(5)cuda中的grid、block
文章目录
-
- 概要
- 整体架构流程
- 打印grid和block的维度
- 计算每个线程在block中的索引
- 计算每个线程在grid中的索引
- 完整代码与输出
- 输出gpu信息
概要
在CUDA中,host和device是两个重要的概念,我们用host指代CPU及其内存,而用device指代GPU及其内存。
一般的CUDA程序的执行流程如下:
- 分配host内存,并进行数据初始化;
- 分配device内存,并从host将数据拷贝到device上;
- 调用CUDA的核函数在device上完成指定的运算;
- 将device上的运算结果拷贝到host上;
- 释放device和host上分配的内存。
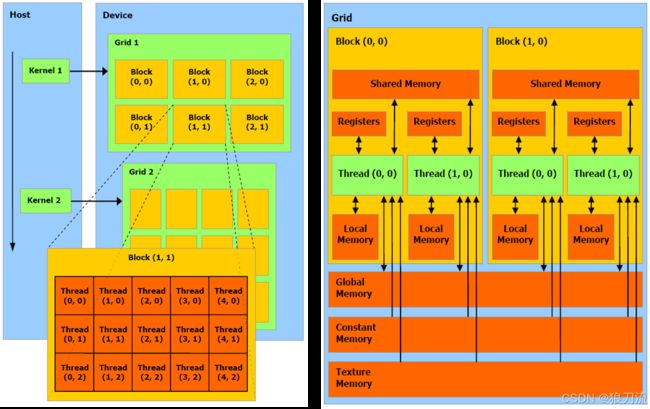
整体架构流程
一般来说:
一个kernel对应一个grid
一个grid可以有多个block,一维~三维
一个block可以有多个thread,一维~三维
我们写的kernel function运行在block中的每个thread中。
https://cuda-programming.blogspot.com/2013/01/thread-and-block-heuristics-in-cuda.html
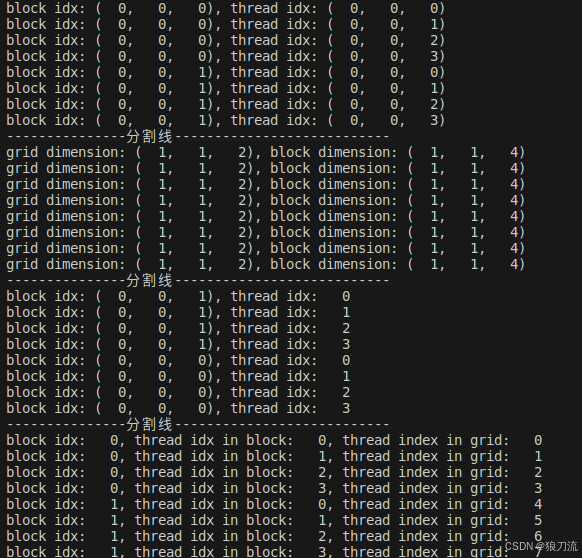
#include 打印grid和block的维度
__global__ void print_dim(){
printf("grid dimension: (%3d, %3d, %3d), block dimension: (%3d, %3d, %3d)\n",
gridDim.z, gridDim.y, gridDim.x,
blockDim.z, blockDim.y, blockDim.x);
}
计算每个线程在block中的索引
__global__ void print_thread_idx_per_block(){
int index = threadIdx.z * blockDim.x * blockDim.y + \
threadIdx.y * blockDim.x + \
threadIdx.x;
printf("block idx: (%3d, %3d, %3d), thread idx: %3d\n",
blockIdx.z, blockIdx.y, blockIdx.x,
index);
}
计算每个线程在grid中的索引
__global__ void print_thread_idx_per_grid(){
int block_Size = blockDim.z * blockDim.y * blockDim.x;
int block_Index = blockIdx.z * gridDim.x * gridDim.y + \
blockIdx.y * gridDim.x + \
blockIdx.x;
int thread_Index = threadIdx.z * blockDim.x * blockDim.y + \
threadIdx.y * blockDim.x + \
threadIdx.x;
int thread_index_in_grid = block_Index * block_Size + thread_Index;
printf("block idx: %3d, thread idx in block: %3d, thread index in grid: %3d\n",
block_Index, thread_Index, thread_index_in_grid);
}
完整代码与输出
#include cmake_minimum_required(VERSION 3.10)
project(test CUDA)
set(CMAKE_CUDA_STANDARD 20)
add_executable(test1 print_index_demo1.cu)
输出gpu信息
#include