代码随想录算法训练营Day10 | Leetcode 150逆波兰表达式求值、239滑动窗口最大值、 347前 K 个高频元素
代码随想录算法训练营Day10 | Leetcode 150逆波兰表达式求值、239滑动窗口最大值、 347前 K 个高频元素
一、反转字符串
相关题目:Leetcode150
文档讲解:Leetcode150
视频讲解:Leetcode150
1. Leetcode150.逆波兰表达式求值
给你一个字符串数组 tokens ,表示一个根据 逆波兰表示法 表示的算术表达式。请你计算该表达式。返回一个表示表达式值的整数。
注意:
- 有效的算符为 ‘+’、‘-’、‘*’ 和 ‘/’ 。
- 每个操作数(运算对象)都可以是一个整数或者另一个表达式。
- 两个整数之间的除法总是 向零截断 。
- 表达式中不含除零运算。
- 输入是一个根据逆波兰表示法表示的算术表达式。
- 答案及所有中间计算结果可以用 32 位 整数表示。
逆波兰表达式是一种后缀表达式,所谓后缀就是指算符写在后面。
- 平常使用的算式则是一种中缀表达式,如 ( 1 + 2 ) * ( 3 + 4 ) 。
- 该算式的逆波兰表达式写法为 ( ( 1 2 + ) ( 3 4 + ) * ) 。
逆波兰表达式主要有以下两个优点:
- 去掉括号后表达式无歧义,上式即便写成 1 2 + 3 4 + * 也可以依据次序计算出正确结果。
- 适合用栈操作运算:遇到数字则入栈;遇到算符则取出栈顶两个数字进行计算,并将结果压入栈中
- 思路:
- 每一个子表达式要得出一个结果,然后拿这个结果再进行运算,类似于相邻字符串消除的过程,可以考虑 Leetcode1047.删除字符串中的所有相邻重复项 的方法。
- 使用栈
from operator import add, sub, mul
def div(x, y):
# 使用整数除法的向零取整方式
return int(x / y) if x * y > 0 else -(abs(x) // abs(y))
class Solution(object):
op_map = {'+': add, '-': sub, '*': mul, '/': div}
def evalRPN(self, tokens: List[str]) -> int:
stack = []
for token in tokens:
if token not in {'+', '-', '*', '/'}:
stack.append(int(token))
else:
op2 = stack.pop()
op1 = stack.pop()
stack.append(self.op_map[token](op1, op2)) # 第一个出来的在运算符后面
return stack.pop()
- 使用 eval()
class Solution(object):
def evalRPN(self, tokens: List[str]) -> int:
stack = []
for token in tokens:
# 判断是否为数字,因为isdigit()不识别负数,故需要排除第一位的符号
if token.isdigit() or (len(token)>1 and token[1].isdigit()):
stack.append(token)
else:
op2 = stack.pop()
op1 = stack.pop()
# 由题意"The division always truncates toward zero",所以使用int()可以天然取整
stack.append(str(int(eval(op1 + token + op2))))
return int(stack.pop())
二、滑动窗口最大值
相关题目:Leetcode239
文档讲解:Leetcode239
视频讲解:Leetcode239
1. Leetcode239.滑动窗口最大值
给定一个数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。返回滑动窗口中的最大值。
- 进阶:你能在线性时间复杂度内解决此题吗?
- 思路:
- 目标:需要一个队列,这个队列存放窗口里的元素,然后随着窗口的移动,队列也一进一出,每次移动之后,从队列中可得到最大值。
- 问题:
- 队列里的元素一定是要排序的,而且要最大值放在出队口,不然无法得到最大值。但如果把窗口里的元素都放进队列里,窗口移动的时候队列需要弹出元素,已经排序之后的队列怎么能把窗口要移除的元素(这个元素不一定是最大值)弹出?
- 解决方案:
- 其实队列没有必要维护窗口里的所有元素,只需要维护有可能成为窗口里最大值的元素就可以了,同时保证队列里的元素数值是由大到小的。
- 单调队列可维护队列里的元素:
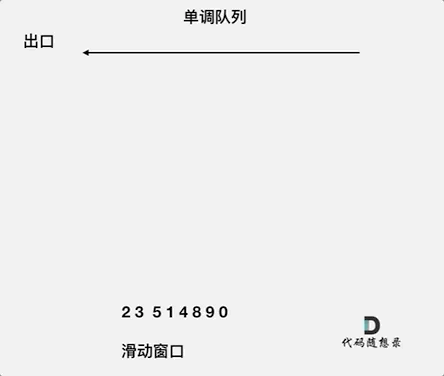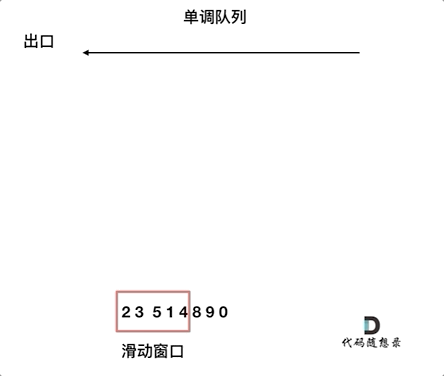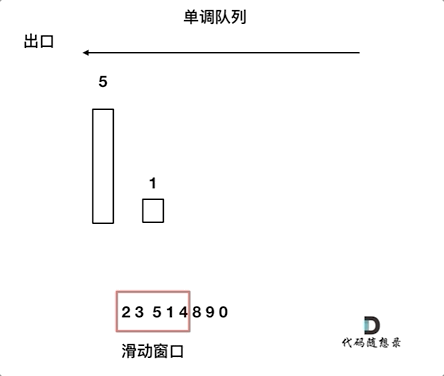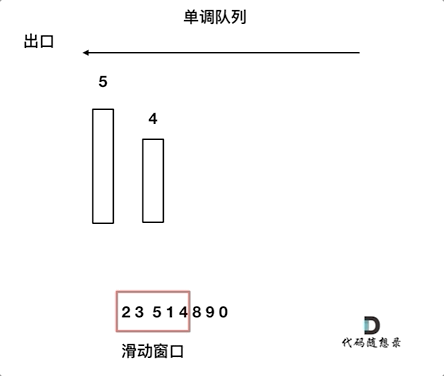
对于窗口里的元素{2, 3, 5, 1 ,4},单调队列里只维护{5, 4} 就够了,保持单调队列里单调递减,此时队列出口元素就是窗口里最大元素。
- 设计单调队列:
- pop(value):如果窗口移除的元素 value 等于单调队列的出口元素,那么队列弹出元素,否则不用任何操作。
- push(value):如果 push 的元素 value 大于入口元素的数值,那么就将队列入口的元素弹出,直到push元素的数值小于等于队列入口元素的数值为止。
- que.front():返回当前窗口的最大值。
- 使用自定义的单调队列类
from collections import deque
class MyQueue: #单调队列(从大到小
def __init__(self):
self.queue = deque() #这里需要使用deque实现单调队列,直接使用list会超时
#每次弹出的时候,比较当前要弹出的数值是否等于队列出口元素的数值,如果相等则弹出。
#同时pop之前判断队列当前是否为空。
def pop(self, value):
if self.queue and value == self.queue[0]:
self.queue.popleft()#list.pop()时间复杂度为O(n),这里需要使用collections.deque()
#如果push的数值大于入口元素的数值,那么就将队列后端的数值弹出,直到push的数值小于等于队列入口元素的数值为止。
#这样就保持了队列里的数值是单调从大到小的了。
def push(self, value):
while self.queue and value > self.queue[-1]:
self.queue.pop()
self.queue.append(value)
#查询当前队列里的最大值 直接返回队列前端也就是front就可以了。
def front(self):
return self.queue[0]
class Solution:
def maxSlidingWindow(self, nums: List[int], k: int) -> List[int]:
que = MyQueue()
result = []
for i in range(k): #先将前k的元素放进队列
que.push(nums[i])
result.append(que.front()) #result 记录前k的元素的最大值
for i in range(k, len(nums)):
que.pop(nums[i - k]) #滑动窗口移除最前面元素
que.push(nums[i]) #滑动窗口前加入最后面的元素
result.append(que.front()) #记录对应的最大值
return result
- 直接用单调队列
from collections import deque
class Solution:
def maxSlidingWindow(self, nums: List[int], k: int) -> List[int]:
max_list = [] # 结果集合
kept_nums = deque() # 单调队列
for i in range(len(nums)):
update_kept_nums(kept_nums, nums[i]) # 右侧新元素加入
if i >= k and nums[i - k] == kept_nums[0]: # 左侧旧元素如果等于单调队列头元素,需要移除头元素
kept_nums.popleft()
if i >= k - 1:
max_list.append(kept_nums[0])
return max_list
def update_kept_nums(kept_nums, num): # num 是新加入的元素
# 所有小于新元素的队列尾部元素,在新元素出现后,都是没有价值的,都需要被移除
while kept_nums and num > kept_nums[-1]:
kept_nums.pop()
kept_nums.append(num)
三、前 K 个高频元素
相关题目:Leetcode347
文档讲解:Leetcode347
视频讲解:Leetcode347
1. Leetcode347.前 K 个高频元素
给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。
提示:
- 你可以假设给定的 k 总是合理的,且 1 ≤ k ≤ 数组中不相同的元素的个数。
- 你的算法的时间复杂度必须优于 O ( n log n ) O(n \log n) O(nlogn) , n 是数组的大小。
- 题目数据保证答案唯一,换句话说,数组中前 k 个高频元素的集合是唯一的。
-
思路:
- 三个步骤:
- 要统计元素出现频率:使用 map 来进行统计。
- 对频率排序:使用一种容器适配器——优先级队列。
- 找出前 K 个高频元素。
- 优先级队列常见实现方式:
- 使用 heapq 模块
Python 的内置模块 heapq 提供了对列表进行堆操作的函数,可以高效地实现一个基于堆的数据结构。利用它,可以构造一个最小堆,确保堆顶永远是最小的元素(即优先级最高的元素):- heapq.heappush(heap, item):将新元素加入堆中。
- heapq.heappop(heap):弹出堆中最小的元素。
- 使用 queue.PriorityQueue 类
Python 标准库 queue 模块中提供了 PriorityQueue 类,它是一个线程安全的优先级队列实现。它内部也是基于堆实现的,但提供了更直观易用的接口,例如:- put(item):将元素放入队列。
- get():取出并删除优先级最高的元素。
- 使用 heapq 模块
- 三个步骤:
-
注意:
- 选择小顶堆而非大顶堆:
- 定义一个大小为 K 的大顶堆,在每次移动更新大顶堆的时候,每次弹出都把最大的元素弹出去了,那么难以保留前 K 个高频元素,而且使用大顶堆就要把所有元素都进行排序。
- 当用小顶堆,每次将最小的元素弹出,最后小顶堆里积累的才是前k个最大元素。
- 选择小顶堆而非大顶堆:
-
使用小顶堆
#时间复杂度:O(nlogk)
#空间复杂度:O(n)
import heapq
class Solution:
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
#要统计元素出现频率
map_ = {} #nums[i]:对应出现的次数
for i in range(len(nums)):
map_[nums[i]] = map_.get(nums[i], 0) + 1
#对频率排序
#定义一个小顶堆,大小为k
pri_que = [] #小顶堆
#用固定大小为k的小顶堆,扫描所有频率的数值
for key, freq in map_.items():
heapq.heappush(pri_que, (freq, key))
if len(pri_que) > k: #如果堆的大小大于了K,则队列弹出,保证堆的大小一直为k
heapq.heappop(pri_que)
#找出前K个高频元素,因为小顶堆先弹出的是最小的,所以倒序来输出到数组
result = [0] * k
for i in range(k-1, -1, -1):
result[i] = heapq.heappop(pri_que)[1]
return result
- 使用字典
class Solution:
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
# 使用字典统计数字出现次数
time_dict = defaultdict(int)
for num in nums:
time_dict[num] += 1
# 更改字典,key为出现次数,value为相应的数字的集合
index_dict = defaultdict(list)
for key in time_dict:
index_dict[time_dict[key]].append(key)
# 排序
key = list(index_dict.keys())
key.sort()
result = []
cnt = 0
# 获取前k项
while key and cnt != k:
result += index_dict[key[-1]]
cnt += len(index_dict[key[-1]])
key.pop()
return result[0: k]