Python - 爬虫;爬虫-网页抓取数据-工具curl
一、爬虫
关于爬虫的合法性
通用爬虫限制:Robots协议【约定协议robots.txt】
- robots协议:协议指明通用爬虫可以爬取网页的权限
- robots协议是一种约定,一般是大型公司的程序或者搜索引擎等遵守
几乎每一个网站都有一个名为 robots.txt 的文档,当然也有部分网站没有设定 robots.txt。对于没有设定 robots.txt 的网站可以通过网络爬虫获取没有口令加密的数据,也就是该网站所有页面数据都可以爬取。如果网站有 robots.txt 文档,就要判断是否有禁止访客获取的数据。
注意事项!!!
- 进行爬虫时,需要遵守目标网站的robots.txt文件的规定,避免过度爬取或违反网站的使用条款。
- 爬虫行为可能会给目标网站带来额外的负担,因此在进行大规模爬虫操作时,需要谨慎处理。
- 如果涉及金融、医疗、法律等存在风险的领域,请在操作前咨询专业人士,并注意遵守相关法律法规。
网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟浏览器发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。
爬虫是一个自动化程序,它能够自动地从互联网上抓取数据。使用Python编写爬虫程序时,通常会用到以下库:
requests:用于发送HTTP请求,获取网页内容。
BeautifulSoup 或 lxml:用于解析HTML或XML文档,提取所需数据。
Scrapy:一个强大的爬虫框架,适合构建大型爬虫项目。
HTTP & HTTPS
- HTTP:超文本传输协议:Hyper Text Transfer Protocal
- HTTPS: Secure Hypertext Transfer Protocol 安全的超文本传输协议
1、headers的属性介绍
User-Agent : 有些服务器或 Proxy 会通过该值来判断是否是浏览器发出的请求
Content-Type : 在使用 REST 接口时,服务器会检查该值,用来确定 HTTP Body 中的内容该怎样解析。
application/xml : 在 XML RPC,如 RESTful/SOAP 调用时使用
application/json : 在 JSON RPC 调用时使用
application/x-www-form-urlencoded : 浏览器提交 Web 表单时使用
在使用服务器提供的 RESTful 或 SOAP 服务时, Content-Type 设置错误会导致服务器拒绝服务
注意:使用正则匹配替换^(.*):(.*)$ --> "\1":"\2",
- 随机添加/修改User-Agent
可以通过调用Request.add_header() 添加/修改一个特定的header 也可以通过调用Request.get_header()来查看已有的header。
ua = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
# 添加自定义的头信息
req = urllib.request.Request('http://httpbin.org/user-agent')
req.add_header('User-Agent', ua)
# 接受一个urllib.request.Request对象
r = urllib.request.urlopen(req)
resp = json.loads(r.read())
# 打印httpbin网站返回信息里的user-agent
print('网站返回的user-agent:', resp["user-agent"]) # 网站返回的user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3
2、Referer (页面跳转处)
Referer:表明产生请求的网页来自于哪个URL,用户是从该 Referer页面访问到当前请求的页面。这个属性可以用来跟踪Web请求来自哪个页面,是从什么网站来的等。
有时候遇到下载某网站图片,需要对应的referer,否则无法下载图片,那是因为人家做了防盗链,原理就是根据referer去判断是否是本网站的地址,如果不是,则拒绝,如果是,就可以下载;
3、Accept-Encoding(文件编解码格式)
Accept-Encoding:指出浏览器可以接受的编码方式。编码方式不同于文件格式,它是为了压缩文件并加速文件传递速度。浏览器在接收到Web响应之后先解码,然后再检查文件格式,许多情形下这可以减少大量的下载时间。
举例:Accept-Encoding:gzip;q=1.0, identity; q=0.5, ;q=0
如果有多个Encoding同时匹配, 按照q值顺序排列,本例中按顺序支持 gzip, identity压缩编码,支持gzip的浏览器会返回经过gzip编码的HTML页面。 如果请求消息中没有设置这个域服务器假定客户端对各种内容编码都可以接受。
4、Accept-Language(语言种类)
Accept-Langeuage:指出浏览器可以接受的语言种类,如en或en-us指英语,zh或者zh-cn指中文,当服务器能够提供一种以上的语言版本时要用到。
5.、Accept-Charset(字符编码)
Accept-Charset:指出浏览器可以接受的字符编码。
举例:Accept-Charset:iso-8859-1,gb2312,utf-8
- ISO8859-1:通常叫做Latin-1。Latin-1包括了书写所有西方欧洲语言不可缺少的附加字符,英文浏览器的默认值是ISO-8859-1.
- gb2312:标准简体中文字符集;
- utf-8:UNICODE 的一种变长字符编码,可以解决多种语言文本显示问题,从而实现应用国际化和本地化。
如果在请求消息中没有设置这个域,缺省是任何字符集都可以接受。
6.、Cookie (Cookie)
Cookie:浏览器用这个属性向服务器发送Cookie。Cookie是在浏览器中寄存的小型数据体,它可以记载和服务器相关的用户信息,也可以用来实现会话功能,以后会详细讲。
7.、Content-Type (POST数据类型)
Content-Type:POST请求里用来表示的内容类型。
举例:Content-Type = Text/XML; charset=gb2312:
指明该请求的消息体中包含的是纯文本的XML类型的数据,字符编码采用“gb2312”。
8、服务端HTTP响应
HTTP响应也由四个部分组成,分别是: 状态行、消息报头、空行、响应正文
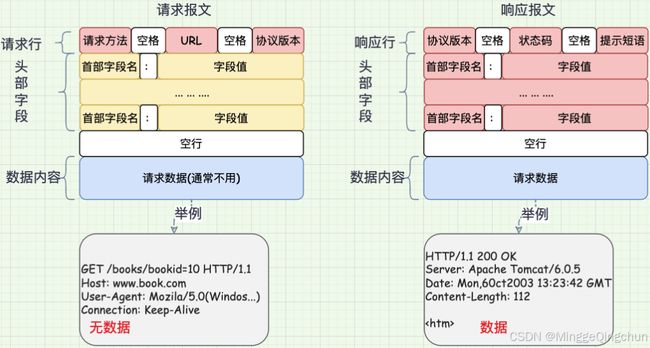
常用的响应报头(了解)
理论上所有的响应头信息都应该是回应请求头的。但是服务端为了效率,安全,还有其他方面的考虑,会添加相对应的响应头信息,从上图可以看到:
1、Cache-Control:must-revalidate, no-cache, private
这个值告诉客户端,服务端不希望客户端缓存资源,在下次请求资源时,必须要从新请求服务器,不能从缓存副本中获取资源。
- Cache-Control是响应头中很重要的信息,当客户端请求头中包含Cache-Control:max-age=0请求,明确表示不会缓存服务器资源时,Cache-Control作为作为回应信息,通常会返回no-cache,意思就是说,"那就不缓存呗"。
- 当客户端在请求头中没有包含Cache-Control时,服务端往往会定,不同的资源不同的缓存策略,比如说oschina在缓存图片资源的策略就是Cache-Control:max-age=86400,这个意思是,从当前时间开始,在86400秒的时间内,客户端可以直接从缓存副本中读取资源,而不需要向服务器请求。
2、Connection:keep-alive
这个字段作为回应客户端的Connection:keep-alive,告诉客户端服务器的tcp连接也是一个长连接,客户端可以继续使用这个tcp连接发送http请求。
3、Content-Encoding:gzip
告诉客户端,服务端发送的资源是采用gzip编码的,客户端看到这个信息后,应该采用gzip对资源进行解码。
4、Content-Type:text/html;charset=UTF-8
告诉客户端,资源文件的类型,还有字符编码,客户端通过utf-8对资源进行解码,然后对资源进行html解析。通常我们会看到有些网站是乱码的,往往就是服务器端没有返回正确的编码。
5、Date:Sun, 1 Jan 2000 01:00:00 GMT
这个是服务端发送资源时的服务器时间,GMT是格林尼治所在地的标准时间。http协议中发送的时间都是GMT的,这主要是解决在互联网上,不同时区在相互请求资源的时候,时间混乱问题。
6、Expires:Sun, 1 Jan 2000 01:00:00 GMT
这个响应头也是跟缓存有关的,告诉客户端在这个时间前,可以直接访问缓存副本,很显然这个值会存在问题,因为客户端和服务器的时间不一定会都是相同的,如果时间不同就会导致问题。所以这个响应头是没有Cache-Control:max-age=*这个响应头准确的,因为max-age=date中的date是个相对时间,不仅更好理解,也更准确。
7、Pragma:no-cache
这个含义与Cache-Control等同。
8、Server:Tengine/1.4.6
这个是服务器和相对应的版本,只是告诉客户端服务器的信息。
9、Transfer-Encoding:chunked
这个响应头告诉客户端,服务器发送的资源的方式是分块发送的。一般分块发送的资源都是服务器动态生成的,在发送时还不知道发送资源的大小,所以采用分块发送,每一块都是独立的,独立的块都能标示自己的长度,最后一块是0长度的,当客户端读到这个0长度的块时,就可以确定资源已经传输完了。
10、Vary: Accept-Encoding
告诉缓存服务器,缓存压缩文件和非压缩文件两个版本,现在这个字段用处并不大,因为现在的浏览器都是支持压缩的。
响应状态码
响应状态代码有三位数字组成,第一个数字定义了响应的类别,且有五种可能取值。
常见状态码:
- 100~199:表示服务器成功接收部分请求,要求客户端继续提交其余请求才能完成整个处理过程。
- 200~299:表示服务器成功接收请求并已完成整个处理过程。常用200(OK 请求成功)。
- 300~399:为完成请求,客户需进一步细化请求。例如:请求的资源已经移动一个新地址、常用302(所请求的页面已经临时转移至新的url)、307和304(使用缓存资源)。
- 400~499:客户端的请求有错误,常用404(服务器无法找到被请求的页面)、403(服务器拒绝访问,权限不够)。
- 500~599:服务器端出现错误,常用500(请求未完成。服务器遇到不可预知的情况)。
Cookie 和 Session:
服务器和客户端的交互仅限于请求/响应过程,结束之后便断开,在下一次请求时,服务器会认为新的客户端。
为了维护他们之间的链接,让服务器知道这是前一个用户发送的请求,必须在一个地方保存客户端的信息。
Cookie:通过在 客户端 记录的信息确定用户的身份。
Session:通过在 服务器端 记录的信息确定用户的身份。
二、curl
curl是一个在命令行下工作的文件传输工具,常用于网络爬虫。以下是关于curl爬虫的一些详细信息和使用方法:
curl简介
- curl全称Command Line URL viewer,是一个在命令行下工作的文件传输工具。它支持文件的上传和下载,可以发送各种http请求给网站,然后抓取网站上内容。
- curl支持多种协议,包括HTTP、HTTPS、FTP、TELNET等。
- curl支持代理、用户认证、FTP上传、HTTP POST请求、SSL连接、cookies、文件传输、Metalink等功能。
curl在爬虫中的应用
- curl可以用于获取网页的源代码。例如,通过命令行窗口使用curl访问新浪财经(curl http://finance.sina.com.cn/),可以获取新浪财经首页的网页源代码。
- curl支持多种参数来定制请求。例如,使用-o参数可以将网页源代码下载并保存到文件中。
- curl还支持自动跳转(-L参数)、显示http response的头信息(-i参数)、只显示http response的头信息(-I参数)等功能。
curl的高级用法
- curl可以用于发送POST请求。例如,使用-X POST --data "data=xxx" www.cnblogs.com/form.cgi可以发送包含数据的POST请求。
- curl还可以用于处理cookies、设置请求头、处理HTTP认证等高级功能。
curl在PHP中的应用
- 在PHP中,curl库是自带的,无需额外安装。但为了避免使用时出现错误,建议检查cURL版本是否已经安装和集成。
- 使用PHP的curl库,可以方便地进行Web数据的抓取、FTP上传文件、HTTP POST和PUT数据等操作。
- 在PHP中,通过curl_setopt()函数可以设置各种请求选项,如URL、是否返回响应内容、请求头等。
- 使用curl_exec()方法可以执行HTTP请求,获取响应内容。最后,使用curl_close()函数关闭cURL会话。
(一)Windows安装curl
在Windows系统中,通常有两种方式可以安装和使用curl命令:
方法1:使用Chocolatey
Chocolatey 是一个Windows下的包管理器,类似于Linux中的apt或yum。通过Chocolatey安装curl非常简单。
-
安装Chocolatey(如果你还没有安装的话):
打开命令提示符(cmd)并执行以下命令:
@"%SystemRoot%\System32\WindowsPowerShell\v1.0\powershell.exe" -NoProfile -InputFormat None -ExecutionPolicy Bypass -Command "iex ((New-Object System.Net.WebClient).DownloadString('https://chocolatey.org/install.ps1'))" && SET "PATH=%PATH%;%ALLUSERSPROFILE%\chocolatey\bin" -
安装curl:在命令提示符(cmd)中,执行以下命令:
choco install curl
方法2:手动下载并安装
如果你不想使用Chocolatey,你也可以手动下载curl的可执行文件。
-
下载curl:访问curl官方网站或GitHub的curl项目页面,下载适合你的Windows版本的
curl。 -
解压和放置到系统路径:
下载后,通常你会得到一个压缩文件(如
.zip)。解压这个文件,并将解压后的文件夹路径添加到系统的环境变量PATH中。-
右键点击“此电脑”或“我的电脑”,选择“属性”。
-
点击“高级系统设置”。
-
在“系统属性”窗口中,点击“环境变量”。
-
在“系统变量”区域找到
Path变量,选择它然后点击“编辑”。 -
点击“新建”,然后添加你的
curl解压目录的路径(例如C:\Program Files\curl)。 -
点击“确定”保存更改。
-
-
验证安装:
打开一个新的命令提示符窗口,输入
curl --version来检查是否正确安装了curl。如果显示版本信息,那么安装成功。curl --version
如果在Windows中遇到如下错误
curl --version curl : 未能解析此远程名称: '--version' 所在位置 行:1 字符: 1
curl --version
+ CategoryInfo : InvalidOperation: (System.Net.HttpWebRequest:HttpWebRequest) [Invok
e-WebRequest],WebException
+ FullyQualifiedErrorId : WebCmdletWebResponseException,Microsoft.PowerShell.Commands.InvokeW
ebRequestCommand是因为你在 PowerShell 中使用了 curl 命令,并且 PowerShell 将 curl 解释为 Invoke-WebRequest 而不是调用实际的 curl 工具。
以下是解决方案:
如果你想使用 Windows 自带的类似 curl 的功能,你可以使用 Invoke-WebRequest -Uri
如果你确实想使用 GNU 或 Linux 版本的 curl 工具,请确保它已正确安装并且在系统的 PATH 环境变量中。然后尝试再次运行 curl --version。
如果你需要检查是否安装了 curl 及其版本信息,在 PowerShell 中可以尝试以下命令来避免混淆:
# 使用 cmd.exe 来运行 curl 命令
cmd /c "curl --version"方法3:使用Git Bash(如果你安装了Git)
如果你已经安装了Git for Windows,Git Bash自带了curl。你可以通过Git Bash来使用curl,而不需要单独安装。
-
打开Git Bash。
-
输入
curl --version来检查是否已经包含在Git Bash中。
(二)网站字段详解
一、查看网页源码
直接在curl命令后加上网址,就可以看到网页源码。我们以网址www.sina.com为例(选择该网址,主要因为它的网页代码较短):
$ curl https://www.baidu.comStatusCode : 200
StatusDescription : OK
Content :
如果要把这个网页保存下来,可以使用`-o`参数,这就相当于使用wget命令了。
$ curl -o [文件名] www.baidu.com二、自动跳转:`-L`参数
有的网址是自动跳转的。使用`-L`参数,curl就会跳转到新的网址。
$ curl -L www.baidu.comStatusCode : 200
StatusDescription : OK
Content :
键入上面的命令,结果就自动跳转为www.baidu.com。
三、显示头信息:`-i`参数
`-i`参数可以显示http response的头信息,连同网页代码一起。
curl -i https://www.baidu.comHTTP/1.1 200 OK
Accept-Ranges: bytes
Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform
Connection: keep-alive
Content-Length: 2443
Content-Type: text/html
Date: Thu, 06 Feb 2025 13:45:16 GMT
Etag: "588603eb-98b"
Last-Modified: Mon, 23 Jan 2017 13:23:55 GMT
Pragma: no-cache
Server: bfe/1.0.8.18
Set-Cookie: BDORZ=27315; max-age=86400; domain=.baidu.com; path=/
百度一下,你就知道 
`-I`参数则是只显示http response的头信息。
四、显示通信过程:`-v`参数
`-v`参数可以显示一次http通信的整个过程,包括端口连接和http request头信息。
curl -v www.baidu.com详细信息: GET with 0-byte payload
详细信息: received 511136-byte response of content type text/html; charset=utf-8
StatusCode : 200
StatusDescription : OK
Content : ; outerText=; tagName=I
MG; class=s-top-tab-image; src=data:image/png;base64,iVBORw0KGgoA
AAANSUhEUgAAAE4AAAAqCAMAAAAqEZ1jAAAAAXNSR0IArs4c6QAAAAlwSFlzAAAhO
AAAITgBRZYxYAAAAKJQTFRFAAAAenb/RpP/k2j/XXf7cXX6P5z7i2n8W3j7ZHP7jm
n9VID7Qpf8jWn8Xnr6iWr8YHb7i2n8RJb9dWz8WXr8mWj9RpP8W3n8bW/8l2j+QJz
9Q5f9ToT8fWv9ZW/8lWj9VID8YnX7Pp79QZr9pWb+RJT8m2f9k2j9SYz8jWn9hmr8
UIT8fmv8VX78Xnn7d2z8ZHT7WHr7bm77Xnb7Z3D7YHH7RJOQRAAAACJ0Uk5TABAgI
CAwQEBAWF5gZXBwgICbn5+fo7+/vsLP39/f3urv73XwOA8AAAKfSURBVHja7dbJcu
IwFIXhIzCxMTMNcdwMDoMZY4NxeP9X66srEckYQlPVvcvPBhZ8dVSIAvz03xNV/Lu
q4Xq9Hgo8nfDqjXq97hS1yXZNhXg2Z3o+f1KnLqx62y17Pp5smp+158EUaW6I52rk
xLF3eoNpt1Ne+bR+Fd8U5Oc8Px6P5M0Evgq11ytpy0jgbk6e5cSxd2pb7yKOikpTo
uWyhbsNMsnpefZpOzsCI7c8brkM74/LqFSC7HkwVTu9lsB14ZJy745LlDdV5+3iQT
XC7s9z3pNEggOh9s3woOFqJT2BmzUSLnMQEEeeh2+rkraiOrjZeL+XXEBwyp71Ybg
+hWL+iltGt8ftKQI9QMzSlDxz9VofssIMdxitdJEvbo3jxqAGKXtt6N4OkpvgkmiF
a50Ch1UU8zab/Ya4Br/IUnnewHCHg+FEh7/ExUIXdq+KG4N7z3hfzXDkaa5FmGpdM
ENrYWWjaoDrJtJLu4ajFFfbUduryN1ue4brb2KpjSvgvETe53R24U6Ggz+RYJnsCT
MujmMJ9qELErkv9y7cyXAGtNCoI2Dqx9ymAl1bcYMLJ2NO5fZ2dmHLxiBGrJlxEAl
7M1HkTFUzseeiWHOxYK+CrwLltRX3qTk7/4PbTXDdaBHLxytMdcllaaA56U1RSEyU
56M0jotfYBLvynM091ni0GGtPO73nLkR7AaK6yqOKnG1g+wXrnqZz9nrw87bszdjj
n/dDGffbgdX9YmT4HykaoLTp/UABGfyypx7a1yFNb0wpl7BddW8geSO5JU5TE63xh
mOPb2uok8reN1Nrn4qjQNBlmfdvkB5beaoMgdP4LpFgbNuX3svtSwABoZ7WPOKa0I
nxgl7DurMdfFXVV7savjK8WQ1/cz5+Q9e7A/jUZeiPQO0fwAAAABJRU5ErkJggg==
}, @{innerHTML=; innerText=; outerHTML= ; ou
terText=; tagName=IMG; src=https://pss.bdstatic.com/static/superm
an/img/topnav/newfanyi-da0cea8f7e.png}, @{innerHTML=; innerText=;
outerHTML=
; ou
terText=; tagName=IMG; src=https://pss.bdstatic.com/static/superm
an/img/topnav/newfanyi-da0cea8f7e.png}, @{innerHTML=; innerText=;
outerHTML= ; outerText=; tagName=IMG;
src=https://pss.bdstatic.com/static/superman/img/topnav/newxueshu
icon-a5314d5c83.png}, @{innerHTML=; innerText=; outerHTML=
; outerText=; tagName=IMG;
src=https://pss.bdstatic.com/static/superman/img/topnav/newxueshu
icon-a5314d5c83.png}, @{innerHTML=; innerText=; outerHTML=![]() ; outerText=; tagName=IMG; src=https://pss.bdstati
c.com/static/superman/img/topnav/newbaike-889054f349.png}...}
InputFields : {@{innerHTML=; innerText=; outerHTML=; outerText=; tagName=INPUT; name=ie; type=hidde
n; value=utf-8}, @{innerHTML=; innerText=; outerHTML=; outerText=; tagName=INPUT; name=f;
type=hidden; value=8}, @{innerHTML=; innerText=; outerHTML=; outerText=; tagName=INPU
T; name=rsv_bp; type=hidden; value=1}, @{innerHTML=; innerText=;
outerHTML=; outerTe
xt=; tagName=INPUT; name=rsv_idx; type=hidden; value=1}...}
Links : {@{innerHTML=百度首页; innerText=百度首页; outerHTML=百度首页; outerText=百度首页; tagName=A; clas
s=toindex; href=/}, @{innerHTML=设置; innerText=设置; outerHTML=设置; outerText=设置; tagName=A; name=tj_settingic
on; class=pf; href=javascript:;}, @{innerHTML=登录; innerText=登
录; outerHTML=登录; outerText=登录;
tagName=A; name=tj_login; class=lb; onclick=return false;; href=h
ttps://passport.baidu.com/v2/?login&tpl=mn&u=http%3A%2F%2
Fwww.baidu.com%2F&sms=5}, @{innerHTML=
新闻
; innerText= 新闻 ; outerHTML=
新闻
; outerText= 新闻 ; tagName=A; class=mnav c-f
ont-normal c-color-t; href=http://news.baidu.com; target=_blank}.
..}
ParsedHtml : mshtml.HTMLDocumentClass
RawContentLength : 511136
; outerText=; tagName=IMG; src=https://pss.bdstati
c.com/static/superman/img/topnav/newbaike-889054f349.png}...}
InputFields : {@{innerHTML=; innerText=; outerHTML=; outerText=; tagName=INPUT; name=ie; type=hidde
n; value=utf-8}, @{innerHTML=; innerText=; outerHTML=; outerText=; tagName=INPUT; name=f;
type=hidden; value=8}, @{innerHTML=; innerText=; outerHTML=; outerText=; tagName=INPU
T; name=rsv_bp; type=hidden; value=1}, @{innerHTML=; innerText=;
outerHTML=; outerTe
xt=; tagName=INPUT; name=rsv_idx; type=hidden; value=1}...}
Links : {@{innerHTML=百度首页; innerText=百度首页; outerHTML=百度首页; outerText=百度首页; tagName=A; clas
s=toindex; href=/}, @{innerHTML=设置; innerText=设置; outerHTML=设置; outerText=设置; tagName=A; name=tj_settingic
on; class=pf; href=javascript:;}, @{innerHTML=登录; innerText=登
录; outerHTML=登录; outerText=登录;
tagName=A; name=tj_login; class=lb; onclick=return false;; href=h
ttps://passport.baidu.com/v2/?login&tpl=mn&u=http%3A%2F%2
Fwww.baidu.com%2F&sms=5}, @{innerHTML=
新闻
; innerText= 新闻 ; outerHTML=
新闻
; outerText= 新闻 ; tagName=A; class=mnav c-f
ont-normal c-color-t; href=http://news.baidu.com; target=_blank}.
..}
ParsedHtml : mshtml.HTMLDocumentClass
RawContentLength : 511136如果你觉得上面的信息还不够,那么下面的命令可以查看更详细的通信过程。
$ curl --trace output.txt www.baidu.com或者
$ curl --trace-ascii output.txt www.baidu.com运行后,请打开output.txt文件查看。
五、发送表单信息
发送表单信息有GET和POST两种方法。GET方法相对简单,只要把数据附在网址后面就行。
$ curl example.com?data=xxx
POST方法必须把数据和网址分开,curl就要用到--data参数。
$ curl -X POST --data "data=xxx" example.com
如果你的数据没有经过表单编码,还可以让curl为你编码,参数是`--data-urlencode`。
$ curl -X POST--data-urlencode "date=April 1" example.com/form.cgi
六、HTTP动词
curl默认的HTTP动词是GET,使用`-X`参数可以支持其他动词。
$ curl -X POST www.example.com
$ curl -X DELETE www.example.com
七、文件上传
假定文件上传的表单是下面这样:
你可以用curl这样上传文件:
$ curl --form upload=@localfilename --form press=OK [URL]
八、Referer字段
有时你需要在http request头信息中,提供一个referer字段,表示你是从哪里跳转过来的。
$ curl --referer http://www.example.com http://www.example.com
九、User Agent字段
这个字段是用来表示客户端的设备信息。服务器有时会根据这个字段,针对不同设备,返回不同格式的网页,比如手机版和桌面版。
curl可以这样模拟:
$ curl --user-agent "[User Agent]" [URL]
十、cookie
使用`--cookie`参数,可以让curl发送cookie。
$ curl --cookie "name=xxx" www.example.com
至于具体的cookie的值,可以从http response头信息的`Set-Cookie`字段中得到。
`-c cookie-file`可以保存服务器返回的cookie到文件,`-b cookie-file`可以使用这个文件作为cookie信息,进行后续的请求。
$ curl -c cookies http://example.com
$ curl -b cookies http://example.com
十一、增加头信息
有时需要在http request之中,自行增加一个头信息。`--header`参数就可以起到这个作用。
$ curl --header "Content-Type:application/json" http://example.com
十二、HTTP认证
有些网域需要HTTP认证,这时curl需要用到`--user`参数。
$ curl --user name:password example.com
(三)curl命令行参数
参考链接
- Curl Cookbook
不带有任何参数时,curl 就是发出 GET 请求。
curl http://www.baidu.com上面命令向www.baidu.com发出 GET 请求,服务器返回的内容会在命令行输出。
-A
-A参数指定客户端的用户代理标头,即User-Agent。curl 的默认用户代理字符串是curl/[version]。
$ curl -A 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36' https://www.baidu.com上面命令将User-Agent改成 Chrome 浏览器。
$ curl -A '' https://www.baidu.com上面命令会移除User-Agent标头。
也可以通过-H参数直接指定标头,更改User-Agent。
$ curl -H 'User-Agent: php/1.0' https://www.baidu.com-b
-b参数用来向服务器发送 Cookie。
$ curl -b 'data=admin' https://www.baidu.com上面命令会生成一个标头Cookie: data=admin,向服务器发送一个名为data、值为admin的 Cookie。
$ curl -b 'data1=admin;data2=admin2' https://www.baidu.com
上面命令发送两个 Cookie。
$ curl -b cookies.txt https://www.baidu.com
上面命令读取本地文件cookies.txt,里面是服务器设置的 Cookie(参见-c参数),将其发送到服务器。
-c
-c参数将服务器设置的 Cookie 写入一个文件。
$ curl -c cookies.txt https://www.baidu.com
上面命令将服务器的 HTTP 回应所设置 Cookie 写入文本文件cookies.txt。
-d
-d参数用于发送 POST 请求的数据体。
$ curl -d 'login=admin&password=admin123' -X POST https://www.baidu.com/login
# 或者
$ curl -d 'login=admin' -d 'password=admin123' -X POST https://www.baidu.com/login使用-d参数以后,HTTP 请求会自动加上标头Content-Type : application/x-www-form-urlencoded。并且会自动将请求转为 POST 方法,因此可以省略-X POST。
-d参数可以读取本地文本文件的数据,向服务器发送。
$ curl -d '@data.txt' https://www.baidu.com/login
上面命令读取data.txt文件的内容,作为数据体向服务器发送。
# $ cmd /c "curl -d test=123 http://httpbin.org/post"
$ curl -d test=123 http://httpbin.org/post
{
"args": {},
"data": "",
"files": {},
"form": {
"test": "123"
},
"headers": {
"Accept": "*/*",
"Content-Length": "8",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "curl/8.9.1",
"X-Amzn-Trace-Id": "Root=1-67a56bb0-6dd0b5a5665ff1d168572cf2"
},
"json": null,
"origin": "58.241.18.10",
"url": "http://httpbin.org/post"
}--data-urlencode
--data-urlencode参数等同于-d,发送 POST 请求的数据体,区别在于会自动将发送的数据进行 URL 编码。
$ curl --data-urlencode 'comment=hello world' https://www.baidu.com/login
上面代码中,发送的数据hello world之间有一个空格,需要进行 URL 编码。
-e
-e参数用来设置 HTTP 的标头Referer,表示请求的来源。
curl -e 'https://www.baidu.com?q=example' https://www.example.com上面命令将Referer标头设为https://www.baidu.com?q=example。
-H参数可以通过直接添加标头Referer,达到同样效果
curl -H 'Referer: https://www.baidu.com?q=example' https://www.example.com-F
-F参数用来向服务器上传二进制文件。
$ curl -F '[email protected]' https://www.baidu.com/profile上面命令会给 HTTP 请求加上标头Content-Type: multipart/form-data,然后将文件photo.png作为file字段上传。
-F参数可以指定 MIME 类型。
$ curl -F '[email protected];type=image/png' https://www.baidu.com/profile上面命令指定 MIME 类型为image/png,否则 curl 会把 MIME 类型设为application/octet-stream。
-F参数也可以指定文件名
$ curl -F '[email protected];filename=me.png' https://www.baidu.com/profile上面命令中,原始文件名为photo.png,但是服务器接收到的文件名为me.png。
-G
-G参数用来构造 URL 的查询字符串。
$ curl -G -d 'q=kitties' -d 'count=20' https://www.baidu.com/search
上面命令会发出一个 GET 请求,实际请求的 URL 为百度一下,你就知道/search?q=kitties&count=20。如果省略--G,会发出一个 POST 请求。
如果数据需要 URL 编码,可以结合--data--urlencode参数。
$ curl -G --data-urlencode 'comment=hello world' https://www.example.com
-H
-H参数添加 HTTP 请求的标头。
$ curl -H 'Accept-Language: en-US' https://www.baidu.com
上面命令添加 HTTP 标头Accept-Language: en-US。
$ curl -H 'Accept-Language: en-US' -H 'Secret-Message: xyzzy' https://www.baidu.com
上面命令添加两个 HTTP 标头。
$ curl -d '{"login": "emma", "pass": "123"}' -H 'Content-Type: application/json' https://www.baidu.com/login
上面命令添加 HTTP 请求的标头是Content-Type: application/json,然后用-d参数发送 JSON 数据。
-i
-i参数打印出服务器回应的 HTTP 标头。
$ curl -i https://www.baidu.com
上面命令收到服务器回应后,先输出服务器回应的标头,然后空一行,再输出网页的源码。
-I
-I参数向服务器发出 HEAD 请求,然会将服务器返回的 HTTP 标头打印出来。
$ curl -I https://www.baidu.com
上面命令输出服务器对 HEAD 请求的回应。
--head参数等同于-I。
$ curl --head https://www.baidu.com
-k
-k参数指定跳过 SSL 检测。
$ curl -k https://www.baidu.com
上面命令不会检查服务器的 SSL 证书是否正确。
-L
-L参数会让 HTTP 请求跟随服务器的重定向。curl 默认不跟随重定向。
$ curl -L -d 'tweet=hi' https://api.twitter.com/tweet
--limit-rate
--limit-rate用来限制 HTTP 请求和回应的带宽,模拟慢网速的环境。
$ curl --limit-rate 200k https://www.baidu.com
上面命令将带宽限制在每秒 200K 字节。
-o
-o参数将服务器的回应保存成文件,等同于wget命令。
$ curl -o example.html https://www.example.com
上面命令将www.example.com保存成example.html。
-O
-O参数将服务器回应保存成文件,并将 URL 的最后部分当作文件名。
$ curl -O https://www.example.com/foo/bar.html
上面命令将服务器回应保存成文件,文件名为bar.html。
-s
-s参数将不输出错误和进度信息。
$ curl -s https://www.example.com
上面命令一旦发生错误,不会显示错误信息。不发生错误的话,会正常显示运行结果。
如果想让 curl 不产生任何输出,可以使用下面的命令。
$ curl -s -o /dev/null https://google.com
-S
-S参数指定只输出错误信息,通常与-s一起使用。
$ curl -s -o /dev/null https://www.baidu.com
上面命令没有任何输出,除非发生错误。
-u
-u参数用来设置服务器认证的用户名和密码。
$ curl -u 'admin:admin12345' https://google.com/login
上面命令设置用户名为admin,密码为admin12345,然后将其转为 HTTP 标头Authorization: Basic Ym9iOjEyMzQ1。
curl 能够识别 URL 里面的用户名和密码。
$ curl https://admin:[email protected]/login
上面命令能够识别 URL 里面的用户名和密码,将其转为上个例子里面的 HTTP 标头。
$ curl -u 'admin' https://google.com/login
上面命令只设置了用户名,执行后,curl 会提示用户输入密码。
-v
-v参数输出通信的整个过程,用于调试。
$ curl -v https://www.example.com--trace参数也可以用于调试,还会输出原始的二进制数据
$ curl --trace - https://www.example.com
-x
-x参数指定 HTTP 请求的代理。
$ curl -x socks5://james:[email protected]:8080 https://www.example.com上面命令指定 HTTP 请求通过myproxy.com:8080的 socks5 代理发出。
如果没有指定代理协议,默认为 HTTP。
$ curl -x james:[email protected]:8080 https://www.example.com上面命令中,请求的代理使用 HTTP 协议。
-X
-X参数指定 HTTP 请求的方法。
$ curl -X POST https://www.example.com
上面命令对https://www.example.com发出 POST 请求