Python多进程、线程技术
在 Python 中,multiprocessing.Process 是用于创建和管理多进程的类,提供了将任务分配给多个进程并行执行的功能。多进程可以有效利用多核 CPU 来加速计算密集型任务,因为 Python 中的 全局解释器锁 (GIL) 会限制单进程并行执行多线程任务,但多进程能够避开这个限制。
而Python 的多线程技术允许程序在多个线程之间并行执行任务,从而在某些场景下提升程序的执行效率。Python 的多线程模块主要通过 threading 库来实现。
1. 多进程技术(multiprocessing.Process)
multiprocessing.Process类可以通过target 和 args 参数来指定要执行的函数和传递给它的参数。每个进程都有独立的内存空间,它们之间的数据需要通过 进程间通信 (IPC) 来共享。注意这里的意思是我们无法通过直接传参或全局参数实现进程间数据交互,而线程间则是可以的。下面将分别介绍multiprocessing.Process用法。
1.1 创建和启动进程
from multiprocessing import Process
import os
def worker():
print(f"Worker process id: {os.getpid()}")
if __name__ == "__main__":
# 创建一个新的进程,target 指定要执行的函数
p = Process(target=worker)
# 启动进程
p.start()
# 等待进程结束
p.join()
print(f"Main process id: {os.getpid()}")
- Process(target=worker):创建一个进程对象,target 指定要执行的函数。
- p.start():启动新进程,开始执行 worker() 函数。
- p.join():主进程等待子进程结束,如果没有调用 join,主进程可能会先退出,而导致子进程无法完成。
1.2 传递参数给进程
from multiprocessing import Process
def worker(num):
print(f"Worker {num} is working")
if __name__ == "__main__":
processes = []
for i in range(5):
p = Process(target=worker, args=(i,))
processes.append(p)
p.start()
for p in processes:
p.join()
- args=(i,):args 是一个元组,用来传递参数给目标函数。如果目标函数有多个参数,则需要传递一个多元素的元组。
1.3 进程间通信
multiprocessing 提供了几种进程间通信的方式:如 Queue、Pipe 和 Value、Array 等。
使用 Queue 进行进程间通信
from multiprocessing import Process, Queue
def worker(q):
q.put('Hello from worker')
if __name__ == "__main__":
queue = Queue()
# 创建多个进程
processes = [Process(target=worker, args=(queue,)) for _ in range(3)]
for p in processes:
p.start()
for p in processes:
p.join()
# 从队列中获取数据
while not queue.empty():
print(queue.get())
- Queue.put():将数据放入队列中,供其他进程获取。
- Queue.get():从队列中取出数据。
使用 Pipe 进行进程间通信
from multiprocessing import Process, Pipe
def worker(conn):
conn.send("Hello from worker")
conn.close()
if __name__ == "__main__":
parent_conn, child_conn = Pipe()
p = Process(target=worker, args=(child_conn,))
p.start()
print(parent_conn.recv()) # 接收子进程发送的消息
p.join()
- Pipe 是一种双向通信机制,可以在父进程和子进程之间传输数据。
- conn.send() 和 conn.recv() 分别用于发送和接收数据。
注意这里parent_conn和child_conn是一对连接对象,可以理解成一个管道的两个接口,平时是只能从child_conn发送数据parent_conn接收数据,如果反过来就会爆如下错误:
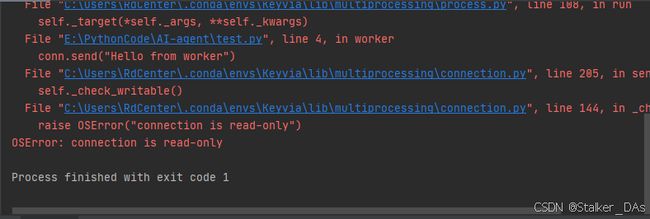
那如何通过一个Pipe实现双向通信机制呢?可以将Pipe的参数duplex设置为True,例子如下:
from multiprocessing import Process, Pipe
def send_data(conn):
# 向管道发送数据
conn.send("Hello from the sender!")
response = conn.recv() # 接收来自接收者的响应
print(f"Sender received: {response}")
def receive_data(conn):
message = conn.recv() # 接收来自发送者的数据
print(f"Receiver received: {message}")
conn.send("Hello from the receiver!") # 向发送者发送响应
if __name__ == "__main__":
# 创建双向管道
parent_conn, child_conn = Pipe(duplex=True)
# 创建并启动进程
p1 = Process(target=send_data, args=(parent_conn,))
p2 = Process(target=receive_data, args=(child_conn,))
p1.start()
p2.start()
p1.join()
p2.join()
-
Pipe(duplex=True) 创建一个双向管道,返回两个连接端点:parent_conn 和 child_conn。parent_conn 和 child_conn 可以互相发送和接收数据。
-
在 send_data 函数中,conn.send() 用于向管道发送数据,conn.recv() 用于接收来自另一进程的数据。
-
在 receive_data 函数中,conn.recv() 用于接收数据,conn.send() 用于发送响应回去。
-
通过 start() 启动两个进程,join() 用于等待进程结束。
注意:如果你使用 recv() 方法接收数据时,没有数据发送到管道中,recv() 会一直处于 阻塞 状态,直到接收到数据为止。所以这里的操作要小心造成死锁。
from multiprocessing import Process, Pipe
import time
def send_data(conn):
print("Sender waiting to send data...")
time.sleep(3) # 模拟发送数据的延迟
conn.send("Hello from sender!")
print("Sender sent data.")
def receive_data(conn):
print("Receiver waiting for data...")
message = conn.recv() # 会在这里阻塞,直到收到数据
print(f"Receiver received: {message}")
if __name__ == "__main__":
parent_conn, child_conn = Pipe()
p1 = Process(target=send_data, args=(parent_conn,))
p2 = Process(target=receive_data, args=(child_conn,))
p1.start()
p2.start()
p1.join()
p2.join()
Receiver waiting for data...
Sender waiting to send data...
Sender sent data.
Receiver received: Hello from sender!
在这个例子中,receiver 会在调用 recv() 时阻塞,直到 sender 通过管道发送数据。在 sender 发送数据之前,receiver 会一直阻塞在 recv() 这一行。time.sleep(3) 用于模拟 sender 发送数据的延迟。在这 3 秒内,receiver 会等待数据。
但这里有一个弊端,如果两个进程 同时发送 或 同时接收 数据,可能会发生竞争条件或者数据丢失的情况。
管道的设计是按顺序传输数据的,因此如果两个进程同时操作管道的读写端,可能导致:
- 同时发送数据:如果两个进程同时尝试通过管道的写端 send() 数据,管道中的数据流将会是不可预测的,可能出现数据错乱或丢失。管道无法保证顺序和完整性,尤其是在并发环境下。
- 同时接收数据:如果两个进程同时尝试从管道的读端 recv() 数据,它们都会阻塞等待数据。这可能导致一个进程先接收到数据,而另一个进程什么也没有接收到。或者,在某些实现中,管道可能会以竞争的方式返回数据,可能发生数据竞争。
所以其中一个方法就是使用两个管道,一个用于写,一个用于读,那么你将管道的读写操作分开到不同的端。这里就类似于C++中的管道。
代码结构如下:
from multiprocessing import Process, Pipe
def sender(write_conn):
write_conn.send("Message from sender")
print("Sender sent data.")
def receiver(read_conn):
data = read_conn.recv()
print(f"Receiver got: {data}")
if __name__ == '__main__':
# 创建两个管道
parent_conn1, child_conn1 = Pipe() # 用于发送数据
parent_conn2, child_conn2 = Pipe() # 用于接收数据
# 启动发送进程
sender_process = Process(target=sender, args=(child_conn1,))
receiver_process = Process(target=receiver, args=(parent_conn2,))
sender_process.start()
receiver_process.start()
# 发送数据到第二个管道
parent_conn1.send("Message through the first pipe")
# 从第一个管道接收
msg = child_conn2.recv()
sender_process.join()
receiver_process.join()
1.4 共享内存
multiprocessing 还提供了 Value 和 Array 等对象,用于在进程间共享数据。它们支持数据的共享和修改,不需要使用队列或者管道。
from multiprocessing import Process, Value
def worker(num):
num.value = 10 # 修改共享数据
if __name__ == "__main__":
num = Value('i', 0) # 创建一个整数共享变量
p = Process(target=worker, args=(num,))
p.start()
p.join()
print(num.value) # 输出修改后的共享数据
- Value('i', 0) 创建一个整数类型的共享内存对象,'i' 是类型代码,表示整数类型。
- 修改共享数据后,可以在主进程中读取修改后的值。
注意这些共享内存中的值并没有自动加锁机制,因此在并发访问时可能存在竞争条件,因此要用到下面介绍的Manager和第二节提到的加锁机制:
from multiprocessing import Process, Value, Lock
import time
def increment(shared_value, lock):
with lock: # 确保只有一个进程能访问
current_value = shared_value.value
time.sleep(0.1) # 模拟长时间操作
shared_value.value = current_value + 1
def main():
# 创建共享的Value对象
shared_value = Value('i', 0) # 初始化为0(整数类型)
# 创建一个Lock对象
lock = Lock()
# 启动多个进程
processes = [Process(target=increment, args=(shared_value, lock)) for _ in range(5)]
for p in processes:
p.start()
for p in processes:
p.join()
print(f"Final shared value: {shared_value.value}")
if __name__ == "__main__":
main()
比如这个例子,没有加锁的情况下输出的结果为:Final shared value: 1,但在加锁后为:Final shared value: 5。
1.5 Manager
下面介绍在多进程中常用的另一个功能Manager。multiprocessing.Manager() 是 multiprocessing 模块提供的一个管理器,它允许在不同进程之间共享对象。通过 Manager() 创建的对象在进程间是共享的,因此可以用于进程间通信和数据共享。
1.5.1 Manager功能
Manager 提供了一种方便的方式,使得多个进程可以访问共享数据结构,而不需要自己手动处理锁或其他同步机制。它的工作原理是:通过代理对象(proxy objects)在不同进程间共享数据,这些代理对象会处理底层的数据同步。
1.5.2 Manager支持的数据类型
通过 multiprocessing.Manager() 创建的对象可以有以下几种类型:
- List:一个可以在多个进程间共享的列表。
- Dict:一个可以在多个进程间共享的字典。
- Namespace:类似于一个普通的对象,可以将多个属性存储在一个对象中,并且可以在多个进程之间共享这些属性。
- Value 和 Array:虽然 Value 和 Array 对象也可以共享,但它们是低级别的共享数据类型,Manager 提供了更高级别的共享对象。
1.5.3 Manager的使用
- 创建 Manager 实例:通过 multiprocessing.Manager() 创建一个管理器。
- 创建共享对象:使用管理器来创建共享对象,如共享列表、字典等。
- 使用进程进行通信:多个进程可以通过 Manager 管理的对象进行通信,读写数据。
使用Manager创建共享字典
from multiprocessing import Process, Manager
def add_to_dict(shared_dict, key, value):
shared_dict[key] = value
def main():
# 创建 Manager 实例
with Manager() as manager:
# 创建一个共享字典
shared_dict = manager.dict()
# 创建多个进程修改共享字典
processes = []
for i in range(5):
p = Process(target=add_to_dict, args=(shared_dict, f'key{i}', i))
processes.append(p)
p.start()
for p in processes:
p.join()
# 输出最终的共享字典内容
print(shared_dict)
if __name__ == "__main__":
main()
- manager.dict() 创建了一个共享字典,可以在多个进程间共享数据。
- 每个进程通过 add_to_dict 函数将不同的键值对写入共享字典。
- 在 main 函数中,多个进程并发执行,最终将所有的数据存储在 shared_dict 中。
使用 Manager 创建共享列表
from multiprocessing import Process, Manager
def append_to_list(shared_list, value):
shared_list.append(value)
def main():
# 创建 Manager 实例
with Manager() as manager:
# 创建一个共享列表
shared_list = manager.list()
# 创建多个进程向共享列表中添加元素
processes = []
for i in range(5):
p = Process(target=append_to_list, args=(shared_list, i))
processes.append(p)
p.start()
for p in processes:
p.join()
# 输出最终的共享列表内容
print(shared_list)
if __name__ == "__main__":
main()
- manager.list() 创建了一个共享的列表,可以在多个进程间共享。
- 每个进程通过 append_to_list 函数将元素添加到共享列表中。
- 最终,所有进程都修改了共享列表。
使用 Manager 创建共享的 Namespace
from multiprocessing import Process, Manager
def update_namespace(shared_namespace):
shared_namespace.value = 42
shared_namespace.name = "Alice"
def main():
# 创建 Manager 实例
with Manager() as manager:
# 创建一个共享的 Namespace 对象
shared_namespace = manager.Namespace()
# 创建多个进程更新 Namespace 对象
processes = []
for i in range(3):
p = Process(target=update_namespace, args=(shared_namespace,))
processes.append(p)
p.start()
for p in processes:
p.join()
# 输出最终的 Namespace 内容
print(f"Shared Namespace: value={shared_namespace.value}, name={shared_namespace.name}")
if __name__ == "__main__":
main()
- manager.Namespace() 创建了一个可以在多个进程间共享的对象,可以像普通对象一样使用属性。
- 每个进程通过 update_namespace 函数修改 shared_namespace 中的属性。
- 最终,多个进程更新了共享的 Namespace 对象。
使用 Manager 创建共享的 Value
对于Manger创建的Value的Mutiprocessing创建的Value之间的差距我只找到了:共享的字符串只能用manager.Value()来实现,因为multiprocessing.Value()的参数不支持字符串。前面提到的不需要自己手动处理锁或其他同步机制主要是针对dict等变量,实际上对于Value来说比如上面修改Value值的操作还是要手动加锁以保证进程同步的。
此外Manger应该还有其他用法,目前没接触到暂不记录。
2. 进程同步
多进程操作时,可能会出现竞争条件,需要进行进程同步。multiprocessing 提供了 Lock、Event、Semaphore 等同步工具。
使用 Lock 进行进程同步
from multiprocessing import Process, Lock
def worker(lock):
with lock: # 获取锁
print("Worker is working")
if __name__ == "__main__":
lock = Lock()
processes = [Process(target=worker, args=(lock,)) for _ in range(3)]
for p in processes:
p.start()
for p in processes:
p.join()
- lock.acquire():获取锁,保证只有一个进程可以进入临界区。
- lock.release():释放锁,允许其他进程获取锁。
3. 多线程技术
线程 (Thread):是程序中的执行单元。每个程序至少有一个主线程 (Main Thread),程序中的其他线程可以在后台执行任务。
3.1 创建线程
使用 threading 模块时,最常见的创建线程的方法有两种:
- 通过继承 threading.Thread 类。
- 通过 threading.Thread 类传入目标函数。
例子1:通过继承 Thread 类创建线程
import threading
import time
class MyThread(threading.Thread):
def run(self):
print(f"Thread {threading.current_thread().name} is running.")
time.sleep(2)
print(f"Thread {threading.current_thread().name} finished.")
# 创建线程对象
thread1 = MyThread()
thread2 = MyThread()
# 启动线程
thread1.start()
thread2.start()
# 等待线程完成
thread1.join()
thread2.join()
print("All threads finished.")
thread调用start时会自动调用类中run函数,输出结果为:
Thread Thread-1 is running.
Thread Thread-2 is running.
Thread Thread-1 finished.
Thread Thread-2 finished.
All threads finished.
例子2:通过Thread直接传入目标函数
import threading
import time
def task():
print(f"Thread {threading.current_thread().name} is running.")
time.sleep(2)
print(f"Thread {threading.current_thread().name} finished.")
# 创建线程对象
thread1 = threading.Thread(target=task)
thread2 = threading.Thread(target=task)
# 启动线程
thread1.start()
thread2.start()
# 等待线程完成
thread1.join()
thread2.join()
print("All threads finished.")
输出结果和上面的相同。
3.2 传递参数给线程
线程的参数传递和进程基本相同,使用类创建的可直接使用类的成员变量,而通过threading.Thread创建的线程可以通过args传入参数,如下:
threading.Thread(target=XXX, args=(A, B, ))
3.3 线程间通信
在 Python 中,由于线程共享同一内存空间,线程间的通信通常通过共享数据结构或同步原语(如队列、锁、事件、条件变量等)来实现。最常用的线程间通信方法是使用队列(queue.Queue),因为它内置了线程安全的机制,适合用于不同线程之间传递信息。
使用Queue进行线程通信
注意这里的queue和前面进程介绍的queue不是同一个类,这里用于在一个共享空间内也就是线程内通信,而前面介绍的是在多进程间通信,其通信的双方不在一个空间下。
Python 提供了 queue.Queue 类,它是一个线程安全的队列,可以用于在多个线程之间传递数据。队列会自动处理线程同步,因此你不需要手动管理锁。
示例:使用队列进行线程间通信
import threading
import queue
import time
# 创建一个线程安全的队列
q = queue.Queue()
def producer():
for i in range(5):
print(f"Producer producing item {i}")
time.sleep(1)
q.put(i) # 向队列中放入数据
def consumer():
while True:
item = q.get() # 从队列中获取数据
if item is None: # 结束标志
break
print(f"Consumer consumed item {item}")
time.sleep(2)
# 创建并启动生产者线程和消费者线程
producer_thread = threading.Thread(target=producer)
consumer_thread = threading.Thread(target=consumer)
producer_thread.start()
consumer_thread.start()
# 等待生产者线程结束
producer_thread.join()
# 发送结束信号给消费者
q.put(None)
# 等待消费者线程结束
consumer_thread.join()
print("Producer and Consumer have finished.")
在这个例子中:
- producer 线程生产数据并放入队列。
- consumer 线程从队列中取出数据并消费。
- 使用 None 作为结束标志来告知消费者线程停止。
queue.Queue 自动处理了对队列的线程安全访问,因此不需要手动加锁。
全局变量
由于全局变量处于线程的共享空间中,所以可以利用全局变量实现线程间通信。但需要注意在使用全局变量时可能存在数据竞争等问题,需要考虑线程间同步。
import threading
# 全局变量
shared_counter = 0
lock = threading.Lock() # 创建一个锁对象
def increment():
global shared_counter
for _ in range(1000000):
with lock: # 使用锁来确保每次只有一个线程访问 shared_counter
shared_counter += 1
# 创建多个线程
threads = []
for _ in range(5):
thread = threading.Thread(target=increment)
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
print(f"Final counter value: {shared_counter}")
在这个例子中,lock.acquire() 和 lock.release() 确保了每次只有一个线程能够修改 shared_counter,从而避免了数据竞争问题。通过 with lock,Python 会在执行完相关操作后自动释放锁。
管道(multiprocessing.Pipe)
此外,例如前面介绍的进程间使用的管道,同样可以用于线程。
import threading
import time
from multiprocessing import Pipe
def worker(pipe):
print("Worker: Waiting for data...")
data = pipe.recv() # 接收数据
print(f"Worker: Received data: {data}")
def trigger(pipe):
print("Trigger: Sending data...")
time.sleep(2)
pipe.send("Hello from trigger") # 发送数据
# 创建管道
parent_conn, child_conn = Pipe()
# 创建并启动线程
worker_thread = threading.Thread(target=worker, args=(child_conn,))
trigger_thread = threading.Thread(target=trigger, args=(parent_conn,))
worker_thread.start()
trigger_thread.start()
worker_thread.join()
trigger_thread.join()
print("Worker and Trigger threads have finished.")
4. 线程同步
前面写道多线程需要考虑避免数据竞争,这里简单介绍一下实现线程同步的几种技术。
4.1 锁
在某些情况下,线程需要共享一些变量,但直接共享会导致数据竞争问题。为了避免这种情况,可以使用 threading.Lock 或 threading.RLock 来保护共享数据。
示例:共享变量和锁
import threading
# 共享数据
shared_counter = 0
lock = threading.Lock()
def increment():
global shared_counter
for _ in range(1000000):
with lock: # 使用锁来保护共享资源
shared_counter += 1
# 创建多个线程
threads = []
for _ in range(5):
thread = threading.Thread(target=increment)
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
print(f"Final counter value: {shared_counter}")
在这个例子中,多个线程访问共享变量 shared_counter,通过 lock 来确保每次只有一个线程能对其进行修改,从而避免了数据竞争。
4.2 条件变量(threading.Condition)
条件变量是一种更复杂的同步机制,允许线程在满足特定条件时通知其他线程。条件变量通常用于线程间的协调工作,例如,生产者-消费者模型中,当队列空时,消费者需要等待生产者放入新数据。
示例:使用条件变量进行线程间协调
import threading
import time
# 共享数据和条件变量
data_available = False
condition = threading.Condition()
def producer():
global data_available
with condition:
print("Producer: Producing data")
time.sleep(2)
data_available = True
condition.notify() # 通知消费者有数据可用
def consumer():
global data_available
with condition:
while not data_available:
print("Consumer: Waiting for data...")
condition.wait() # 等待生产者通知
print("Consumer: Consuming data")
data_available = False
# 创建并启动生产者和消费者线程
producer_thread = threading.Thread(target=producer)
consumer_thread = threading.Thread(target=consumer)
producer_thread.start()
consumer_thread.start()
producer_thread.join()
consumer_thread.join()
print("Producer and Consumer have finished.")
在这个例子中:
- 消费者线程在没有数据时会调用 condition.wait() 来等待生产者的通知。
- 生产者线程在生成数据后,使用 condition.notify() 通知消费者线程可以开始消费。
条件变量常用于复杂的线程同步场景,尤其是在需要多个线程等待某个条件时。
4.3 事件
threading.Event 是一个简单的同步原语,适用于线程间的信号传递。一个线程可以设置一个事件,其他线程可以等待该事件发生,直到事件被设置为“已发生”(set)。
示例:使用事件进行线程间通信
import threading
import time
# 创建事件对象
event = threading.Event()
def worker():
print("Worker: Waiting for event to be set...")
event.wait() # 等待事件被设置
print("Worker: Event is set, now working.")
def trigger():
print("Trigger: Setting the event...")
time.sleep(2)
event.set() # 设置事件,通知等待的线程
# 创建并启动线程
worker_thread = threading.Thread(target=worker)
trigger_thread = threading.Thread(target=trigger)
worker_thread.start()
trigger_thread.start()
worker_thread.join()
trigger_thread.join()
print("Worker and Trigger threads have finished.")
在这个例子中:
- worker 线程调用 event.wait() 等待事件发生。
- trigger 线程调用 event.set() 来触发事件,通知 worker 线程开始工作。
Event 通常用于线程间的简单同步,尤其是当一个线程需要等待另一个线程执行某个动作时。
这里先简单介绍一下几种线程同步,后面有时间会补充一些例如手动实现自旋锁的操作。
5. 注意事项
- 进程是独立的:每个进程都有自己的内存空间,不会直接共享内存数据。如果需要共享数据,需要使用队列、管道、共享内存等机制。
- Process 是异步的:start() 启动的进程不会等到执行完才返回,必须使用 join() 来阻塞主进程直到子进程完成。
- GIL(全局解释器锁):Python 的 GIL 会影响多线程的并行性,但多进程是每个进程有独立的内存空间,因此不会受到 GIL 的影响。
- 多线程与多进程适用范围:Python 的多线程适用于 I/O 密集型任务,可以显著提高程序性能,而多进程适用于计算密集型任务,可避免GIL限制。