RocketMQ消息存储概念篇
一、引言
消息存储作为RocketMQ最重要,最复杂的一个模块,理解和掌握好它的消息存储机制,对学习RocketMQ来说是至关重要的,接下来对于其中的核心理论知识先有一个了解。
二、RocketMQ消息存储概述
在了解下面的内容之前我们先来看一下消息存储整体的架构图:
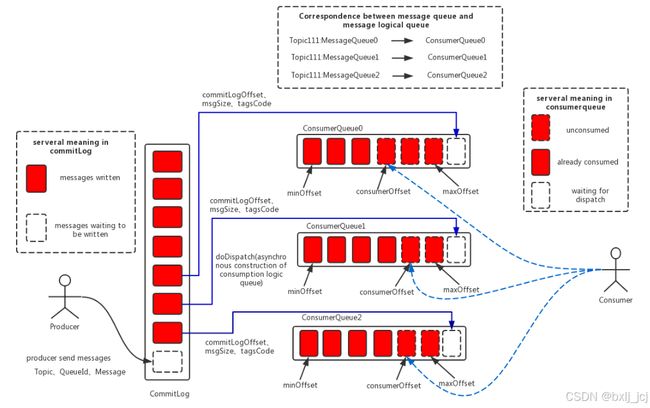
2.1 消息存储文件构成
RocketMQ对于文件的存储管理最重要的文件有三个:
- IndexFile文件
- ConsumeQueue文件
- CommitLog文件
IndexFile:IndexFile(索引文件)提供了一种可以通过key或时间区间来查询消息的方法。Index文件的存储位置是:$HOME \store\index\${fileName},文件名fileName是以创建时的时间戳命名的,固定的单个IndexFile文件大小约为400M,一个IndexFile可以保存 2000W个索引,IndexFile的底层存储设计为在文件系统中实现HashMap结构,故rocketmq的索引文件其底层实现为hash索引。
ConsumeQueue:消息消费的时候他实际上会涉及到一个查询工作,这个时候就需要在不同的队列中进行查找,为了能快速定位到消息在CommitLog中的位置,就需要一些索引来加速查找,而我们这个索引组成的文件就是ConsumeQueue,每一个队列都会有一组这样的文件。
CommitLog:消息发送到Broker,同时要求消息是可靠存储的,势必要存储这些消息体,存储这些消息体的文件就是CommitLog。消息主体以及元数据的存储主体,存储Producer端写入的消息主体内容,消息内容不是定长的。单个文件大小默认1G, 文件名长度为20位,左边补零,剩余为起始偏移量,比如00000000000000000000代表了第一个文件,起始偏移量为0,文件大小为1G=1073741824;当第一个文件写满了,第二个文件为00000000001073741824,起始偏移量为1073741824,以此类推。消息主要是顺序写入日志文件,当文件满了,写入下一个文件。
小结:
| 组件 | 主要作用 | 功能特点 |
| IndexFile | 提供消息索引,加速基于条件的消息查询 | 基于主题、标签、消息ID等信息快速索引消息 |
| ConsumeQueue | 提供消息消费的快速定位,存储消费进度信息 | 存储消息在 CommitLog 中的位置,加速消息消费 |
| CommitLog | 存储所有的消息,确保消息持久化 | 顺序写入、高效持久化、消息不可修改、保证数据不丢失 |
在上面的RocketMQ的消息存储整体架构图中可以看出,RocketMQ采用的是混合型的存储结构,即为Broker单个实例下所有的队列共用一个日志数据文件(即为CommitLog)来存储。RocketMQ的混合型存储结构(多个Topic的消息实体内容都存储于一个CommitLog中)针对Producer和Consumer分别采用了数据和索引部分相分离的存储结构,Producer发送消息至Broker端,然后Broker端使用同步或者异步的方式对消息刷盘持久化,保存至CommitLog中。只要消息被刷盘持久化至磁盘文件CommitLog中,那么Producer发送的消息就不会丢失。正因为如此,Consumer也就肯定有机会去消费这条消息。当无法拉取到消息后,可以等下一次消息拉取,同时服务端也支持长轮询模式,如果一个消息拉取请求未拉取到消息,Broker允许等待30s的时间,只要这段时间内有新消息到达,将直接返回给消费端。RocketMQ的具体做法是,使用Broker端的后台服务线程—ReputMessageService不停地分发请求并异步构建ConsumeQueue(逻辑消费队列)和IndexFile(索引文件)数据。
2.2 消息的存储过程
在了解完上面三个文件后,接下来了解一下消息生产到存储然后在去消费是怎么进行的,以及消息是如何保存在文件里面去的。
当生产者发送消息的时候,实际上消息体会存储到CommitLog里面去,存储完成后,发送就到此结束了。后面会基于CommitLog文件的数据,RocketMQ会异步构建出IndexFile文件和ConsumeQueue文件,这两个文件主要是为了加速我们消息的查询。
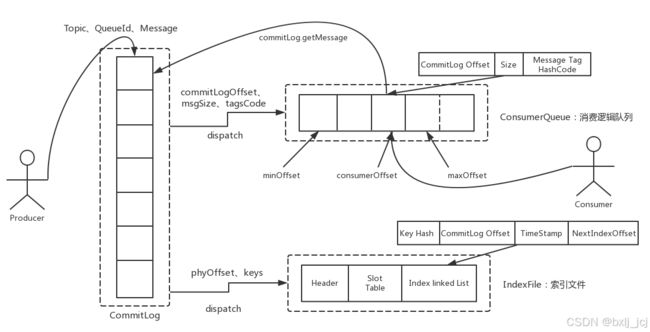
当我们消费者去消费消息的时候,需要到指定的队列和指定的队列的offset位置进行消息拉取,这个时候就会去ConsumeQueue里面去查找消息在CommitLog文件中的位置,然后返回给消费者。
在RocketMQ中,消息在服务端的存储结构如下,每条消息都会有对应的索引信息,Consumer通过ConsumeQueue这个二级索引来读取消息实体内容,其流程如下:
三、IndexFile文件
在介绍完上面的内容之后,我们现在来解决IndexFile这个文件。
概念:IndexFile是一个存储消息索引的文件,用于提高消息的查询效率。它通过为消息建立索引,允许根据消息的关键字、主题或其它信息来快速查询特定消息。
作用:
- 消息查询:IndexFile提供了基于消息主题、消息标签等的索引查询功能。消费者可以通过索引快速定位消息的位置,而不必遍历整个
CommitLog。 - 支持消息的快速定位:通过为消息建立索引,
IndexFile可以大大加速消息的检索速度,特别是在对消息进行复杂查询时(例如根据消息的关键字查找)。
我们接下来看看RocketMQ是如何构建IndexFile数据结构的:
public IndexFile(
// 文件名称
final String fileName,
// hash槽位数量
final int hashSlotNum,
// 索引数量
final int indexNum,
// 结尾物理偏移量
final long endPhyOffset,
// 结尾时间戳
final long endTimestamp) throws IOException {
// 计算索引文件总大小:header大小(40个字节)+ hash槽位数量(500w个)*hash槽位大小(4个字节)+ 索引数量(500w*4)* 索引大小(20个字节)
int fileTotalSize = IndexHeader.INDEX_HEADER_SIZE + (hashSlotNum * hashSlotSize) + (indexNum * indexSize);
// 基于索引文件名称和索引文件总大小构建一个mappedfile
this.mappedFile = new MappedFile(fileName, fileTotalSize);
// 获取nio文件通道
this.fileChannel = this.mappedFile.getFileChannel();
// 获取内存映射区域
this.mappedByteBuffer = this.mappedFile.getMappedByteBuffer();
// hash槽位数量
this.hashSlotNum = hashSlotNum;
// index索引数量
this.indexNum = indexNum;
// 获取到内存映射区域
ByteBuffer byteBuffer = this.mappedByteBuffer.slice();
// 构建一个索引头
this.indexHeader = new IndexHeader(byteBuffer);
// 给索引头设置起始物理偏移量和结尾物理偏移量
if (endPhyOffset > 0) {
this.indexHeader.setBeginPhyOffset(endPhyOffset);
this.indexHeader.setEndPhyOffset(endPhyOffset);
}
// 给索引头设置起始时间戳和结尾时间戳
if (endTimestamp > 0) {
this.indexHeader.setBeginTimestamp(endTimestamp);
this.indexHeader.setEndTimestamp(endTimestamp);
}
}RocketMQ的索引文件逻辑结构,类似JDK中HashMap的实现。索引文件的具体结构如下:
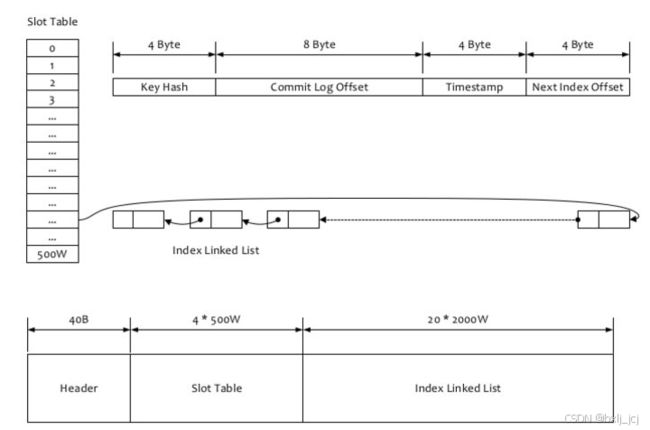
通过上面的代码结合我们的图示,对我们的一个IndexFile文件有了一个更加熟悉的了解。
接下来我们来看看往IndexFile里面写入一条索引数据的过程:
-
先去获取到key的hash值
-
对keyhash在500w个槽位里做一个取模,路由到一个槽位里去
-
把槽位绝对位置前面加上index header大小,以及再加上槽位位置是逻辑的*4个字节的槽位大小,计算拿出来索引槽位的绝对位置
-
再次计算出绝对index位置,index头大小+跳过全部的500w个槽位*4个字节+跳过已经写入index数量*20个字节,一个索引文件结构,header+500w个槽位*4个字节+一个一个20个字节的index往后依次写入
-
然后往索引文件具体的数据结构写入对应的值
说完了往IndexFile里面写入数据,接下来我们看看他是如何查询的。
RocketMQ支持按照下面两种维度(“按照Message Id查询消息”、“按照Message Key查询消息”)进行消息查询。而按照Message Key查询消息”,主要是基于RocketMQ的IndexFile索引文件来实现的。
按照Message Key查询消息”的方式,RocketMQ的具体做法是,主要通过Broker端的QueryMessageProcessor业务处理器来查询,读取消息的过程就是用topic和key找到IndexFile索引文件中的一条记录,根据其中的commitLog offset从CommitLog文件中读取消息的实体内容。
具体的查询过程如下:
-
先获取到一个keyhash,根据keyhash路由定位到我们的slot
-
然后再去定位到这个slot绝对位置,header+slot * 4个字节
-
先去查找这个slot最后一个存放的是第几个index
-
定位到这个index的绝对位置,依次获取index对应的keyhash,物理位置,存储时间和起始时间的差值
-
同时匹配了时间,以及keyHash是相等的,此时就可以把他的物理偏移量加入到结果list里去
-
根据物理偏移量去CommitLog文件中读取消息的实体内容
四、ConsumeQueue文件
通过上面的学习我们对IndexFile有了一个基础的认识,我们现在再来看看ConsumeQueue它的数据结构以及如何存储数据的,
ConsumerQueue相当于CommitLog的索引文件,消费者消费时会先从ConsumerQueue中查找消息在CommitLog中的offset,再去CommitLog中找原始消息数据。如果某个消息只在CommitLog中有数据,没在ConsumerQueue中, 则消费者无法消费。
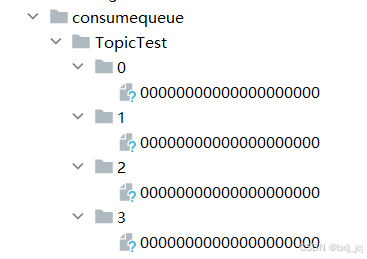
每个ConsumeQueue都有一个queueId,queueId 的值为0到TopicConfig配置的队列数量。比如某个Topic的消费队列数量为4,那么四个ConsumeQueue的queueId就分别为0、1、2、3,如下图所示:
接着看看ConsumeQueue的一个数据结构:
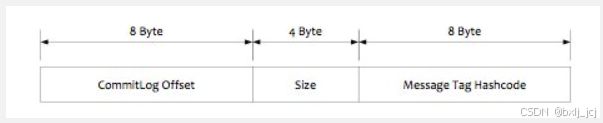
consumequeue文件采取定长设计,每一个条目共20个字节,分别为8字节的commitlog物理偏移量、4字节的消息长度、8字节tag hashcode,单个文件由30W个条目组成,可以像数组一样随机访问每一个条目,每个ConsumeQueue文件大小约5.72M。
在了解了它的数据结构之后,我们再来看看它是如何添加数据到ConsumeQueue,先看一下它的方法头:
private boolean putMessagePositionInfo(
final long offset, // 消息的偏移量
final int size, // 消息的大小
final long tagsCode, // 消息->tags
final long cqOffset) { // 这个消息在consumequeue里写入的偏移量位置
......
}具体操作流程如下:
-
把消息的offset、size以及tagscode,写入到一个临时的index buffer
-
预计的一个逻辑上的偏移量,是用consumequeue offset * 20个字节
-
根据偏移量定位到这个consumequeue的一个mappedfile
-
计算出最大的物理偏移量
-
基于mappedfile追加一条消息的索引数据进入到consumequeue文件里去
五、小结
通过上面的介绍我们知道了IndexFile和ConsumerQueue数据结构,以及它如何put数据以及查询数据,对于我们接下来进一步学习和掌握RokcetMQ将会有很大的帮助。