顺序表和链表,时间和空间复杂度--数据结构初阶(1)(C/C++)
文章目录
- 前言
- 时间复杂度和空间复杂度
-
- 理论部分
- 习题部分
- 顺序表和链表
-
- 理论部分
- 作业部分
前言
这期的话会给大家讲解复杂度,顺序表和链表的一些知识和习题部分(重点是习题部分,因为这几个理念都比较简单)
时间复杂度和空间复杂度
理论部分
时间复杂度和空间复杂度的计算一般都是遵循大O表示法,然后的话时间复杂度的计算都是按照最坏的情况计算的
大O表示法的相关概念:
1.用常数1取代运行时间中的所有加法常数。
2、在修改后的运行次数函数中,只保留最高阶项。
3、如果最高阶项存在且不是1,则去除与这个项目相乘的常数。得到的结果就是大O阶
习题部分

这道题要注意的地方是在代码上这里的循环虽然让人感觉是n次,但是实际上没有执行到n次,应该选择D选项
题目:力扣 移除元素(移除特定元素的好办法)
原地移除,并且要不变的元素移到前面,方法:
遇到不等于val的元素(第k个)时,就把该元素移到第k个位置即可
此题不了解的知识:a[0] = a[0]是不会报错的
代码展示:
class Solution {
public:
int removeElement(vector& nums, int val) {
int k = 0;
int n = nums.size();
for(int i = 0;i<=n-1;i++)
{
if(nums[i]!= val)
nums[k++] = nums[i];
}
return k;
}
};
顺序表和链表
理论部分
链表能做的事,顺序表都可以完成,只是操作方法不同,效率不同
顺序表比链表唯一好的地方就是找下标为多少的位置好,其他都是链表好些
顺序表跟数组非常的相似,几乎可以说是一模一样
链表的话有用数组模拟的,还有用结构体去模拟的,一般来说,在竞赛方面,一般都是用数组去模拟(但是感觉竞赛没必要用链表),在工程方面的话,一般是动态去用结构体去模拟
顺序表的动态模拟:
typedef int SLDataType;
typedef struct SeqList
{
SLDataType* a;
int size; // 有效数据个数
int capacity; // 空间容量
}SL;
// 增删查改
void SLInit(SL* ps);
void SLDestroy(SL* ps);
void SLPrint(SL* ps);
void SLCheckCapacity(SL* ps);
void SLInsert(SL* ps, int pos, SLDataType x);
void SLErase(SL* ps, int pos);
int SLFind(SL* ps, SLDataType x);
void SLInit(SL* ps)
{
assert(ps);
ps->a = (SLDataType*)malloc(sizeof(SLDataType)* INIT_CAPACITY);
if (ps->a == NULL)
{
perror("malloc fail");
return;
}
ps->size = 0;
ps->capacity = INIT_CAPACITY;
}
void SLDestroy(SL* ps)
{
assert(ps);
free(ps->a);
ps->a = NULL;
ps->capacity = ps->size = 0;
}
void SLPrint(SL* ps)
{
assert(ps);
for (int i = 0; i < ps->size; ++i)
{
printf("%d ", ps->a[i]);
}
printf("\n");
}
void SLCheckCapacity(SL* ps)
{
assert(ps);
if (ps->size == ps->capacity)
{
SLDataType* tmp = (SLDataType*)realloc(ps->a, sizeof(SLDataType) * ps->capacity * 2);
if (tmp == NULL)
{
perror("realloc fail");
return;
}
ps->a = tmp;
ps->capacity *= 2;
}
}
void SLInsert(SL* ps, int pos, SLDataType x)
{
assert(ps);
assert(pos >= 0 && pos <= ps->size);
SLCheckCapacity(ps);
int end = ps->size - 1;
while (end >= pos)
{
ps->a[end + 1] = ps->a[end];
--end;
}
ps->a[pos] = x;
ps->size++;
}
void SLErase(SL* ps, int pos)
{
assert(ps);
assert(pos >= 0 && pos < ps->size);
int begin = pos + 1;
while (begin < ps->size)
{
ps->a[begin - 1] = ps->a[begin];
++begin;
}
ps->size--;
}
int SLFind(SL* ps, SLDataType x)
{
assert(ps);
for(int i = 0; i < ps->size; ++i)
{
if (ps->a[i] == x)
{
return i;
}
}
return -1;
}
在书写的时候需要注意的几个点:
1.ps.a[ps.size++]这里面的ps.size可以不打括号,因为是类似名字
2.扩容一般喜欢扩为原来的二倍(因为以后C++的STL中的一般都是这样搞的,比如vector)
3.开辟空间一定要检查开辟成功没有
说到开辟成功与否,还有个要注意的点是数组那个叫做越界 指针那个叫做空指针或者野指针,不要叫错了
链表的动态模拟:
typedef int SLTDataType;
typedef struct SListNode
{
SLTDataType data;
struct SListNode* next;
}SLTNode;
// 单链表查找
SLTNode* SLTFind(SLTNode* phead, SLTDataType x);
// pos之前插入
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x);
// pos位置删除
void SLTErase(SLTNode** pphead, SLTNode* pos);
// pos后面插入
void SLTInsertAfter(SLTNode* pos, SLTDataType x);
// pos位置后面删除
void SLTEraseAfter(SLTNode* pos);
SLTNode* SLTFind(SLTNode* phead, SLTDataType x)
{
SLTNode* cur = phead;
while (cur)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
// pos之前插入
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
assert(pos);
assert(pphead);
if (pos == *pphead)
{
SLTPushFront(pphead, x);
}
else
{
// 找到pos的前一个位置
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
SLTNode* newnode = BuySLTNode(x);
prev->next = newnode;
newnode->next = pos;
}
}
// pos位置删除
void SLTErase(SLTNode** pphead, SLTNode* pos)
{
assert(pphead);
assert(pos);
//assert(*pphead);
if (*pphead == pos)
{
SLTPopFront(pphead);
}
else
{
// 找到pos的前一个位置
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = pos->next;
free(pos);
//pos = NULL;
}
}
// pos后面插入
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{
assert(pos);
SLTNode* newnode = BuySLTNode(x);
newnode->next = pos->next;
pos->next = newnode;
}
// pos位置后面删除
void SLTEraseAfter(SLTNode* pos)
{
assert(pos);
assert(pos->next);
SLTNode* del = pos->next;
pos->next = del->next;
free(del);
del = NULL;
}
注意事项:
不难发现,其中有些函数的形参是*有些是**,这个的话要看是要改什么
一般来说,可以总结为一句话,传想改的东西的地址过去,比如:你想改指针本身,那就要把指针的地址传过去
还有就是,链表的头节点要赋值给其他再拿去了,不然就会"一去不复返"
作业部分
在这里先总结一手:
链表这里最好单用头插或者尾插 而不用中间插入删除这些(除非没有更好的思路了,不然麻烦)
取巧的办法:把链表里面的值放到数组中去搞(面试会卡空间复杂度让你不能用这个)
单链表的话一般不动头结点,而是再搞一个尾节点去动尾节点,不然后面要用头就不行了
单链表可能空的话建议加个哨兵位,不然要分很多类讨论
注意:创建结构体变量跟开辟空间的区别:
创建结构体变量就相当于开辟了空间
创建的是结构体指针的话,要自己为结构体开辟空间(自己一般这么搞的)
代码展示:
struct Nodenew = (struct Node)malloc(sizeof(struct Node));
力扣 合并两个有序数组
这个题从前面开始比较的话会需要把后面的往后推
从后面开始比较就不用,所以采用从后面开始比较的方法
代码展示:
class Solution {
public:
void merge(vector& nums1, int m, vector& nums2, int n) {
while(n>0&&m>0)
{
if(nums1[m-1]>nums2[n-1])
{
nums1[m+n-1] = nums1[m-1];
m--;
}
else{
nums1[m+n-1] = nums2[n-1];
n--;
}
}
while(n>0)
{
nums1[n-1] = nums2[n-1];
n--;
}
}
};
力扣 删除链表中等于给定值 val 的所有结点
1.传统做法:
当前指针cur cur前面的那个指针prev,然后用cur去遍历看
2.不是val的值就尾插到新链表中(我选的是这一种)
代码展示:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* removeElements(struct ListNode* head, int val) {
struct ListNode*tail = NULL;
struct ListNode*old = head;
int num = 0;
while(old)
{
if(old->val!=val)
{
if(tail == NULL)
{
head = tail = old;
num++;
}
else{
tail->next = old;
tail = tail->next;
num++;
}
}
old = old->next;
}
if(tail)
{
tail->next = NULL;
}
if(!num)
{
head = NULL;
}
return head;
}
力扣 链表的中间结点
做法:快慢指针
慢指针一次走一个next 快指针一次走两个next
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* middleNode(struct ListNode* head) {
struct ListNode *slow = head;
struct ListNode *fast = head;
while(fast&&fast->next)
{
slow = slow->next;
fast = fast->next->next;
}
return slow;
}
例题:牛客网 返回倒数第k个节点的值
做法:快指针比慢指针多走k个节点
力扣 反转链表
做法:
取旧节点头插到新链表里
另外,这题让返回链表,其实就是返回头节点
代码展示:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* reverseList(struct ListNode* head) {
struct ListNode* newhead = NULL ;
struct ListNode*a = head;
struct ListNode*next ;
while(a)
{
next = a->next;
a->next = newhead;
newhead = a;
a = next;
}
return newhead;
}
例题:力扣 合并两个有序链表
做法:依次比较 取小的尾插
注意:头节点在第一次插的时候要记得给第一个插的节点的地址,而不是还是eg:NULL
代码展示:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) {
if(list1 == 0)
return list2;
if(list2 == 0)
return list1;
struct ListNode*cur1 = list1,*cur2 = list2;
struct ListNode*list3 = NULL;
struct ListNode*tail = NULL;
while(cur1&&cur2)
{
if(cur1->val>cur2->val)
{
if(list3 == NULL)
{
list3 = tail = cur2;
cur2 = cur2->next;
}
else{
tail->next = cur2;
cur2 = cur2->next;
tail = tail->next;
}
}
else
{
if(list3 == NULL)
{
list3 = tail = cur1;
cur1 = cur1->next;
}
else{
tail->next = cur1;
cur1 = cur1->next;
tail = tail->next;
}
}
}
if(cur1!= NULL) tail->next = cur1;
else tail->next = cur2;
return list3;
}
例题:牛客网 链表分割
做法:小于x的尾插到一个链表
大于x的尾插到另一个链表 然后把这两个链接起来(后面那个哨兵位的头结点不要)
这里说不能改变原来数据的顺序–代码中间改没问题,只要最后跟原来一样就行
代码展示:
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) : val(x), next(NULL) {}
};*/
class Partition {
public:
ListNode* partition(ListNode* pHead, int x) {
// write code here
ListNode*ghead = NULL,*gtail = NULL,*lhead = NULL,*ltail = NULL;
while(pHead)
{
if(pHead->valnext = pHead;
ltail = ltail->next;
}//!!!
}
else{
if(ghead ==NULL)
{
ghead = gtail = pHead;
}
else{
gtail->next = pHead;
gtail = gtail->next;
}
}
pHead = pHead->next;
}
if (gtail) gtail->next = NULL;
if (ltail) ltail->next = ghead;
return lhead?lhead:ghead;
}
};
例题:牛客网 链表的回文结构
做法:1.找到中间节点 2.从中间节点开始,对后半段逆置 3.前半段和后半段比较就行
代码展示:
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) : val(x), next(NULL) {}
};*/
class PalindromeList {
public:
bool chkPalindrome(ListNode* A) {
// write code here
ListNode*slow = A,*fast = A;
while(fast&&fast->next)//!!!!!!!!
{
slow = slow->next;
fast = fast->next->next;
}
ListNode*cur = slow;
ListNode*prev = nullptr;
ListNode*tmp = nullptr;
while(cur)
{
tmp = cur->next;
cur->next = prev;
prev = cur;
cur = tmp;
}
ListNode*head = prev;
while(head)
{
if(head->val!=A->val)
return false;
head = head->next;
A = A->next;
}
return true;
}
};
例题:力扣 相交链表
做法:1.分别求两个链表的长度 2.长的链表先走差距步 3.再同时走,第一个地址相同的就是交点
代码展示:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {
int lenA = 0;int lenB = 0;
struct ListNode* cur1 = headA;
struct ListNode* cur2 = headB;
while(cur1)
{
cur1 = cur1->next;
lenA++;
}
while(cur2)
{
cur2 = cur2->next;
lenB++;
}
int gap = abs(lenA-lenB);
struct ListNode*longlist = headA; struct ListNode*shortlist = headB;
if(lenAnext;
while(longlist)
{
if(longlist == shortlist)
return longlist;
longlist = longlist->next;
shortlist = shortlist->next;
}
return NULL;
}
例题: 力扣 环形链表
做法:快慢指针(这里选择fast一次两步,slow一次一步)
while(fast&&fast->next)
{
slow = slow->next;
fast = fast->next->next;
}
延伸的常考问题:(这个是企业面试时的常考点)
1.为什么slow走1步,fast走2步,他们会相遇?会不会错过?请证明
slow进环以后,fast开始追击slow,slow每走一步,fast走两步,他们之间的距离缩小1
当距离为0的时候就追上了
2.为什么slow走1步,fast走n步(n>=3),他们会相遇?会不会错过?请证明
如果之间的距离N是n-1的倍数的话才能相遇,否则余数不为0是追不上的
3.求环的长度:
让slow再走到跟fast的相遇点的步数就是
4.求入环的第一个结点(也就是入口点)
例题:力扣 环形链表II
这里有个结论(带一个环的链表):
一个指针从相遇点走,一个指针从起始点走,会在入口点相遇
(怎么推出来的要知道)
做法:1.用那个结论
2.让相遇点跟相遇点的下一个节点之间的链接断开
然后将找入口点问题转换成找链表的交点
代码展示:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
bool hasCycle(struct ListNode *head) {
struct ListNode*fast = head,*slow = head;
while(fast&&fast->next)
{
slow = slow->next;
fast = fast->next->next;
if(slow == fast)
return true;
}
return false;
}
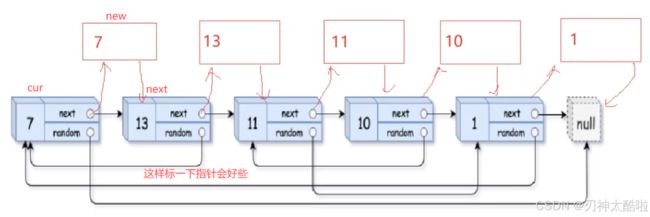
例题;力扣 复制带随机指针的链表
做法:1.先复制旧节点然后连在每个旧节点后面(NULL不复制)
2.把新节点的random搞一下(新节点->random = 旧节点->random->next)
3.把新节点从旧节点的链表上断下来成为新链表
代码展示:
/**
* Definition for a Node.
* struct Node {
* int val;
* struct Node *next;
* struct Node *random;
* };
*/
struct Node* copyRandomList(struct Node* head) {
struct Node*newhead = NULL;
struct Node*new = NULL;
struct Node*old = head;
struct Node*tail = NULL;
while(old)
{
new = (struct Node*)malloc(sizeof(struct Node));
new->val = old->val;
new->next = old->next;
tail = old->next;
old->next = new;
old = tail;
}
old = head;
while(old)
{
new = old->next;
if(old->random)
new->random = old->random->next;//!!!
else{
new->random = NULL;
}
if(old->next)
old = old->next->next;
else{
break;
}
}
//新节点脱落
old = head;
while(old)
{
if(old == head)
new = newhead = old->next;
if(old->next)
old = old->next->next;
if(new->next)
{
new->next = new->next->next;
new = new->next;//!!!
}
}
return newhead;
}