深度学习基础:从入门到理解核心概念
引言
近年来,深度学习(Deep Learning)已成为人工智能领域最热门的研究方向之一。从AlphaGo战胜人类围棋冠军,到ChatGPT等大型语言模型的惊艳表现,深度学习技术正在深刻改变我们的生活和工作方式。本文将系统介绍深度学习的基础知识,帮助初学者建立对这一领域的全面认识。
一、什么是深度学习?
深度学习是机器学习的一个子领域,它通过模拟人脑神经元的工作方式,构建多层的神经网络模型,从数据中自动学习特征表示并进行预测或决策。
1.1 深度学习与机器学习的关系
- 传统机器学习:依赖人工特征工程,模型相对简单
- 深度学习:自动学习特征表示,模型复杂度高,需要大量数据
1.2 深度学习的特点
1.层次化特征学习:通过多层网络逐步提取从低级到高级的特征
2. 端到端学习:直接从原始数据学习到最终输出
3.强大的表示能力:能够建模复杂的非线性关系
4. 大数据依赖性:通常需要大量标注数据才能取得良好效果
二、神经网络基础
2.1 感知机:最简单的神经网络
感知器是神经网络的基本单元,其数学模型为:
y = f(w·x + b)
其中:
- x:输入向量
- w:权重向量
- b:偏置项
- f:激活函数
2.2 激活函数的作用
激活函数为神经网络引入非线性,常见的激活函数包括:
1. Sigmoid:σ(x) = 1/(1+e^-x),输出范围(0,1)
2. Tanh:tanh(x) = (e^x - e^-x)/(e^x + e^-x),输出范围(-1,1)
3. ReLU:f(x) = max(0,x),目前最常用的激活函数
4. Leaky ReLU:f(x) = max(αx,x),解决ReLU的"神经元死亡"问题
2.3 神经网络的结构
典型的神经网络包含:
- 输入层:接收原始数据
- 隐藏层:进行特征变换和学习
- 输出层:产生最终预测结果
三、深度学习的核心概念
3.1 前向传播与反向传播
1. 前向传播:数据从输入层流向输出层,计算预测值
2. 反向传播:根据预测误差,从输出层反向调整网络参数
3.2 损失函数
衡量模型预测与真实值差异的函数,常见的有:
- 均方误差(MSE):用于回归问题
- 交叉熵(Cross-Entropy):用于分类问题
3.3 优化算法
最常用的是梯度下降及其变种:
1. 随机梯度下降(SGD)
2. 动量法(Momentum)
3. Adam:结合了动量法和自适应学习率
3.4 正则化技术
防止过拟合的方法:
1. L1/L2正则化:在损失函数中添加参数惩罚项
2. Dropout:训练时随机丢弃部分神经元
3. Batch Normalization:规范化层输入,加速训练
四、常见的深度学习模型
4.1 卷积神经网络(CNN)
特别适合处理图像数据,核心组件:
- 卷积层:提取局部特征
- 池化层:降维,保持平移不变性
- 全连接层:最终分类
典型结构:LeNet-5, AlexNet, VGG, ResNet等
4.2 循环神经网络(RNN)
处理序列数据的网络,具有"记忆"能力:
- 基本RNN
- LSTM:解决长程依赖问题
- GRU:LSTM的简化版
应用领域:自然语言处理、语音识别、时间序列预测
4.3 生成对抗网络(GAN)
由生成器和判别器组成:
- 生成器:生成假数据
- 判别器:区分真假数据
应用:图像生成、风格迁移、数据增强
4.4 Transformer
基于自注意力机制的模型,已成为NLP领域的主流架构:
- 核心组件:Self-Attention, Multi-Head Attention
- 典型模型:BERT, GPT系列
实例
1、导入必要的模块:
import torch
print(torch.__version__)
# 导入必要的模块
from torch import nn # 神经网络模块
from torch.utils.data import DataLoader # 数据加载器
from torchvision import datasets # 视觉数据集
from torchvision.transforms import ToTensor # 将图像转换为张量2、加载数据集:
# 下载训练数据集
training_data = datasets.MNIST(
root='data', # 数据保存路径
train=True, # 加载训练集
download=True, # 如果本地没有则下载
transform=ToTensor(), # 转换为张量
)
# 下载测试数据集
test_data = datasets.MNIST(
root='data',
train=False, # 加载测试集
download=True,
transform=ToTensor(),
)
print(len(training_data)) # 输出训练集大小(60000)3、数据可视化
from matplotlib import pyplot as plt
# 创建图像窗口
figure = plt.figure()
# 显示最后9张训练图像
for i in range(9):
img, label = training_data[i+59000] # 获取图像和标签
# 添加子图
figure.add_subplot(3, 3, i+1)
plt.title(label) # 设置标题为标签值
plt.axis("off") # 不显示坐标轴
plt.imshow(img.squeeze(), cmap="gray") # 显示灰度图像
# squeeze()移除长度为1的维度
a = img.squeeze()
plt.show() # 显示图像4、创建数据加载器:
# 创建训练数据加载器
train_dataloader = DataLoader(training_data, batch_size=64)
# 创建测试数据加载器
test_dataloader = DataLoader(test_data, batch_size=64)5、设置计算设备:
# 检测可用设备
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device")6、定义神经网络:
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
# 定义网络层
self.flatten = nn.Flatten() # 展平层(28*28 -> 784)
self.hidden1 = nn.Linear(28*28, 128) # 全连接层1
self.hidden2 = nn.Linear(128, 256) # 全连接层2
self.out = nn.Linear(256, 10) # 输出层
def forward(self, x):
# 定义前向传播
x = self.flatten(x)
x = self.hidden1(x)
x = torch.relu(x) # ReLU激活函数
x = self.hidden2(x)
x = torch.relu(x)
x = self.out(x)
return x
# 创建模型实例并移动到设备
model = NeuralNetwork().to(device)
print(model)7、定义训练和测试函数:
def train(dataloader, model, loss_fn, optimizer):
model.train() # 设置为训练模式
batch_size_num = 1
for X, y in dataloader: # 遍历数据批次
X, y = X.to(device), y.to(device) # 数据移动到设备
# 前向传播
pred = model(X) # 计算预测值
loss = loss_fn(pred, y) # 计算损失
# 反向传播
optimizer.zero_grad() # 梯度清零
loss.backward() # 计算梯度
optimizer.step() # 更新参数
# 打印训练信息
loss_value = loss.item()
if batch_size_num % 100 == 0:
print(f'loss:{loss_value:>7f} [number:{batch_size_num}]')
batch_size_num += 1
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset) # 数据集大小
num_batches = len(dataloader) # 批次数量
model.eval() # 设置为评估模式
test_loss, correct = 0, 0
with torch.no_grad(): # 禁用梯度计算
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X) # 计算预测
# 累计损失和正确预测数
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
# 计算平均损失和准确率
test_loss /= num_batches
correct /= size
print(f'Test result: \n Accuracy: {(100*correct)}%, Avg loss: {test_loss}')8、模型的训练和评估:
# 定义损失函数和优化器
loss_fn = nn.CrossEntropyLoss() # 交叉熵损失
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # Adam优化器
# 训练多个epoch
epochs = 16
for epoch in range(epochs):
print(f"Epoch {epoch+1}\n-------------------------------")
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model, loss_fn)
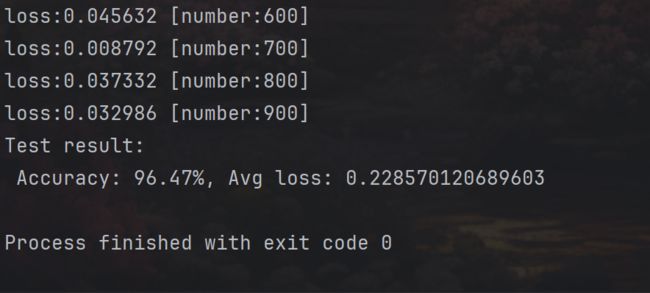
print("Done!")结果显示:
结语
深度学习作为人工智能的核心技术,正在各个领域展现出强大的能力。掌握深度学习的基础知识是进入这一领域的第一步。希望本文能为初学者提供一个系统的知识框架,更多深入的内容还需要在实践中不断学习和探索。