Dify知识库-RAG流程解析
Dify知识库RAG代码流程图
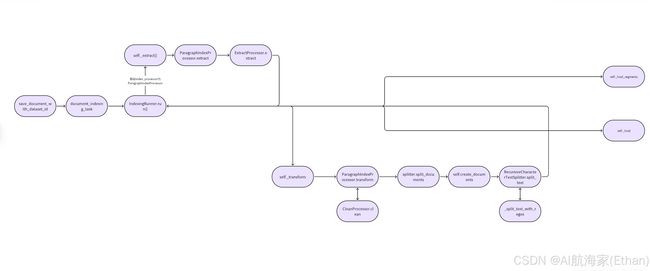
源码解析
document_indexing_task
代码目录:dify/api/tasks/document_indexing_task.py
主要做了以下两件事
1.查询dataset的文章限制是否超出限制,超出抛出异常,将所有document_ids状态改为 error 如果正 常,则更新所有文章状态为 “解析中” parsing
@shared_task(queue='dataset')
def document_indexing_task(dataset_id: str, document_ids: list):
"""
异步处理文档索引任务。
:param dataset_id:数据集ID
:param document_ids:需要处理的文档ID列表
Usage: document_indexing_task.delay(dataset_id, document_id)
主要功能:1.查询dataset的文章限制是否超出 入宫超出抛出异常,将所有document_ids状态改为 error 如果正常,则更新所有文章状态为 “解析中” parsing
2.IndexingRunner.run()中包含了RAG索引的实现细节
"""
# 初始化文档列表和开始时间
documents = []
start_at = time.perf_counter()
# 从数据库中获取数据集信息
dataset = db.session.query(Dataset).filter(Dataset.id == dataset_id).first()
# 检查文档数量限制
features = FeatureService.get_features(dataset.tenant_id)
try:
if features.billing.enabled:
# 获取向量空间信息
vector_space = features.vector_space
count = len(document_ids)
# 批量上传限制
batch_upload_limit = int(dify_config.BATCH_UPLOAD_LIMIT)
if count > batch_upload_limit:
raise ValueError(f"You have reached the batch upload limit of {batch_upload_limit}.")
# 检查是否超过订阅限制
if 0 < vector_space.limit <= vector_space.size:
raise ValueError("Your total number of documents plus the number of uploads have over the limit of "
"your subscription.")
except Exception as e:
# 如果有异常,更新所有相关文档的状态为错误,并记录异常信息
for document_id in document_ids:
document = db.session.query(Document).filter(
Document.id == document_id,
Document.dataset_id == dataset_id
).first()
if document:
document.indexing_status = 'error'
document.error = str(e)
document.stopped_at = datetime.datetime.now(datetime.timezone.utc).replace(tzinfo=None)
db.session.add(document)
db.session.commit()
return
# 更新文档状态为解析中,并添加到处理列表
for document_id in document_ids:
logging.info(click.style('Start process document: {}'.format(document_id), fg='green'))
document = db.session.query(Document).filter(
Document.id == document_id,
Document.dataset_id == dataset_id
).first()
if document:
document.indexing_status = 'parsing'
document.processing_started_at = datetime.datetime.now(datetime.timezone.utc).replace(tzinfo=None)
documents.append(document)
db.session.add(document)
db.session.commit()
#......2.IndexingRunner.run()中包含了RAG索引的实现细节
@shared_task(queue='dataset')
def document_indexing_task(dataset_id: str, document_ids: list):
"""
异步处理文档索引任务。
:param dataset_id:数据集ID
:param document_ids:需要处理的文档ID列表
Usage: document_indexing_task.delay(dataset_id, document_id)
主要功能:1.查询dataset的文章限制是否超出 入宫超出抛出异常,将所有document_ids状态改为 error 如果正常,则更新所有文章状态为 “解析中” parsing
2.IndexingRunner.run()中包含了RAG索引的实现细节
"""
#......
# 尝试运行索引处理
try:
# RAG索引的实现细节
indexing_runner = IndexingRunner()
indexing_runner.run(documents)
end_at = time.perf_counter()
logging.info(click.style('Processed dataset: {} latency: {}'.format(dataset_id, end_at - start_at), fg='green'))
except DocumentIsPausedException as ex:
# 如果文档被暂停,记录信息
logging.info(click.style(str(ex), fg='yellow'))
except Exception:
passIndexingRunner
代码目录:dify/api/core/indexing_runner.py
run() 该函数主要做了以下三件事
1.提取文本
2.转化数据切片
3.将切片后的文本 构造 document_segment 入库
4.索引中间件加载
def run(self, dataset_documents: list[DatasetDocument]):
"""Run the indexing process."""
"""
运行索引过程,对每个提供的数据集文档进行处理。
"""
for dataset_document in dataset_documents:
try:
# get dataset
dataset = Dataset.query.filter_by(
id=dataset_document.dataset_id
).first()
if not dataset:
raise ValueError("no dataset found")
# 获取处理规则
processing_rule = db.session.query(DatasetProcessRule). \
filter(DatasetProcessRule.id == dataset_document.dataset_process_rule_id). \
first()
index_type = dataset_document.doc_form # 文档的形式,用于确定索引处理器类型
index_processor = IndexProcessorFactory(index_type).init_index_processor() # 创建索引处理器实例
# 提取文本数据
text_docs = self._extract(index_processor, dataset_document, processing_rule.to_dict())
# print('提取文本数据', text_docs)
# 转换数据
documents = self._transform(index_processor, dataset, text_docs, dataset_document.doc_language,
processing_rule.to_dict())
# print('转换数据', documents)
# 保存片段 将最终切片后的 chunks 构造 document_segment 入库
self._load_segments(dataset, dataset_document, documents)
# load
self._load(
index_processor=index_processor,
dataset=dataset,
dataset_document=dataset_document,
documents=documents
)
except DocumentIsPausedException:
# 如果文档被暂停,抛出异常
raise DocumentIsPausedException('Document paused, document id: {}'.format(dataset_document.id))
except ProviderTokenNotInitError as e:
# 如果提供商令牌未初始化,更新文档状态并提交更改
dataset_document.indexing_status = 'error'
dataset_document.error = str(e.description)
dataset_document.stopped_at = datetime.datetime.now(datetime.timezone.utc).replace(tzinfo=None)
db.session.commit()
except ObjectDeletedError:
# 如果对象被删除,记录警告日志
logging.warning('Document deleted, document id: {}'.format(dataset_document.id))
except Exception as e: # 对于其他异常,记录异常信息并更新文档状态
logging.exception("consume document failed")
dataset_document.indexing_status = 'error'
dataset_document.error = str(e)
dataset_document.stopped_at = datetime.datetime.now(datetime.timezone.utc).replace(tzinfo=None)
db.session.commit()提取文本
text_docs = self._extract(index_processor, dataset_document, processing_rule.to_dict())
假如 index_processor根据用户所选为: ParagraphIndexProcessor类,则self._extract调用的实际为ParagraphIndexProcessor.extract
self._extract()
加载数据源,判断数据类型 根据数据类型匹配不同的提取设置,最终调用extract函数
def _extract(self, index_processor: BaseIndexProcessor, dataset_document: DatasetDocument, process_rule: dict) \
-> list[Document]:
"""
根据数据源类型提取文档内容。
:param index_processor: 索引处理器实例
:param dataset_document: 数据集文档对象
:param process_rule: 处理规则字典
:return: 包含提取后文档内容的列表
这段代码定义了一个名为_extract的方法,用于根据不同的数据源类型(上传文件、Notion导入、网站爬取)提取文档内容。
它首先检查数据源类型,然后根据类型创建相应的ExtractSetting对象,
并调用index_processor的extract方法来提取文档。
之后,它会更新文档的状态为“分割”,计算并更新文档的词数,以及完成解析的时间。
最后,它会更新提取的文档元数据中的文档ID和数据集ID,以关联到正确的数据集文档。
"""
# 加载文件,如果数据源类型不是上传文件、Notion导入或网站爬取,则返回空列表
if dataset_document.data_source_type not in ["upload_file", "notion_import", "website_crawl"]:
return []
data_source_info = dataset_document.data_source_info_dict
text_docs = [] # 初始化文本文档列表
# 处理上传文件数据源
if dataset_document.data_source_type == 'upload_file':
if not data_source_info or 'upload_file_id' not in data_source_info:
raise ValueError("no upload file found")
# 查询上传文件详情
file_detail = db.session.query(UploadFile). \
filter(UploadFile.id == data_source_info['upload_file_id']). \
one_or_none()
if file_detail:
# 创建提取设置
extract_setting = ExtractSetting(
datasource_type="upload_file",
upload_file=file_detail,
document_model=dataset_document.doc_form
)
# 使用索引处理器提取文档
text_docs = index_processor.extract(extract_setting, process_rule_mode=process_rule['mode'])
# 处理Notion导入数据源
elif dataset_document.data_source_type == 'notion_import':
if (not data_source_info or 'notion_workspace_id' not in data_source_info
or 'notion_page_id' not in data_source_info):
raise ValueError("no notion import info found")
# 创建提取设置
extract_setting = ExtractSetting(
datasource_type="notion_import",
notion_info={
"notion_workspace_id": data_source_info['notion_workspace_id'],
"notion_obj_id": data_source_info['notion_page_id'],
"notion_page_type": data_source_info['type'],
"document": dataset_document,
"tenant_id": dataset_document.tenant_id
},
document_model=dataset_document.doc_form
)
# 使用索引处理器提取文档
text_docs = index_processor.extract(extract_setting, process_rule_mode=process_rule['mode'])
# 处理网站爬取数据源
elif dataset_document.data_source_type == 'website_crawl':
if (not data_source_info or 'provider' not in data_source_info
or 'url' not in data_source_info or 'job_id' not in data_source_info):
raise ValueError("no website import info found")
# 创建提取设置
extract_setting = ExtractSetting(
datasource_type="website_crawl",
website_info={
"provider": data_source_info['provider'],
"job_id": data_source_info['job_id'],
"tenant_id": dataset_document.tenant_id,
"url": data_source_info['url'],
"mode": data_source_info['mode'],
"only_main_content": data_source_info['only_main_content']
},
document_model=dataset_document.doc_form
)
# 使用索引处理器提取文档
text_docs = index_processor.extract(extract_setting, process_rule_mode=process_rule['mode'])
# update document status to splitting
# 更新文档状态为“分割”阶段
self._update_document_index_status(
document_id=dataset_document.id,
after_indexing_status="splitting",
extra_update_params={
DatasetDocument.word_count: sum(len(text_doc.page_content) for text_doc in text_docs),
DatasetDocument.parsing_completed_at: datetime.datetime.now(datetime.timezone.utc).replace(tzinfo=None)
}
)
## 替换文档ID为数据集文档模型ID
text_docs = cast(list[Document], text_docs) # 类型断言,确保text_docs为Document列表
for text_doc in text_docs:
text_doc.metadata['document_id'] = dataset_document.id
text_doc.metadata['dataset_id'] = dataset_document.dataset_id
return text_docsParagraphIndexProcessor.extract()
代码目录:api/core/rag/index_processor/processor/paragraph_index_processor.py
实际进来调用的是ExtractProcessor这个类的extract。这个类具体编写了所有常见文本格式的提取器的具体实现
class ParagraphIndexProcessor(BaseIndexProcessor):
def extract(self, extract_setting: ExtractSetting, **kwargs) -> list[Document]:
text_docs = ExtractProcessor.extract(extract_setting=extract_setting,
is_automatic=kwargs.get('process_rule_mode') == "automatic")
return text_docsExtractProcessor.extract()
代码目录:api/core/rag/extractor/extract_processor.py
根据文件后缀名调用不同的文档解析器提取文档内容,根据不同的文本格式,调用不同的类,去处理文本,最终会返回提取的文本内容
def extract(cls, extract_setting: ExtractSetting, is_automatic: bool = False,
file_path: str = None) -> list[Document]:
if extract_setting.datasource_type == DatasourceType.FILE.value:
with tempfile.TemporaryDirectory() as temp_dir:
if not file_path:
upload_file: UploadFile = extract_setting.upload_file
suffix = Path(upload_file.key).suffix
file_path = f"{temp_dir}/{next(tempfile._get_candidate_names())}{suffix}"
storage.download(upload_file.key, file_path)
input_file = Path(file_path)
file_extension = input_file.suffix.lower()
etl_type = current_app.config['ETL_TYPE']
unstructured_api_url = current_app.config['UNSTRUCTURED_API_URL']
unstructured_api_key = current_app.config['UNSTRUCTURED_API_KEY']
if etl_type == 'Unstructured':
if file_extension == '.xlsx' or file_extension == '.xls':
extractor = ExcelExtractor(file_path)
elif file_extension == '.pdf':
extractor = PdfExtractor(file_path)
elif file_extension in ['.md', '.markdown']:
extractor = UnstructuredMarkdownExtractor(file_path, unstructured_api_url) if is_automatic \
else MarkdownExtractor(file_path, autodetect_encoding=True)
elif file_extension in ['.htm', '.html']:
extractor = HtmlExtractor(file_path)
elif file_extension in ['.docx']:
extractor = WordExtractor(file_path, upload_file.tenant_id, upload_file.created_by)
elif file_extension == '.csv':
extractor = CSVExtractor(file_path, autodetect_encoding=True)
elif file_extension == '.msg':
extractor = UnstructuredMsgExtractor(file_path, unstructured_api_url)
elif file_extension == '.eml':
extractor = UnstructuredEmailExtractor(file_path, unstructured_api_url)
elif file_extension == '.ppt':
extractor = UnstructuredPPTExtractor(file_path, unstructured_api_url, unstructured_api_key)
elif file_extension == '.pptx':
extractor = UnstructuredPPTXExtractor(file_path, unstructured_api_url)
elif file_extension == '.xml':
extractor = UnstructuredXmlExtractor(file_path, unstructured_api_url)
elif file_extension == 'epub':
extractor = UnstructuredEpubExtractor(file_path, unstructured_api_url)
else:
# txt
extractor = UnstructuredTextExtractor(file_path, unstructured_api_url) if is_automatic \
else TextExtractor(file_path, autodetect_encoding=True)
else:
if file_extension == '.xlsx' or file_extension == '.xls':
extractor = ExcelExtractor(file_path)
elif file_extension == '.pdf':
extractor = PdfExtractor(file_path)
elif file_extension in ['.md', '.markdown']:
extractor = MarkdownExtractor(file_path, autodetect_encoding=True)
elif file_extension in ['.htm', '.html']:
extractor = HtmlExtractor(file_path)
elif file_extension in ['.docx']:
extractor = WordExtractor(file_path, upload_file.tenant_id, upload_file.created_by)
elif file_extension == '.csv':
extractor = CSVExtractor(file_path, autodetect_encoding=True)
elif file_extension == 'epub':
extractor = UnstructuredEpubExtractor(file_path)
else:
# txt
extractor = TextExtractor(file_path, autodetect_encoding=True)
return extractor.extract()
elif extract_setting.datasource_type == DatasourceType.NOTION.value:
extractor = NotionExtractor(
notion_workspace_id=extract_setting.notion_info.notion_workspace_id,
notion_obj_id=extract_setting.notion_info.notion_obj_id,
notion_page_type=extract_setting.notion_info.notion_page_type,
document_model=extract_setting.notion_info.document,
tenant_id=extract_setting.notion_info.tenant_id,
)
return extractor.extract()
elif extract_setting.datasource_type == DatasourceType.WEBSITE.value:
if extract_setting.website_info.provider == 'firecrawl':
extractor = FirecrawlWebExtractor(
url=extract_setting.website_info.url,
job_id=extract_setting.website_info.job_id,
tenant_id=extract_setting.website_info.tenant_id,
mode=extract_setting.website_info.mode,
only_main_content=extract_setting.website_info.only_main_content
)
return extractor.extract()
else:
raise ValueError(f"Unsupported website provider: {extract_setting.website_info.provider}")
else:
raise ValueError(f"Unsupported datasource type: {extract_setting.datasource_type}")2.转化数据切片(和提取文本类似)最终会调用ParagraphIndexProcessor.transform
# 转换数据
documents = self._transform(index_processor, dataset, text_docs, dataset_document.doc_language,
processing_rule.to_dict())ParagraphIndexProcessor.transform()
代码目录:api/core/rag/index_processor/processor/paragraph_index_processor.py
将文本文档分割成节点,并对每个节点进行清理和元数据处理。
def transform(self, documents: list[Document], **kwargs) -> list[Document]:
"""
将文本文档分割成节点,并对每个节点进行清理和元数据处理。
:param documents: 待处理的文档列表
:param kwargs: 关键字参数,包括处理规则、嵌入模型实例等
:return: 处理后的文档节点列表
这段代码实现了将一系列文档分割成更小的节点,并对这些节点进行清理和元数据处理的功能。
它首先根据传入的处理规则和嵌入模型实例选择一个适当的文档分割器。
然后,遍历每个文档,先清理文档内容,再使用分割器将其分割成多个节点。
对于每个节点,它生成一个唯一的文档ID和内容的哈希值,更新节点的元数据,并清除可能存在的分割符。
最后,将处理后的文档节点添加到结果列表中并返回。
"""
# # 选择文档分割器
splitter = self._get_splitter(processing_rule=kwargs.get('process_rule'), # 处理规则
embedding_model_instance=kwargs.get('embedding_model_instance'))# 嵌入模型实例
all_documents = [] # 初始化所有文档节点列表
for document in documents: # 遍历每个文档
# 清理文档内容
document_text = CleanProcessor.clean(document.page_content, kwargs.get('process_rule'))
document.page_content = document_text # 更新文档内容
# # 将文档分割成节点
document_nodes = splitter.split_documents([document]) #为文档的切片具体实现
split_documents = [] # 初始化分割后的文档节点列表
for document_node in document_nodes: # 遍历每个文档节点
if document_node.page_content.strip(): # 如果节点内容非空
# 生成唯一文档ID和哈希值
doc_id = str(uuid.uuid4())
hash = helper.generate_text_hash(document_node.page_content)
# 更新文档节点元数据
document_node.metadata['doc_id'] = doc_id
document_node.metadata['doc_hash'] = hash
# # 清除分割符
page_content = document_node.page_content
if page_content.startswith(".") or page_content.startswith("。"):
page_content = page_content[1:].strip() # 去除开头的点或句号
else:
page_content = page_content
if len(page_content) > 0: # 如果处理后的内容长度大于0
document_node.page_content = page_content # 更新文档节点内容
split_documents.append(document_node) # 添加到分割文档列表
all_documents.extend(split_documents) # 将分割后的文档添加到总列表
return all_documents # 返回处理后的文档节点列表其中CleanProcessor.clean(document.page_content, kwargs.get('process_rule'))是做了文本清除
splitter.split_documents([document]) 是文档的切片具体实现目录:dify/api/core/splitter
对 text_splitter的分析:
TextSplitter
-
抽象方法
split_text:这个方法必须在子类中实现。 -
方法
create_documents、splits_documents、transfer_documents、_merge_splits:这些是TextSplitter类中的具体方法,可以在子类中调用或重写。
RecursiveCharacterTextSplitterSplitter
-
继承自
TextSplitter。 -
方法
split_text:这个方法重写了TextSplitter中的抽象方法split_text。
EnhanceRecursiveCharacterTextSplitterSplitter
-
继承自
RecursiveCharacterTextSplitterSplitter。 -
类方法
from_encoder:这是一个类方法,可以通过类本身而不是类的实例来调用。
splitter.split_documents([document])最终调用的是RecursiveCharacterTextSplitter._split_text
里面包含了_split_text_with_regex(text, separator, self._keep_separator)去分割字符串
self._merge_splits(_good_splits, _separator)合并短句
class RecursiveCharacterTextSplitter(TextSplitter):
#......
def _split_text(self, text: str, separators: list[str]) -> list[str]:
"""
将输入文本按照给定的分隔符分割成块,并递归地处理过长的文本块。
:param text: 待分割的原始文本
:param separators: 可选的分隔符列表,用于文本分割
:return: 分割后的文本块列表
此段代码实现了一个文本分割算法,主要逻辑如下:
从给定的分隔符列表中选择一个有效的分隔符,用于分割文本。
使用选定的分隔符将文本分割成多个部分。
遍历分割后的每一部分,如果部分的长度小于设定的块大小,将其标记为合适的短文本块;否则,如果还有其他分隔符可用,递归地继续分割这部分文本;如果没有其他分隔符,直接将这部分文本作为块添加到最终结果中。
在每次处理完一个长文本块后,将之前累积的短文本块合并,并添加到最终的文本块列表中。
最终返回分割后的所有文本块组成的列表。
"""
"""Split incoming text and return chunks."""
final_chunks = [] # 初始化最终的文本块列表
# 从separators中选取一个有效的分隔符
separator = separators[-1] # 默认使用最后一个分隔符
new_separators = [] # 初始化新的分隔符列表
for i, _s in enumerate(separators):
if _s == "": # 初始化新的分隔符列表
separator = _s
break
if re.search(_s, text):# 如果当前分隔符在文本中存在
separator = _s# 使用这个分隔符
new_separators = separators[i + 1:] # 更新新的分隔符列表
break
# 使用选定的分隔符分割文本
splits = _split_text_with_regex(text, separator, self._keep_separator)
# # 合并短文本块,递归分割长文本块
_good_splits = [] # 初始化合适的短文本块列表
_separator = "" if self._keep_separator else separator # 确定是否保留分隔符
for s in splits:
if self._length_function(s) < self._chunk_size: # 如果文本块长度小于设定的块大小
_good_splits.append(s) # 将其添加到合适的短文本块列表
else:
if _good_splits: # 如果有合适的短文本块
merged_text = self._merge_splits(_good_splits, _separator) # 合并它们
final_chunks.extend(merged_text) # 将合并后的文本块添加到最终的文本块列表
_good_splits = [] # 清空短文本块列表
# 如果没有新的分隔符,直接将当前过长的文本块添加到最终列表
if not new_separators:
final_chunks.append(s)
else:
# 如果有新的分隔符,递归地分割当前过长的文本块
other_info = self._split_text(s, new_separators)
final_chunks.extend(other_info) # 将递归分割的结果添加到最终列表
# 最后处理剩余的合适短文本块
if _good_splits:
merged_text = self._merge_splits(_good_splits, _separator)
final_chunks.extend(merged_text)
return final_chunks3.存储片段
保存片段 将最终切片后的 chunks 构造 document_segment 入库
self._load_segments(dataset, dataset_document, documents)代码目录:api/core/indexing_runner.py
def _load_segments(self, dataset, dataset_document, documents):
# 创建一个DatasetDocumentStore实例,用于存储文档片段
doc_store = DatasetDocumentStore(
dataset=dataset,
user_id=dataset_document.created_by,
document_id=dataset_document.id
)
# 将文档片段添加到文档存储中
doc_store.add_documents(documents)
# 获取当前时间,用于记录文档处理的完成时间
cur_time = datetime.datetime.now(datetime.timezone.utc).replace(tzinfo=None)
# 更新文档的状态至“索引中”,并记录文档的清洗和分割完成时间
self._update_document_index_status(
document_id=dataset_document.id,
after_indexing_status="indexing",
extra_update_params={
DatasetDocument.cleaning_completed_at: cur_time,
DatasetDocument.splitting_completed_at: cur_time,
}
)
## 更新文档片段的状态至“索引中”,并记录片段的索引开始时间
self._update_segments_by_document(
dataset_document_id=dataset_document.id,
update_params={
DocumentSegment.status: "indexing",
DocumentSegment.indexing_at: datetime.datetime.now(datetime.timezone.utc).replace(tzinfo=None)
}
)
pass4.索引中间件加载
self._load(
index_processor=index_processor,
dataset=dataset,
dataset_document=dataset_document,
documents=documents
)def _load(self, index_processor: BaseIndexProcessor, dataset: Dataset,
dataset_document: DatasetDocument, documents: list[Document]) -> None:
"""
插入索引并更新文档/片段状态至已完成。
"""
# 如果索引技术设置为'high_quality',则获取相应的嵌入模型实例
embedding_model_instance = None
if dataset.indexing_technique == 'high_quality':
embedding_model_instance = self.model_manager.get_model_instance(
tenant_id=dataset.tenant_id,
provider=dataset.embedding_model_provider,
model_type=ModelType.TEXT_EMBEDDING,
model=dataset.embedding_model
)
# 记录索引开始时间
indexing_start_at = time.perf_counter()
# 初始化计数器,用于统计处理的token数量
tokens = 0
# 设置每次处理的文档块大小
chunk_size = 10
# 创建关键词索引的线程
create_keyword_thread = threading.Thread(target=self._process_keyword_index,
args=(current_app._get_current_object(),
dataset.id, dataset_document.id, documents))
create_keyword_thread.start() # 启动线程
# 如果索引技术为'high_quality',则并行处理文档块
if dataset.indexing_technique == 'high_quality':
with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:
futures = [] # 存储Future对象的列表
# 将文档列表分割成多个块
for i in range(0, len(documents), chunk_size):
chunk_documents = documents[i:i + chunk_size]
# 提交任务到线程池
futures.append(
executor.submit(self._process_chunk, current_app._get_current_object(), index_processor,
chunk_documents, dataset,
dataset_document, embedding_model_instance))
# 收集并处理所有Future的结果
for future in futures:
tokens += future.result() # 累加处理的token数量
# 等待关键词索引线程完成
create_keyword_thread.join()
# 记录索引结束时间
indexing_end_at = time.perf_counter()
# 更新文档状态至已完成
self._update_document_index_status(
document_id=dataset_document.id, # 文档ID
after_indexing_status="completed", # 更新后的状态
extra_update_params={ # 额外更新参数
DatasetDocument.tokens: tokens, # 处理的token总数
DatasetDocument.completed_at: datetime.datetime.now(datetime.timezone.utc).replace(tzinfo=None), # 完成时间
DatasetDocument.indexing_latency: indexing_end_at - indexing_start_at, # 索引延迟时间
}
)