RocketMQ新消费者加入后的队列一致性保障机制详解
RocketMQ新消费者加入后的队列一致性保障机制详解
RocketMQ作为一个高性能的分布式消息中间件,其消费者负载均衡机制是保障系统可扩展性和稳定性的关键。当新消费者加入消费组时,如何保证各个消费者之间的队列分配一致性是一个核心问题。下面将深入解析其详细原理和运作机制。
消费模式与队列分配基础
首先需要明确的是,在RocketMQ中,队列一致性问题主要出现在集群消费模式下。在这种模式中,一条消息只会被消费组内的一个消费者处理,因此需要明确哪个消费者负责哪些队列。
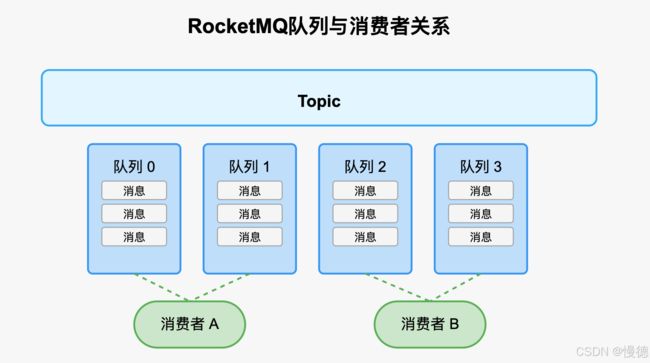
重平衡核心机制
RocketMQ的队列分配一致性是通过名为"Rebalance"的重平衡机制实现的。这个机制负责在消费组成员变化时重新分配消息队列。
重平衡触发时机
重平衡会在以下情况下触发:
- 消费组中有新消费者加入
- 现有消费者下线(正常退出或异常宕机)
- Broker与消费者之间的心跳超时
- 消息队列数量发生变化(如Topic扩容)
- 消费者订阅关系发生变化
心跳与成员管理机制
RocketMQ通过心跳机制来感知消费组成员变化:
// MQClientInstance.java中的心跳发送方法
private void sendHeartbeatToAllBroker() {
final HeartbeatData heartbeatData = this.prepareHeartbeatData();
final boolean producerEmpty = heartbeatData.getProducerDataSet().isEmpty();
final boolean consumerEmpty = heartbeatData.getConsumerDataSet().isEmpty();
if (producerEmpty && consumerEmpty) {
log.warn("sending heartbeat, but no producer and no consumer");
return;
}
for (Map.Entry<String, HashMap<Long, String>> entry : this.brokerAddrTable.entrySet()) {
String brokerName = entry.getKey();
HashMap<Long, String> oneTable = entry.getValue();
if (oneTable != null) {
for (Map.Entry<Long, String> entry1 : oneTable.entrySet()) {
Long brokerId = entry1.getKey();
String brokerAddr = entry1.getValue();
if (brokerAddr != null) {
try {
// 异步发送心跳
this.remotingClient.invokeOneway(brokerAddr, heartbeatData.encode(), 3000);
log.debug("send heart beat to broker[{} {} {}] success",
brokerName, brokerId, brokerAddr);
} catch (Exception e) {
log.error("send heart beat to broker exception", e);
}
}
}
}
}
}
// ConsumerData结构,包含在HeartbeatData中
public class ConsumerData implements Comparable<ConsumerData> {
private String groupName;
private ConsumeType consumeType;
private MessageModel messageModel;
private ConsumeFromWhere consumeFromWhere;
private Set<SubscriptionData> subscriptionDataSet = new HashSet<SubscriptionData>();
private boolean unitMode;
// ... 其他代码省略
}
心跳机制的具体运作过程:
- 每个消费者每30秒向所有已知的Broker发送心跳
- 心跳包含消费者ID、消费组名、订阅关系等信息
- Broker收到心跳后更新内存中的消费者注册表
- Broker将消费者注册信息同步给同一消费组的其他成员
- 如果Broker在120秒内未收到某消费者心跳,会将其标记为离线
重平衡执行流程
RocketMQ采用客户端主动执行重平衡的模式,而非服务端集中分配。这意味着每个消费者都会独立计算自己应该消费哪些队列。
重平衡的详细流程如下:
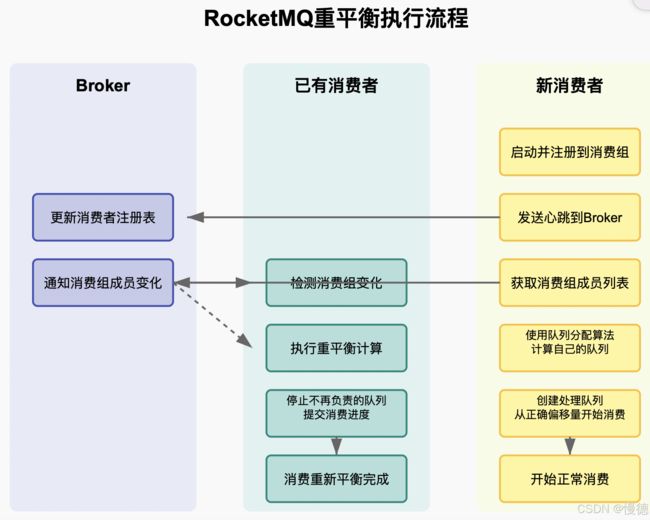
重要的是,所有消费者都使用相同的算法和相同的输入数据(队列列表和消费者列表)进行计算,因此能够得出一致的结果,即使没有中心化的协调也能保持一致性。
队列分配算法详解
RocketMQ提供了多种队列分配算法,每个消费组可以根据需要选择合适的算法。
平均分配算法(默认)
最常用的是平均分配算法(AllocateMessageQueueAveragely),其核心逻辑如下:
public class AllocateMessageQueueAveragely implements AllocateMessageQueueStrategy {
@Override
public List<MessageQueue> allocate(String consumerGroup, String currentCID,
List<MessageQueue> mqAll, List<String> cidAll) {
// 参数校验
if (currentCID == null || currentCID.length() < 1) {
throw new IllegalArgumentException("currentCID is empty");
}
if (mqAll == null || mqAll.isEmpty()) {
throw new IllegalArgumentException("mqAll is null or mqAll empty");
}
if (cidAll == null || cidAll.isEmpty()) {
throw new IllegalArgumentException("cidAll is null or cidAll empty");
}
// 如果当前消费者不在消费组列表中,返回空列表
if (!cidAll.contains(currentCID)) {
log.info("[BUG] ConsumerGroup: {} The consumerId: {} not in cidAll: {}",
consumerGroup, currentCID, cidAll);
return new ArrayList<MessageQueue>();
}
// 获取当前消费者在消费组中的索引
int index = cidAll.indexOf(currentCID);
// 消费者总数
int mod = cidAll.size();
// 结果集合
List<MessageQueue> result = new ArrayList<MessageQueue>();
// 核心算法:轮询分配
// 遍历所有队列,将索引对消费者数取模等于当前消费者索引的队列分配给当前消费者
for (int i = 0; i < mqAll.size(); i++) {
if (i % mod == index) {
result.add(mqAll.get(i));
}
}
return result;
}
}
该算法利用简单的取模运算,将所有队列尽可能平均地分配给各个消费者。例如有3个消费者,10个队列,则分配结果为:
- 消费者0:队列0、3、6、9
- 消费者1:队列1、4、7
- 消费者2:队列2、5、8
虽然算法简单高效,但在消费者数量变化时可能导致大范围的队列迁移,影响系统稳定性。
一致性哈希算法
为了解决平均分配算法在扩缩容时队列大规模迁移的问题,RocketMQ提供了一致性哈希算法(AllocateMessageQueueConsistentHash):
public class AllocateMessageQueueConsistentHash implements AllocateMessageQueueStrategy {
private final int virtualNodeCnt;
private final HashFunction customHashFunction;
public AllocateMessageQueueConsistentHash() {
this(10); // 默认10个虚拟节点
}
public AllocateMessageQueueConsistentHash(final int virtualNodeCnt) {
this.virtualNodeCnt = virtualNodeCnt;
// 使用Murmur3哈希算法,随机种子为0
this.customHashFunction = Hashing.murmur3_32(0);
}
@Override
public List<MessageQueue> allocate(String consumerGroup, String currentCID,
List<MessageQueue> mqAll, List<String> cidAll) {
// 参数校验(省略)...
// 构建一致性哈希环
TreeMap<Long, String> consumerHashring = new TreeMap<Long, String>();
for (String cid : cidAll) {
// 为每个消费者创建virtualNodeCnt个虚拟节点
for (int i = 0; i < virtualNodeCnt; i++) {
long hash = customHashFunction.hashString(cid + "#" + i, Charset.defaultCharset()).asLong();
consumerHashring.put(hash, cid);
}
}
List<MessageQueue> result = new ArrayList<MessageQueue>();
for (MessageQueue mq : mqAll) {
// 计算队列的哈希值
long mqHashCode = customHashFunction.hashString(mq.toString(), Charset.defaultCharset()).asLong();
// 在哈希环上找到第一个大于该哈希值的消费者
SortedMap<Long, String> tailMap = consumerHashring.tailMap(mqHashCode);
String consumerNode;
if (tailMap.isEmpty()) {
// 如果没有找到,则取哈希环的第一个消费者
consumerNode = consumerHashring.firstEntry().getValue();
} else {
// 否则取tailMap的第一个消费者
consumerNode = tailMap.get(tailMap.firstKey());
}
// 如果分配给当前消费者,则添加到结果集
if (currentCID.equals(consumerNode)) {
result.add(mq);
}
}
return result;
}
}
一致性哈希算法的优点:
- 消费者变化时,只有部分队列需要重新分配
- 分配结果相对稳定,减少系统波动
- 通过虚拟节点技术,提高了负载均衡性
其他分配算法
除了上述两种算法,RocketMQ还提供了:
- 环形平均算法(AllocateMessageQueueAveragelyByCircle):相比普通平均算法,在分配均匀性上有所优化
- 机房感知算法(AllocateMessageQueueByMachineRoom):考虑消费者与Broker的物理位置,优先就近分配
- 手动配置(AllocateMessageQueueByConfig):允许用户手动指定哪个消费者负责哪些队列
一致性保障机制
重平衡过程中,如何保证消息不重复、不丢失,以及处理好旧消费者与新消费者之间的交接是关键挑战。
消费进度管理
RocketMQ中的消费进度(消费位点)管理是队列一致性的重要保障:
// 消费进度管理器
public class RemoteBrokerOffsetStore implements OffsetStore {
// 每5秒持久化一次消费进度
private static final long OFFSET_PERSIST_INTERVAL = 5 * 1000;
// 定期持久化消费进度
public void persistAll(Set<MessageQueue> mqs) {
if (null == mqs || mqs.isEmpty())
return;
final HashSet<MessageQueue> unusedMQ = new HashSet<MessageQueue>();
if (!mqs.isEmpty()) {
for (MessageQueue mq : this.offsetTable.keySet()) {
if (!mqs.contains(mq)) {
unusedMQ.add(mq);
}
}
}
// 持久化消费进度到Broker端
for (MessageQueue mq : mqs) {
AtomicLong offset = this.offsetTable.get(mq);
if (offset != null) {
try {
this.updateConsumeOffsetToBroker(mq, offset.get());
} catch (Exception e) {
log.error("updateConsumeOffsetToBroker exception, " + mq.toString(), e);
}
}
}
// 对于不再消费的队列,移除本地记录
if (!unusedMQ.isEmpty()) {
for (MessageQueue mq : unusedMQ) {
this.offsetTable.remove(mq);
log.info("remove unused mq, {}, {}", mq, this.groupName);
}
}
}
// 从Broker获取消费进度
public long fetchConsumeOffsetFromBroker(MessageQueue mq) throws MQBrokerException {
FindBrokerResult findBrokerResult = this.mQClientFactory.findBrokerAddressInAdmin(mq.getBrokerName());
if (null == findBrokerResult) {
// 可能Broker地址找不到,尝试更新Broker信息后再次查找
this.mQClientFactory.updateTopicRouteInfoFromNameServer(mq.getTopic());
findBrokerResult = this.mQClientFactory.findBrokerAddressInAdmin(mq.getBrokerName());
}
if (findBrokerResult != null) {
// 从Broker查询消费进度
QueryConsumerOffsetRequestHeader requestHeader = new QueryConsumerOffsetRequestHeader();
requestHeader.setTopic(mq.getTopic());
requestHeader.setConsumerGroup(this.groupName);
requestHeader.setQueueId(mq.getQueueId());
return this.mQClientFactory.getMQClientAPIImpl().queryConsumerOffset(
findBrokerResult.getBrokerAddr(), requestHeader, 3000);
} else {
throw new MQClientException("Fetch consumer offset from broker exception", null);
}
}
}
在RocketMQ中,消费进度管理是保障重平衡一致性的关键机制。重平衡时,新消费者会从Broker获取最新消费进度,从正确位置开始消费,这确保了消息不丢失也不重复。
处理队列状态管理
当重平衡发生时,消费者需要妥善管理处理队列(ProcessQueue)的状态:
// 处理队列实现类
public class ProcessQueue {
private final ReadWriteLock lockTreeMap = new ReentrantReadWriteLock();
// 消息存储结构,key是消息队列偏移量,value是消息
private final TreeMap<Long, MessageExt> msgTreeMap = new TreeMap<Long, MessageExt>();
// 消息总数
private final AtomicLong msgCount = new AtomicLong();
// 队列是否被丢弃(不再消费)
private volatile boolean dropped = false;
// 上次拉取时间
private volatile long lastPullTimestamp = System.currentTimeMillis();
// 上次消费时间
private volatile long lastConsumeTimestamp = System.currentTimeMillis();
// 是否正在消费中
private volatile boolean consuming = false;
// 锁定时间戳
private volatile long locked = 0;
/**
* 锁定处理队列,用于顺序消费
*/
public boolean lockConsume() {
this.locked = System.currentTimeMillis();
return true;
}
/**
* 是否需要丢弃该处理队列
*/
public boolean isDropped() {
return dropped;
}
/**
* 将处理队列标记为丢弃状态
*/
public void setDropped(boolean dropped) {
this.dropped = dropped;
}
/**
* 清空处理队列,用于队列迁移
*/
public void clear() {
try {
this.lockTreeMap.writeLock().lockInterruptibly();
try {
this.msgTreeMap.clear();
this.msgCount.set(0);
} finally {
this.lockTreeMap.writeLock().unlock();
}
} catch (InterruptedException e) {
log.error("clear exception", e);
}
}
/**
* 移除已消费的消息
*/
public long removeMessage(final List<MessageExt> msgs) {
long result = -1;
try {
this.lockTreeMap.writeLock().lockInterruptibly();
try {
if (!msgTreeMap.isEmpty()) {
result = msgTreeMap.firstKey();
int removedCnt = 0;
for (MessageExt msg : msgs) {
MessageExt prev = msgTreeMap.remove(msg.getQueueOffset());
if (prev != null) {
removedCnt++;
}
}
msgCount.addAndGet(-removedCnt);
}
} finally {
this.lockTreeMap.writeLock().unlock();
}
} catch (Throwable t) {
log.error("removeMessage exception", t);
}
return result;
}
}
处理队列的状态管理机制确保了:
- 当队列不再由当前消费者负责时,将被标记为丢弃(dropped),不再向其中添加新消息
- 处理队列中未处理完的消息会继续处理,直到全部完成
- 顺序消费时,处理队列会被锁定,确保迁移时不破坏顺序性
重平衡实现中的一致性保障
RocketMQ在实现重平衡时,采取了一系列措施保障消费的一致性:
public boolean updateProcessQueueTableInRebalance(final String topic, final Set<MessageQueue> mqSet,
final boolean isOrder) {
boolean changed = false;
// 获取当前负责的队列集合
Iterator<Entry<MessageQueue, ProcessQueue>> it = this.processQueueTable.entrySet().iterator();
while (it.hasNext()) {
Entry<MessageQueue, ProcessQueue> next = it.next();
MessageQueue mq = next.getKey();
ProcessQueue pq = next.getValue();
// 只处理当前Topic相关的队列
if (mq.getTopic().equals(topic)) {
// 如果重平衡后不再负责该队列
if (!mqSet.contains(mq)) {
// 顺序消费可能需要特殊处理
if (pq.isPullExpired()) {
log.warn("doRebalance, {}, ProcessQueue expired, remove it", mq);
it.remove();
changed = true;
continue;
}
// 顺序消费模式下需要尝试解锁队列
if (isOrder && !pq.getLockConsume().tryLock(1000, TimeUnit.MILLISECONDS)) {
log.warn("doRebalance, {}, ProcessQueue try to lock consuming, but failed", mq);
// 如果无法获取锁,说明有消息正在处理,暂不移除
continue;
}
// 标记队列为丢弃状态,暂停拉取,但已拉取的消息会继续处理
pq.setDropped(true);
log.info("doRebalance, {}, dropIt={}", mq, pq.isDropped());
// 解锁
if (isOrder) {
pq.getLockConsume().unlock();
}
// 停止拉取任务
this.offsetStore.persist(mq);
this.offsetStore.removeOffset(mq);
it.remove();
changed = true;
} else if (pq.isPullExpired()) {
// 虽然仍负责该队列,但拉取任务已过期,需要重新启动拉取
log.warn("doRebalance, {}, ProcessQueue expired, fix it", mq);
this.offsetStore.persist(mq);
this.offsetStore.removeOffset(mq);
it.remove();
changed = true;
}
}
}
// 处理新分配的队列
List<PullRequest> pullRequestList = new ArrayList<PullRequest>();
for (MessageQueue mq : mqSet) {
if (!this.processQueueTable.containsKey(mq)) {
// 从正确的偏移量开始拉取
long nextOffset = this.computePullFromWhere(mq);
if (nextOffset >= 0) {
ProcessQueue pq = new ProcessQueue();
// 添加到处理队列表
this.processQueueTable.put(mq, pq);
// 创建拉取请求
PullRequest pullRequest = new PullRequest();
pullRequest.setConsumerGroup(consumerGroup);
pullRequest.setNextOffset(nextOffset);
pullRequest.setMessageQueue(mq);
pullRequest.setProcessQueue(pq);
pullRequestList.add(pullRequest);
changed = true;
log.info("doRebalance, {}, add a new pull request {}", consumerGroup, mq);
} else {
log.warn("doRebalance, {}, add new mq failed, offset {}", mq, nextOffset);
}
}
}
// 将新队列的拉取请求添加到拉取服务
this.dispatchPullRequest(pullRequestList);
return changed;
}
从这段关键代码中可以看出RocketMQ在重平衡时的一致性保障机制:
- 优雅停止原则:不再负责的队列会被标记为丢弃,但已拉取的消息会继续处理完毕
- 顺序消费保障:顺序消费模式下,会先尝试获取队列消费锁,确保消息处理的顺序性
- 消费进度同步:在移除队列前持久化消费进度,确保其他消费者能够从正确位置继续消费
- 正确偏移量计算:新分配的队列会通过
computePullFromWhere方法计算正确的起始偏移量
实际案例分析
让我们通过一个实际场景来分析整个过程,假设有以下情况:
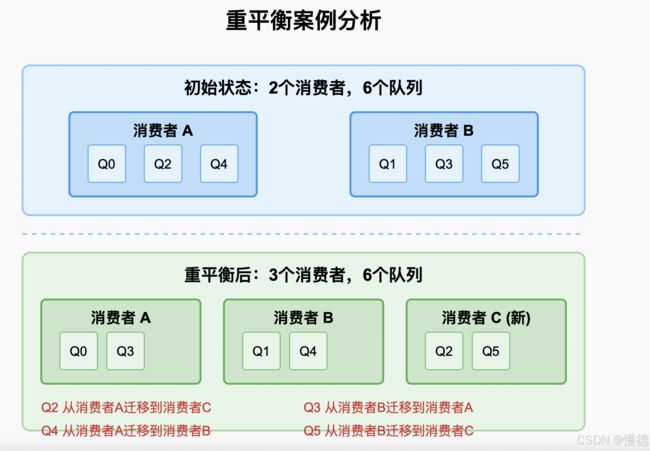
案例详细分析
-
初始状态
- 消费者A负责队列Q0、Q2、Q4
- 消费者B负责队列Q1、Q3、Q5
-
当消费者C加入后
- 所有消费者重新执行分配算法
- 使用平均分配算法,3个消费者均匀分配6个队列
- 结果是每个消费者分配到2个队列
-
队列迁移过程
- Q2从消费者A迁移到C:消费者A会标记Q2为丢弃状态,完成未处理消息后持久化消费进度;消费者C从Broker获取Q2的最新消费位点开始消费
- Q3从消费者B迁移到A:类似流程
- Q4从消费者A迁移到B:类似流程
- Q5从消费者B迁移到C:类似流程
-
整个过程中的一致性保障
- 所有消费者使用相同算法和输入数据,计算结果一致
- 旧的处理队列会优雅停止,确保已拉取的消息不丢失
- 消费进度持久化确保新消费者能从正确位置开始消费
- 对于顺序消费,会加锁确保顺序性不被破坏
性能优化与最佳实践
在实际应用中,以下是一些优化RocketMQ重平衡的最佳实践:
减少重平衡频率
频繁的重平衡会影响系统稳定性和性能,可以采取以下措施:
- 错峰上线:新消费者上线时错开时间,避免同时触发重平衡
- 合理配置心跳超时时间:可以适当延长心跳超时时间,减少因网络抖动导致的假死判断
- 使用固定IP/机器名:避免使用随机生成的消费者ID,确保在消费者重启时ID保持一致
选择合适的分配算法
针对不同场景选择最适合的分配算法:
- 小规模集群:默认的平均分配算法简单高效
- 大规模频繁扩缩容:一致性哈希算法可以减少队列迁移范围
- 多机房部署:使用机房感知算法减少跨机房流量
- 特殊业务需求:可以自定义分配算法或使用手动配置方式
优化消费者配置
- 合理设置并发度:消费线程数不宜过多,一般建议为处理队列数的1-2倍
- 调整拉取批量:根据消息大小和处理时间调整拉取批量
- 消费速度控制:使用流控机制避免消费过快导致下游系统压力过大
监控与告警
建立完善的监控系统,关注以下指标:
- 消费延迟:重平衡期间通常会有短暂延迟上升,需要监控以确保恢复正常
- 重平衡频率:过于频繁的重平衡可能意味着系统配置有问题
- 消费者数量波动:消费者频繁上下线需要及时告警
- 消费进度异常:消费位点跳跃或回退可能意味着重平衡出现问题
总结
RocketMQ在处理新消费者加入时的队列一致性保障是一套完善的机制:
- 分布式协作:所有消费者基于相同的算法和数据独立计算,无需中心协调
- 状态管理:通过处理队列状态和消费进度管理确保消息不丢失不重复
- 优雅切换:队列迁移时采用优雅停止策略,确保平滑过渡
- 多种算法:提供多种分配算法适应不同场景需求
这套机制使得RocketMQ在消费者数量动态变化时仍能保持高可用和数据一致性,是其作为高性能分布式消息中间件的重要特性。