在python中使用opensmile的两种方式
一、安装opensmile的python库
1.1 安装
pip install opensmile1.2 使用
import opensmile
smile = opensmile.Smile(
feature_set=opensmile.FeatureSet.eGeMAPSv02, # egemaps特征集
feature_level=opensmile.FeatureLevel.Functionals # 功能级特征
)
audio_file = " " # 需要处理的语音文件的地址
save_csv = " " # 存储特征的csv的地址
features = smile.process_file(audio_path)
features.to_csv(save_csv)输出的features为dataframe数据类型 ,每一列是该特征集中的一个特征。输出的特征可以存入csv文件供后续使用
1.3 优劣
优点:安装和使用方便,无需配置复杂的config文件;能够方便地批量处理多条语音数据
缺点:只有部分特征集可以使用,诸如IS09-13就无法通过这种方式提取,具体见opensmile · PyPI
二、安装opensmile软件本体,编写python代码调用命令行实现批量特征提取(以windows11为例)
2.1 安装
从opensmile的github页面选择和自己系统适配的安装包下载并安装Release openSMILE 3.0 · audeering/opensmile
2.2 使用
因为opensmile软件本体会对输入的每条音频生成一个特征的csv,如果是一个数据库中的几千条数据都生成一个csv,那么既不方便保存,也不方便使用,所以我们希望能通过修改配置文件并撰写合适的python代码来实现批量处理音频,并将全部特征保存到一个csv当中。
2.2.1 修改配置文件
opensmile默认输出为arff类型的,需要修改配置文件使得特征输出是一个csv文件
首先找到需要使用的特征集的配置文件(以is09为例),文件位于安装目录下".\opensmile-3.0-win-x64\config\is09-13\IS09_emotion.conf"
分别在下面两处添加如下代码:
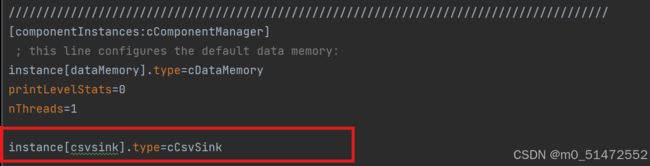
这句话的作用是实例化一个csvsink,也就是告知程序输出csv格式的特征
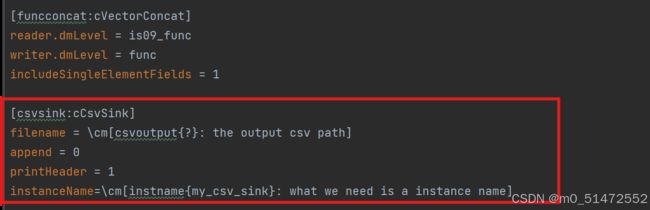
这段代码的作用是配置程序输出csv的格式,\cm代表动态输入,也就是输入内容从命令行中读取。
- append:对于指定输出的csv中已经有内容的情况,设定为0代表用新的内容覆盖旧的内容,最终的csv中只有新的内容;设定为1代表保留旧的内容,将新的内容添加到后面
- printheader:设定为1代表输出的特征带有特征名,设定为0代表不带特征名(也就是纯数字)
- instanceName:会显示在生成的csv的第一列
其他参数的配置,见“.\opensmile-3.0-win-x64\config\shared\standard_data_output.conf.inc"中的[csvsink:cCsvSink]部分
2.2.2 用python控制命令行执行程序
批量提取音频文件特征并存储到一个csv中的思路:用一个temp_csv来接收opensmile每次处理完生成的音频特征,然后读取这个csv,并将其中的内容附加到final_csv的末尾。
import subprocess
import pandas as pd
for idx, audio_path in enumerate(audio_path_list, 1):
print(f'Processing ({idx}/{len(audio_path_list)})...')
# 调用 OpenSMILE 提取特征,直接覆盖 temp_csv
command = [
opensmile_path,
"-C", is09_config_path,
"-I", audio_path,
"-csvoutput", temp_csv,
"-appendcsv", "0",
"-headercsv", "1",
"-timestampcsv", "0"
]
# 调用 OpenSMILE
subprocess.run(command, check=True)
# 读取临时 CSV 文件
features_df = pd.read_csv(temp_csv, sep=';')
features_df["label"] = emo_label
# 合并特征到最终 CSV 文件
if not os.path.exists(final_csv):
features_df.to_csv(final_csv, index=False, header=True) # 第一次写入,包含列名
else:
features_df.to_csv(final_csv, mode="a", index=False, header=False) # 追加写入
print(f"Feature extraction complete. Results saved to {final_csv}")audio_path_list是一个列表,存放需要处理的音频的路径
在command中:
opensmile_path:是你电脑上存放opensmile可执行文件的地址,位于安装目录下的".\opensmile-3.0-win-x64\bin\SMILExtract.exe"
"-C", is09_config_path:是所需要的特征集的配置,位于安装目录下的".\opensmile-3.0-win-x64\config\is09-13\IS09_emotion.conf" 这个参数可以替换为其他的特征集,opensmile支持的特征集可在安装目录下的config文件夹中查看
temp_csv:存放opensmile临时输出的单个音频的特征
final_csv:存放全部音频的特征
需要注意:虽说配置opensmile输出csv文件,但是最终存储在csv文件中的分隔符用的是分号";",所以在每次读取这个opensmile生成的csv也就是temp_csv时,需要指定分隔符。
最终得到的csv长这样:

要注意:第一列是配置的instancename,读取特征的时候需要略过这一列