我使用 DeepSeek 一天完成了大家一个月的工作
在公司决定进军海外市场的关键时刻,我们面临了一个看似不可能完成的任务——将那套用了多年的老系统做国际化改造。所有代码中的中文,不论是错误提示、日志信息还是注释,都必须变成英文。想象一下,如果人工一个一个地去翻译,可能需要至少一个月的时间来完成这项工作。可我,一杯咖啡的时间,深夜调试后,竟然用 DeepSeek 轻松搞定了整个项目的翻译工作。
背景与挑战
在传统开发中,国际化通常只涉及界面和配置文件的翻译。但这次,我们面对的挑战远不止于此。老系统中,几乎每个文件都嵌入了大量中文:
- 提示信息和日志:必须确保用户体验不因语言混杂而受影响。
- 代码注释:这对于后续维护至关重要,统一成英文可以减少沟通成本。
- 代码中的业务逻辑文本:直接影响编译后的程序输出,任何遗漏都有可能带来安全隐患。
面对如此繁重的工作量,传统的人工处理不仅效率低下,还容易出错,完全不能满足快速上线海外业务的需求。
我是如何逆袭的
作为一名热衷技术创新的高级工程师,我开始思考:为什么不利用最近大热的大语言模型,来自动化这一翻译流程呢?经过一番调研与试验,我决定依赖DeepSeek开发一个自动化工具,其核心思路如下:
-
逐行读取与检测
使用 Python 遍历项目中所有指定后缀的文件(比如.java),逐行检测每行是否包含中文字符。为了避免一次性处理过多内容,我采用了流式处理,既降低了内存消耗,也控制了 API 调用时的 token 数量。 -
智能翻译与格式保留
发现中文后,我会先提取每一行的前导缩进,只对实际内容部分进行翻译。这样不仅确保了代码结构不被破坏,还能保持原有的格式。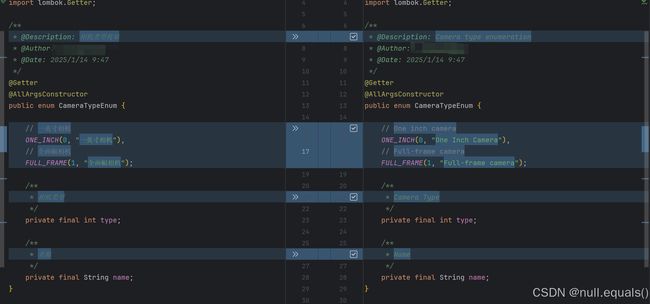
-
分段处理
有些代码行过长,直接传给大模型可能超出 token 限制,所以我实现了分段翻译,每段翻译后再拼接起来。虽然这样可能会导致语境丢失一点,但经过测试,效果完全符合我们的要求。 -
替换原文件
将翻译后的内容写入临时文件,最后用安全的文件替换方式覆盖原文件,确保万一中途出错也不会损坏原始代码。
下面是一段关键代码示例,展示了整个流程的实现思路:
import os
import re
import tempfile
import shutil
from OpenAIClient import openai_client
def has_chinese(text: str) -> bool:
return bool(re.search(r"[\u4e00-\u9fff]", text))
def translate_text(text: str) -> str:
return get_completion(text)
def get_completion(code_segment, model="gpt-4o-mini"):
messages = [
{
"role": "system",
"content": (
"你是一个专业的代码翻译助手。请将代码中的中文文本翻译成英文,"
"保持代码结构和格式不变,仅替换字符串内容。保持变量名和函数名不变。"
"你只需要输出翻译之后的内容,不需要添加额外的其它的内容,"
"输出与输入除了翻译的内容变化,其它应该完全保持一致,不要输出 markdown 格式。"
),
},
{"role": "user", "content": f"请翻译以下代码:\n{code_segment}"},
]
response = openai_client.chat.completions.create(
model=model,
messages=messages,
temperature=0,
)
return response.choices[0].message.content
def process_file(file_path: str, max_line_length: int = 2000) -> None:
temp_file = tempfile.NamedTemporaryFile(mode="w", delete=False, encoding="utf-8")
try:
with open(file_path, "r", encoding="utf-8") as f:
for line in f:
indent_match = re.match(r"^(\s*)", line)
indent = indent_match.group(1) if indent_match else ""
content = line[len(indent):].rstrip("\n")
if has_chinese(content):
translated_line = translate_text(content)
translated_line = "\n".join(indent + part for part in translated_line.splitlines())
line = translated_line + "\n"
temp_file.write(line)
temp_file.close()
shutil.move(temp_file.name, file_path)
print(f"Processed: {file_path}")
except Exception as e:
print(f"Error processing {file_path}: {e}")
if os.path.exists(temp_file.name):
os.remove(temp_file.name)
# 遍历目录,对指定后缀的文件进行处理
def process_directory(
root_dir: str, file_extensions: list, max_line_length: int = 2000
) -> None:
for subdir, _, files in os.walk(root_dir):
for file in files:
if any(file.endswith(ext) for ext in file_extensions):
file_path = os.path.join(subdir, file)
process_file(file_path, max_line_length)
if __name__ == "__main__":
root_directory = "\xxxx\"
extensions = [".java"]
process_directory(root_directory, extensions)成果与感悟
经过测试,DeepSeek 不仅能够准确识别代码中所有的中文文本,还能在保留原有格式的基础上进行流畅翻译。结果令人惊喜——原本需要团队花费一个月的工作量,最终我仅用一天时间就完成了所有改造任务!
这次经历再次证明,自动化工具与大语言模型的结合,能大幅度提高工作效率,让开发者从重复劳动中解放出来,把精力更多地投入到创新和优化中。对于正在面临国际化改造、代码翻译或其它大规模自动化任务的你,我强烈推荐尝试这种思路,也许它能为你带来意想不到的效果。
总结
在海外业务扩展的大潮中,时间就是竞争力。利用 大语音模型,我不仅突破了传统翻译方式的局限,还将一个月的工作压缩到了短短一天。技术革新并不仅仅体现在新算法上,更在于如何将这些工具落地解决实际问题。
未来,我相信这种智能自动化的应用将会越来越普及,推动软件开发迈向全新的高度。作为一名高级工程师,我深知不断追求效率与创新的重要性,也愿意与大家分享这些实战经验。希望我的这次实践能够为更多人提供启示,共同迎接技术带来的无限可能!