load': {
# 是否启用加载预训练模型
'enable': False,
# 预训练模型路径(需要启用时配置此路径)
# 'path': './result/saved_CVRP20_model',
# 指定加载的模型 epoch(需要启用时设置此值)
# 'epoch': 2000,
}
}
logger_params = {
'log_file': {
'desc': 'train_cvrp_n100_with_instNorm',
'filename': 'run_log'
}
}
二、main()函数
函数解析
main() 函数是整个训练流程的核心入口点,负责配置训练环境、创建训练器并启动训练过程。
执行流程图链接
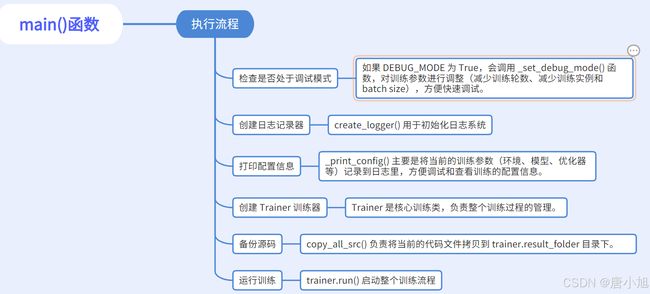
代码
def main():
if DEBUG_MODE:
_set_debug_mode() #调试模式检查
create_logger(**logger_params) #创建日志记录器
_print_config() #打印配置信息
trainer = Trainer(env_params=env_params,
model_params=model_params,
optimizer_params=optimizer_params,
trainer_params=trainer_params)
copy_all_src(trainer.result_folder)#保存源码副本
trainer.run()
三、子函数
def _set_debug_mode():
函数分析
调用 _set_debug_mode() 函数,会对训练参数进行调整(减少训练轮数、减少训练实例和 batch size),方便快速调试。
函数代码
def _set_debug_mode():
global trainer_params
trainer_params['epochs'] = 5
trainer_params['train_episodes'] = 20
trainer_params['train_batch_size'] = 4
def _print_config():
函数分析
打印配置信息
函数代码
def _print_config():
logger = logging.getLogger('root')
logger.info('DEBUG_MODE: {}'.format(DEBUG_MODE))
logger.info('USE_CUDA: {}, CUDA_DEVICE_NUM: {}'.format(USE_CUDA, CUDA_DEVICE_NUM))
[logger.info(g_key + "{}".format(globals()[g_key])) for g_key in globals().keys() if g_key.endswith('params')]
其他
函数分析
Python 中的常见用法,它的作用是确保只有在直接运行当前脚本时,才会执行 main() 函数,而如果当前脚本作为模块被其他脚本导入时,main() 函数不会被执行。
函数代码
if __name__ == "__main__":
main()
附录
代码(全)
##########################################################################################
# Machine Environment Config
DEBUG_MODE = False
USE_CUDA = not DEBUG_MODE
CUDA_DEVICE_NUM = 1
# CUDA_DEVICE_NUM = 0
##########################################################################################
# Path Config
import os
import sys
os.chdir(os.path.dirname(os.path.abspath(__file__)))
sys.path.insert(0, "..") # for problem_def
sys.path.insert(0, "../..") # for utils
##########################################################################################
# import
import logging
from utils.utils import create_logger, copy_all_src
#核心:训练函数
from CVRPTrainer import CVRPTrainer as Trainer
##########################################################################################
# parameters
env_params = {
'problem_size': 100, # 问题规模,例如 VRP(车辆路径问题)中,节点数量为 100
'pomo_size': 100, # POMO 算法的多智能体数量,通常等于问题规模
}
model_params = {
'embedding_dim': 128, # 嵌入维度,表示节点特征向量的维度大小
'sqrt_embedding_dim': 128**(1/2), # 嵌入维度的平方根,用于某些正则化计算
'encoder_layer_num': 6, # Transformer 编码器层数
'qkv_dim': 16, # 查询 (Q)、键 (K) 和值 (V) 向量的维度
'head_num': 8, # 多头注意力机制中的头数
'logit_clipping': 10, # logits 剪切范围,防止过大导致数值不稳定
'ff_hidden_dim': 512, # 前馈神经网络隐藏层维度
'eval_type': 'argmax', # 模型的评估方式 ('argmax' 表示贪心搜索)
}
optimizer_params = {
'optimizer': {
'lr': 1e-4, # 学习率,控制权重更新的步长
'weight_decay': 1e-6 # 权重衰减,用于防止过拟合
},
'scheduler': {
'milestones': [8001, 8051], # 学习率下降的时间点(epoch 数)
'gamma': 0.1 # 学习率衰减系数
}
}
trainer_params = {
# 是否使用 CUDA
'use_cuda': USE_CUDA,
# 指定使用的 GPU 设备编号
'cuda_device_num': CUDA_DEVICE_NUM,
# 总训练轮数 (epochs)
# 'epochs': 8100,
'epochs': 100,# test-01
# 总训练实例数量 (episodes)
# 比如在每个实例中模型学习一个完整的优化问题
# 'train_episodes': 10 * 1000,
'train_episodes': 10 * 100,# test-01
# 每批训练的数据大小 (batch size)
'train_batch_size': 64,
# 预训练模型路径(设置为 None 表示从头开始训练)
'prev_model_path': None,
# 日志配置
'logging': {
# 模型保存的间隔(每隔多少个 epoch 保存一次)
'model_save_interval': 50,
# 训练图片生成间隔(每隔多少个 epoch 保存一次图片)
'img_save_interval': 50,
# 日志图片样式 1 的配置
'log_image_params_1': {
'json_foldername': 'log_image_style', # 样式配置文件的文件夹名
'filename': 'style_cvrp_20.json' # 样式配置文件的文件名
},
# 日志图片样式 2 的配置
'log_image_params_2': {
'json_foldername': 'log_image_style', # 样式配置文件的文件夹名
'filename': 'style_loss_1.json' # 样式配置文件的文件名
},
},
# 是否加载预训练模型
'model_load': {
# 是否启用加载预训练模型
'enable': False,
# 预训练模型路径(需要启用时配置此路径)
# 'path': './result/saved_CVRP20_model',
# 指定加载的模型 epoch(需要启用时设置此值)
# 'epoch': 2000,
}
}
logger_params = {
'log_file': {
'desc': 'train_cvrp_n100_with_instNorm',
'filename': 'run_log'
}
}
##########################################################################################
# main
def main():
if DEBUG_MODE:
_set_debug_mode() #调试模式检查
create_logger(**logger_params) #创建日志记录器
_print_config() #打印配置信息
trainer = Trainer(env_params=env_params,
model_params=model_params,
optimizer_params=optimizer_params,
trainer_params=trainer_params)
copy_all_src(trainer.result_folder)#保存源码副本
trainer.run()
def _set_debug_mode():
global trainer_params
trainer_params['epochs'] = 5
trainer_params['train_episodes'] = 20
trainer_params['train_batch_size'] = 4
def _print_config():
logger = logging.getLogger('root')
logger.info('DEBUG_MODE: {}'.format(DEBUG_MODE))
logger.info('USE_CUDA: {}, CUDA_DEVICE_NUM: {}'.format(USE_CUDA, CUDA_DEVICE_NUM))
[logger.info(g_key + "{}".format(globals()[g_key])) for g_key in globals().keys() if g_key.endswith('params')]
##########################################################################################
if __name__ == "__main__":
main()