AI开发:用模型来识别手写数字的完整教程含源码 - Python 机器学习
今天一起来学习scikit-learn 。
scikit-learn 是一个强大的 Python 机器学习库,提供多种分类、回归、聚类算法,适用于从数据预处理到模型评估的全流程。它支持简单一致的 API,适合快速构建和测试模型。
官方地址在这里,记得Mark 很有用: https://scikit-learn.org/dev/index.html
scikit-learn 在手写数字识别方面具有以下特点:
- 提供内置的手写数字数据集(digits),包含 1797 个 8×8 像素的灰度数字图像。
- 支持多种分类算法(如 SVM、决策树、kNN 等),便于快速模型选择和评估。
- 内置工具可进行特征提取、数据预处理和模型训练,简化流程。
- 提供易用接口,适合初学者学习和研究机器学习算法在数字识别中的应用。
几天我们要使用这个库来识别一张图片中的手写数字,基本的业务逻辑如下图:
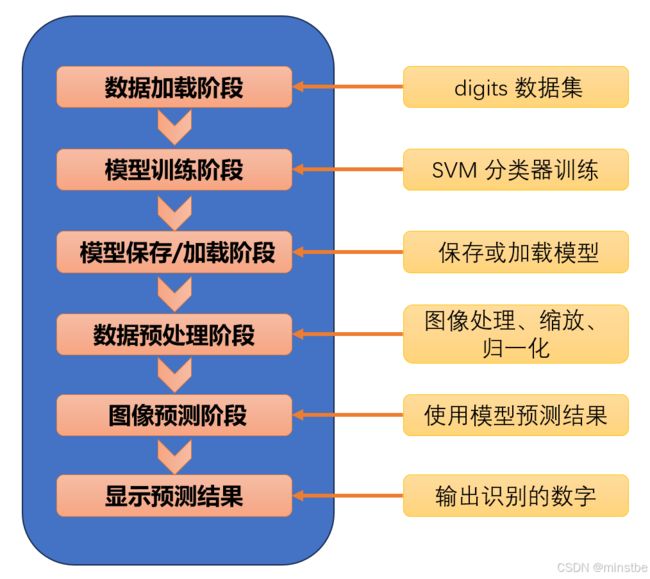
这里要讲一下,AI开发应用,不需要熟知底层的模型基础技术和知识,只需要掌握库和模型的应用。我们先来看一下第一步数据加载
No. 1 加载数据:
这里定义了一个函数 load_dataset ,作用是加载和返回一个内置的手写数字数据集,供后续的机器学习模型训练和测试使用。
# 模块1: 数据加载和预处理
def load_dataset():
"""加载数字数据集"""
digits = datasets.load_digits()
return digits.data, digits.target详细解释
-
数据集来源:
- 使用的是
scikit-learn的内置数据集datasets.load_digits()。 - 这是一个用于手写数字识别的经典数据集,包含 0 到 9 的手写数字样本。
- 使用的是
-
数据集内容:
- 数据集包含 64维特征(每个数字图像为 8×8 像素,像素值被展平为一维数组)。
- 标签是对应数字的值(例如,0, 1, 2...9)。
-
返回值:
digits.data: 2D 数组,表示数据集中的所有特征(每行是一个样本,每列是一个特征)。digits.target: 一维数组,表示每个样本对应的真实标签。
-
函数的作用:
- 加载数据集,直接返回特征数据和目标标签,便于分割数据集或传递给模型训练函数。
举例输出
调用 load_dataset 的代码:
X, y = load_dataset()
print("特征数据 X 的形状:", X.shape)
print("标签数据 y 的形状:", y.shape)
print("第一个样本的特征:\n", X[0])
print("第一个样本的标签:", y[0])
输出示例:
特征数据 X 的形状: (1797, 64)
标签数据 y 的形状: (1797,)
第一个样本的特征:
[ 0. 0. 5. 13. 9. 1. 0. 0. 0. 0. 13. 15. 10. 15. 5. 0.
...
第一个样本的标签: 0
函数小结
该函数的作用是简化数据加载过程,使主程序能够直接获得数字数据的特征和标签,而无需每次重新处理数据集。
No. 2 模型训练:
# 模块3: 模型训练与保存
def train_model(model_path, x_train, y_train):
"""训练支持向量机分类器并保存"""
classifier = svm.SVC(gamma=0.001)
start = time.perf_counter()
classifier.fit(x_train, y_train)
print(f"训练完成, 耗时: {time.perf_counter() - start:.4f} 秒")
with open(model_path, 'wb') as f:
pickle.dump(classifier, f)
print(f"模型已保存到 {model_path}")函数模块作用:模型训练与保存
该函数 train_model 的主要作用是训练一个支持向量机(SVM)分类器,并将训练好的模型保存到指定路径,以便后续直接加载使用,而无需重复训练。
分类器指的是一个用来做“分类”任务的数学模型。通俗来说,它就像一个“判断器”或者“识别器”,它根据输入的数据,给出一个分类结果。
假设你有一堆手写数字的图片,每张图片上的数字可能是 0 到 9 之间的任何一个。分类器就是通过学习这些数字的特征(比如笔画的粗细、弯曲程度等),来判断每张图片上是什么数字。它的工作流程就像是:
- 学习:给分类器一些带标签的数字图片(比如手写的“3”标记为数字3,“7”标记为数字7)。
- 识别:在训练完之后,给分类器一个新的数字图片,分类器会根据它之前学到的知识,判断这张图片上的数字是几。
在代码中,这个分类器是通过 svm.SVC 创建的,这个算法使用“支持向量机”(SVM)来分类数据。它会根据训练数据中的数字图片特征,训练出一个模型,然后用这个模型来对新的、未见过的图片进行分类预测。
详细功能分解
-
训练分类器:
- 使用
sklearn.svm.SVC创建支持向量机分类器,并设置gamma=0.001。
在支持向量机(SVM)中,gamma是一个超参数,用于控制高斯径向基函数(RBF)核函数的影响范围。它的值决定了模型在决策边界上的灵活性和复杂度。-
较小的 gamma 值(例如
gamma=0.001):
使得每个数据点对决策边界的影响范围更广,意味着模型的决策边界更加平滑和简单,可能导致欠拟合(underfitting)。 -
较大的 gamma 值:
会使每个数据点的影响范围变小,决策边界更加复杂,容易过拟合(overfitting)训练数据。
gamma=0.001 的作用:当
gamma=0.001时,模型倾向于生成较为平滑的决策边界,对数据点的变化不那么敏感。这可能有助于避免过拟合,但如果数据中存在复杂的决策边界,可能导致模型无法很好地拟合数据(欠拟合)。因此,gamma的选择需要通过交叉验证等方法来调优,以获得最佳的模型性能。
-
- 调用
fit(x_train, y_train)方法,用训练数据x_train和标签y_train对分类器进行训练。
- 使用
-
计算训练时间:
- 通过
time.perf_counter()记录训练开始和结束时间,计算并输出训练耗时,方便了解模型训练效率。
- 通过
-
保存模型:
- 使用
pickle.dump将训练好的分类器对象序列化,保存到文件中(路径由model_path指定)。 - 保存后的模型文件可直接加载进行预测,无需每次运行程序时重新训练。
- 使用
-
输出训练与保存状态:
- 打印训练完成的耗时和模型保存路径,便于用户确认训练和保存是否成功。
模块作用小结
- 主要目标: 完成模型的训练与保存工作。
- 适用场景: 在数字识别等任务中,训练模型通常是一次性操作,通过保存模型文件,可以将训练阶段与预测阶段分离,提高系统运行效率。
- 模块化好处: 提高代码复用性和可读性,用户可以更方便地替换训练数据或模型参数。
No.3 加载模型:
def load_model(model_path):
"""加载保存的模型"""
if not os.path.exists(model_path):
raise FileNotFoundError(f"模型文件 {model_path} 不存在!请先训练模型。")
with open(model_path, 'rb') as f:
classifier = pickle.load(f)
print(f"模型已从 {model_path} 加载")
return classifier上面这个模块就不多解释了 ,就是看模型(分类器)是否存在,不存在 就训练一个保存。
No.4 加载图像并预处理:
好,现在开始加载我们的图像了,这里我准备的是一张100*100 的png图像,里面手写了一个2,需要注意的是 scikit-learn 自带共 1797条数据(图片),每条数据由64个特征点组成(8*8像素)

def preprocess_image(image_path):
"""读取并预处理图像"""
source = cv2.imread(image_path)
if source is None:
raise FileNotFoundError(f"文件 {image_path} 未找到或无法读取!")
gray = cv2.cvtColor(source, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (5, 5), 0)
_, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY_INV)
feature = cv2.resize(binary, (8, 8)).astype(float) / 16
plt.imshow(feature, cmap='gray')
plt.title("预处理后的图像")
plt.show()
return feature.flatten()函数作用:图像预处理
该函数 preprocess_image 的作用是从指定路径读取一张图像并进行一系列预处理操作,最终输出处理后的图像特征(以便用于机器学习模型的输入)。
这个函数会停在 显示一张图片,就是把我们前面的原始图进行了一些灰度处理,并描绘了一个轮廓,模型将参照这张处理后的图片标识去比对确认最终的数字
详细步骤:
-
读取图像:
使用cv2.imread(image_path)从指定路径image_path读取图像文件。如果文件不存在或无法读取,会抛出FileNotFoundError异常。 -
转换为灰度图:
cv2.cvtColor(source, cv2.COLOR_BGR2GRAY)将读取的彩色图像转换为灰度图。这样可以简化图像处理,因为灰度图只有亮度信息,没有颜色信息。 -
高斯模糊:
cv2.GaussianBlur(gray, (5, 5), 0)对灰度图像应用高斯模糊。模糊操作有助于去除图像中的噪声,使后续的二值化更加平滑和稳定。 -
二值化:
cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY_INV)将灰度图像进行二值化操作。具体来说,图像中像素值大于 127 的部分变为 0(黑色),小于或等于 127 的部分变为 255(白色)。使用THRESH_BINARY_INV使得背景为白色,前景为黑色。 -
调整图像大小:
cv2.resize(binary, (8, 8))将二值化后的图像调整为 8x8 的大小。这一步是为了将图像转换为固定大小的特征,使得每个图像都能统一输入到机器学习模型中。 -
缩放特征值:
.astype(float) / 16将图像数据类型转换为float类型,并将其值缩放到一个较小的范围(0 到 15),以便适应模型的输入需求。 -
显示预处理结果:
plt.imshow(feature, cmap='gray')显示预处理后的图像,并使用plt.title("预处理后的图像")给图像加上标题。 -
返回特征:
feature.flatten()将 8x8 的图像矩阵展平为一维数组(64个元素),作为模型的输入特征返回。
函数小结:
preprocess_image 函数的作用是读取图像并通过灰度转换、模糊处理、二值化和尺寸调整等一系列步骤,将图像转化为适合机器学习模型处理的特征向量。最终,输出一个展平的图像特征向量,以便进一步的分类或其他处理。
需要注意的是,这里面的参数是可调节的,有时候需要根据实际情况多次调试参数,以使得模型的识别更加准确。
No.5 图像预测:
def predict(classifier, x_test):
"""使用分类器预测测试样本"""
start = time.perf_counter()
predictions = classifier.predict(x_test)
print(f"预测完成, 耗时: {time.perf_counter() - start:.4f} 秒")
return predictions函数作用:使用分类器进行预测
该函数 predict 的作用是使用已经训练好的分类器对测试数据 x_test 进行预测,并返回预测结果。
详细步骤:
-
记录开始时间:
start = time.perf_counter()记录开始预测的时间。time.perf_counter()返回一个高精度的时间戳,用于计算函数执行的时间。 -
进行预测:
predictions = classifier.predict(x_test)使用输入的classifier(即训练好的分类器)对x_test进行预测。x_test是待分类的测试样本,classifier.predict()方法会返回对每个测试样本的预测结果(例如,分类标签或类别)。 -
计算并打印耗时:
print(f"预测完成, 耗时: {time.perf_counter() - start:.4f} 秒")计算从开始到完成预测的时间差,并以秒为单位打印出来。time.perf_counter() - start得到的时间差值就是执行预测操作所花费的时间。 -
返回预测结果:
return predictions返回预测的结果。预测结果通常是一个数组或列表,其中包含对每个测试样本的预测分类标签。
函数小结:
predict 函数的作用是:给定一个训练好的分类器和一组待分类的测试数据,利用分类器对数据进行预测,并返回预测结果。同时,它会打印预测操作所花费的时间。
No.5 结果显示:
![]()
完整的代码如下:
import os
import time
import pickle
import cv2
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn import svm
# 模块1: 数据加载和预处理
def load_dataset():
"""加载数字数据集"""
digits = datasets.load_digits()
return digits.data, digits.target
# 模块2: 图像处理
def preprocess_image(image_path):
"""读取并预处理图像"""
source = cv2.imread(image_path)
if source is None:
raise FileNotFoundError(f"文件 {image_path} 未找到或无法读取!")
gray = cv2.cvtColor(source, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (5, 5), 0)
_, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY_INV)
feature = cv2.resize(binary, (8, 8)).astype(float) / 16
plt.imshow(feature, cmap='gray')
plt.title("预处理后的图像")
plt.show()
return feature.flatten()
# 模块3: 模型训练与保存
def train_model(model_path, x_train, y_train):
"""训练支持向量机分类器并保存"""
classifier = svm.SVC(gamma=0.001)
start = time.perf_counter()
classifier.fit(x_train, y_train)
print(f"训练完成, 耗时: {time.perf_counter() - start:.4f} 秒")
with open(model_path, 'wb') as f:
pickle.dump(classifier, f)
print(f"模型已保存到 {model_path}")
# 模块4: 加载模型并预测
def load_model(model_path):
"""加载保存的模型"""
if not os.path.exists(model_path):
raise FileNotFoundError(f"模型文件 {model_path} 不存在!请先训练模型。")
with open(model_path, 'rb') as f:
classifier = pickle.load(f)
print(f"模型已从 {model_path} 加载")
return classifier
def predict(classifier, x_test):
"""使用分类器预测测试样本"""
start = time.perf_counter()
predictions = classifier.predict(x_test)
print(f"预测完成, 耗时: {time.perf_counter() - start:.4f} 秒")
return predictions
# 主函数: 流程控制
def main():
# 数据加载与分割
X, y = load_dataset()
X_train, X_test, Y_train, Y_test = train_test_split(X, y, test_size=0.1, random_state=42)
model_path = "hand_write_classer.cfr"
# 检查模型是否已存在
if os.path.exists(model_path):
classifier = load_model(model_path)
else:
print("未找到模型文件,开始训练新模型...")
train_model(model_path, X_train, Y_train)
classifier = load_model(model_path)
# 图像处理与预测
test_image_path = "num.png"
feature_vector = preprocess_image(test_image_path)
prediction = predict(classifier, [feature_vector])
print(f"识别结果: {prediction}")
if __name__ == "__main__":
main()
这里的图像自己准备吧,用画图工具,画布尺寸100*100 ,再手写数字。
好了,今天的学习就到此结束啦!