Java内存模型-jsr133规范介绍
原文地址:http://www.cnblogs.com/aigongsi/archive/2012/04/26/2470296.html;
近期在看《深入理解Java虚拟机:JVM高级特性与最佳实践》讲到了线程相关的细节知识,里面讲述了关于java内存模型,也就是jsr 133定义的规范。
系统的看了jsr 133规范的前面几个章节的内容,认为受益匪浅。废话不说,简要的介绍一下java内存规范。
什么是内存规范
在jsr-133中是这么定义的
A memory model describes, given a program and an execution trace of that program, whether
the execution trace is a legal execution of the program. For the Java programming language, the
memory model works by examining each read in an execution trace and checking that the write
observed by that read is valid according to certain rules.
也就是说一个内存模型描写叙述了一个给定的程序和和它的运行路径是否一个合法的运行路径。对于java序言来说,内存模型通过考察在程序运行路径中每个读操作,依据特定的规则,检查写操作相应的读操作能否是有效的。
java内存模型仅仅是定义了一个规范,详细的实现能够是依据实际情况自由实现的。可是实现要满足java内存模型定义的规范。
处理器和内存的交互
这个要感谢硅工业的发展,导致眼下处理器的性能越来越强大。眼下市场上基本上都是多核处理器。怎样利用多核处理器运行程序的优势,使得程序性能得到极大的提升,是眼下来说最重要的。
眼下全部的运算都是处理器来运行的,我们在大学的时候就学习过一个基本概念 程序 = 数据 + 算法 ,那么处理器负责计算,数据从哪里获取了?
数据能够存放在处理器寄存器里面(眼下x86处理都是基于寄存器架构的),处理器缓存里面,内存,磁盘,光驱等。处理器訪问这些数据的速度从快到慢依次为:寄存器,处理器缓存,内存,磁盘,光驱。为了加快程序运行速度,数据离处理器越近越好。可是寄存器,处理器缓存都是处理器私有数据,仅仅有内存,磁盘,光驱才是才是全部处理器都能够訪问的全局数据(磁盘和光驱我们这里不讨论,仅仅讨论内存)假设程序是多线程的,那么不同的线程可能分配到不同的处理器来运行,这些处理器须要把数据从主内存载入到处理器缓存和寄存器里面才干够运行(这个大学操作系统概念里面有介绍),数据运行完毕之后,在把运行结果同步到主内存。假设这些数据是全部线程共享的,那么就会发生同步问题。处理器须要解决何时同步主内存数据,以及处理运行结果何时同步到主内存,由于同一个处理器可能会先把数据放在处理器缓存里面,以便程序兴许继续对数据进行操作。所以对于内存数据,由于多处理器的情况,会变的非常复杂。以下是一个样例:
初始值 a = b = 0
process1 process2
1:load a 5:load b
2:write a:2 6:add b:1
3:load b 7: load a
4:write b:1 8:write a:1
如果处理器1先载入内存变量a,写入a的值为2,然后载入b,写入b的值为1,同一时候 处理2先载入b,运行b+1,那么b在处理器2的结果可能是1 可能是3。由于在load b之前,不知道处理器1是否已经吧b写会到主内存。对于a来说,如果处理器1后于处理器2把a写会到主内存,那么a的值则为2。
而内存模型就是规定了一个规则,处理器怎样同主内存同步数据的一个规则。
内存模型介绍
在介绍java内存模型之前,我们先看看两个内存模型
Sequential Consistency Memory Model:连续一致性模型。这个模型定义了程序运行的顺序和代码运行的顺序是一致的。也就是说 假设两个线程,一个线程T1对共享变量A进行写操作,另外一个线程T2对A进行读操作。假设线程T1在时间上先于T2运行,那么T2就能够看见T1改动之后的值。
这个内存模型比較简单,也比較直观,比較符合现实世界的逻辑。可是这个模型定义比較严格,在多处理器并发运行程序的时候,会严重的影响程序的性能。由于每次对共享变量的改动都要立马同步会主内存,不能把变量保存到处理器寄存器里面或者处理器缓存里面。导致频繁的读写内存影响性能。
Happens-Before Memory Model : 先行发生模型。
维基百科介绍:
In computer science, the happened-before relation (denoted: ) is a relation between the result of two events, such that if one event should happen before another event, the result must reflect that. Even if those events are in reality executed out of order (usually to optimize program flow). This involves ordering events based on the potential causal relationship of pairs of events in a concurrent system, especially asynchronous distributed systems. It was formulated by Leslie Lamport.[1] In Java specifically, a happens-before relationship is a guarantee that memory written to by statement A is visible to statement B, that is, that statement A completes its write before statement B starts its read.[1]

The processes that make up a distributed system have no knowledge of the happened-before relation unless they use a logical clock, like a Lamport clock or a vector clock. This allows to design algorithms for mutual exclusion and tasks like debugging or optimising distributed systems.
这个模型理解起来就比較困难。先介绍一个现行发生关系 (Happens-Before Relationship)
假设有两个操作A和B存在A Happens-Before B,那么操作A对变量的改动对操作B来说是可见的。这个现行并非代码运行时间上的先后关系,而是保证运行结果是顺序的。看以下样例来说明现行发生
A,B为共享变量,r1,r2为局部变量
初始 A=B=0
Thread1 | Thread2
1: r2=A | 3: r1=B
2: B=2 | 4: A=2
那我们先看看先行发生关系的规则
- 1 在同一个线程里面,依照代码运行的顺序(也就是代码语义的顺序),前一个操作先于后面一个操作发生
- 2 对一个monitor对象的解锁操作先于兴许对同一个monitor对象的锁操作
- 3 对volatile字段的写操作先于后面的对此字段的读操作
- 4 对线程的start操作(调用线程对象的start()方法)先于这个线程的其它不论什么操作
- 5 一个线程中全部的操作先于其它不论什么线程在此线程上调用 join()方法
- 6 假设A操作优先于B,B操作优先于C,那么A操作优先于C
解释一下以上几个先行发生规则的含义
规则1应该比較好理解,由于比較适合人正常的思维。比方在同一个线程t里面,代码的顺序例如以下:
thread1
共享变量A、B
局部变量r1、r2
代码顺序
1: A =1
2: r1 = A
3: B = 2
4: r2 = B
运行结果 就是 A=1 ,B=2 ,r1=1 ,r2=2
再看规则2,以下是jsr133的样例
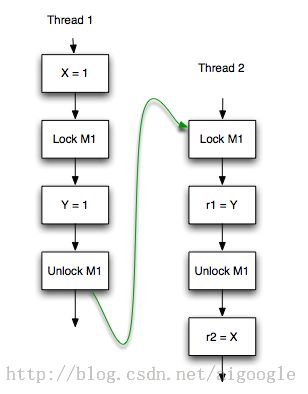
依照规则2,因为unlock操作先于发生于lock操作,所以X=1对线程2里面就是可见的,所以r2 = 1

在分析下面,看这个样例,因为unlock操作先于lock操作,所以线程x=1对于线程2不一定是可见(不一定是现行发生的),所以r2的值不一定是1,有可能是x赋值为1之前的那个状态值(如果x初始值为0,那么此时r2的值可能为0)
对于规则3,我们能够略微改动一下我们说明的第一个样例
A,B为共享变量,而且B是valotile类型的 r1,r2为局部变量 初始 A=B=0 Thread1 | Thread2 1: r2=A | 3: r1=B 2: B=2 | 4: A=2 那么r1 = 2, r2可能为0或者2
由于对于volatile类型的变量B,线程1对B的更新立即线程2就是可见的,所以r1的值就是确定的。由于A是非valotile类型的,所以值不确定。
规则4,5,6这里就不解释了,知道规则就能够了。
能够从以上的看出,先行发生的规则有非常大的灵活性,编译器能够对指令进行又一次排序,以便满足处理器性能的须要。仅仅要又一次排序之后的结果,在单一线程里面运行结果是可见的(也就是在同一个线程里面满足先行发生原则1就能够了)。
java内存模型是建立在先行发生的内存模型之上的,而且再此基础上,增强了一些。由于现行发生是一个弱约束的内存模型,在多线程竞争訪问共享数据的时候,会导致不可预期的结果。有一些是java内存模型能够接受的,有一些是java内存模型不能够接受的。具体细节这里面就不具体说明了。这里仅仅说明关于java新的内存模型重要点。
final字段的语义
在java里面,假设一个类定义了一个final属性,那么这个属性在初始化之后就不能够在改变。一般觉得final字段是不变的。在java内存模型里面,对final有一个特殊的处理。假设一个类C定义了一个非static的final属性A,以及非static final属性B,在C的构造器里面对A,B进行初始化,假设一个线程T1创建了类C的一个对象co,同一时刻线程T2訪问co对象的A和B属性,假设t2获取到已经构造完毕的co对象,那么属性A的值是能够确定的,属性B的值可能还未初始化,
以下一段代码演示了这个情况
public class FinalVarClass {
public final int a ;
public int b = 0;
static FinalVarClass co;
public FinalVarClass(){
a = 1;
b = 1;
}
//线程1创建FinalVarClass对象 co
public static void create(){
if(co == null){
co = new FinalVarClass();
}
}
//线程2訪问co对象的a,b属性
public static void vistor(){
if(co != null){
System.out.println(co.a);//这里返回的一定是1,a一定初始化完毕
System.out.println(co.b);//这里返回的可能是0,由于b还未初始化完毕
}
}
}
volatile语义
对于volatile字段,在现行发生规则里面已经介绍过,对volatile变量的写操作先于对变量的读操作。也就是说不论什么对volatile变量的改动,都能够在其它线程里面反应出来。对于volatile变量的介绍能够參考 本人写的一篇文章 《java中volatilekeyword的含义》 里面有具体的介绍。
volatile在java新的内存规范里面还加强了新的语义。在老的内存规范里面,volatile变量与非volatile变量的顺序是能够又一次排序的。举个样例
public class VolatileClass {
int x = 0;
volatile boolean v = false;
//线程1write
public void writer() {
x = 42;
v = true;
}
//线程2 read
public void reader() {
if (v == true) {
System.out.println(x);//结果可能为0,可能为2
}
}
}
可是java新的内存模型jsr133修正了这个问题,对于volatile语义的变量,自己主动进行lock 和 unlock操作包围对变量volatile的读写操作。那么以上语句的顺序能够表示为
thread1 thread2
1 :write x=1 5:lock(m)
2 :lock(m) 6:read v
3 :write v=true 7:unlock(m)
4 :unlock 8 :if(v==true)
9: System.out.print(x)
因为unlock操作先于lock操作,所以x写操作5先于发生x的读操作9
以上仅仅是jsr规范中一些小结行的内容,因为jsr133规范定义了非常多术语以及非常多推论,上述仅仅是简单的介绍了一些比較重要的内容,详细细节能够參考jsr规范的public view :http://today.java.net/pub/a/today/2004/04/13/JSR133.html