【C++】15. 模板进阶
1. 非类型模板参数
模板参数分类类型形参与非类型形参。
类型形参即:出现在模板参数列表中,跟在class或者typename之类的参数类型名称。
非类型形参:就是用一个常量作为类(函数)模板的一个参数,在类(函数)模板中可将该参数当成常 量来使用。
namespace Ro
{
// 定义一个模板类型的静态数组
template
class array
{
public:
T& operator[](size_t index) { return _array[index]; }
const T& operator[](size_t index)const { return _array[index]; }
size_t size()const { return _size; }
bool empty()const { return 0 == _size; }
private:
T _array[N];
size_t _size;
};
} 在这里 N 就是一个非类型模板参数,是一个常量,使用的时候传多大就是多大,不会直接写死大小。
注意:
1. 浮点数、类对象以及字符串是不允许作为非类型模板参数的,不过在C++20之后可以使用浮点数作为非类型模板参数
2. 非类型的模板参数必须在编译期就能确认结果。
说到array类,那我们就来介绍一下它

说白了就是在底层封装了一个静态数组。但是呢,比静态数组要强一点,但是和vector比又显得很鸡肋
在C++中,静态数组(内置数组)和std::array类(来自STL)都是用于存储固定大小的数据集合,但它们在功能、安全性和用法上有显著区别。以下是详细对比:
1. 类型定义与声明
-
静态数组(内置数组):
直接使用原生语法声明,例如:int arr[5]; // 静态数组,大小为5 int arr2[] = {1, 2, 3}; // 自动推断大小为3 -
std::array类:
需包含头文件#include
std::array
2. 类型安全性
-
静态数组:
-
作为函数参数传递时会退化为指针(丢失大小信息),例如:
void func(int arr[]); // 实际接受的是指针,无法知道数组大小
-
容易因隐式指针转换导致未定义行为。
-
-
std::array类:-
作为对象传递时保留完整类型信息(包括大小),例如:
void func(std::array
-
类型严格匹配,避免隐式转换错误。
-
3. 访问元素
-
静态数组:
-
使用下标
arr[i]或指针算术直接访问。 -
无越界检查,越界访问可能导致未定义行为。
-
-
std::array类:-
支持下标
arr[i](不检查越界,性能与原生数组相同)。 -
提供
.at(i)方法(进行越界检查,越界时抛出std::out_of_range异常)。 -
提供便捷的成员函数:
front()、back()等。
-
4. 成员函数与功能
-
静态数组:
-
无成员函数,需手动实现常见操作(如复制、比较等)。
-
大小需通过
sizeof(arr)/sizeof(arr[0])计算(易出错)。
-
-
std::array类:-
提供丰富的成员函数:
arr.size(); // 返回元素数量(编译时常量) arr.empty(); // 检查是否为空 arr.fill(42); // 填充相同值 arr.swap(arr2); // 交换两个array的内容
-
支持迭代器:
for (auto it = arr.begin(); it != arr.end(); ++it) { ... } // 或范围for循环 for (auto& x : arr) { ... }
-
5. 赋值与复制
-
静态数组:
-
不能直接赋值,必须逐个元素复制:
int arr1[3] = {1, 2, 3}; int arr2[3]; // arr2 = arr1; // 错误! std::copy(arr1, arr1+3, arr2); // 需要手动复制
-
-
std::array类:-
支持直接赋值(深拷贝):
std::array
-
6. 作为函数返回值
-
静态数组:
-
无法直接返回,通常需返回指针或封装为结构体。
-
-
std::array类:-
可直接返回,无需额外操作:
std::array
-
7. 内存与性能
-
相同点:
-
两者均在栈上分配内存(除非显式动态分配)。
-
访问速度相同(
operator[]无额外开销)。
-
-
不同点:
-
std::array的.at()方法因边界检查有轻微性能损失,但提供安全性。
-
8. 兼容性
-
静态数组:
-
兼容C语言,适合与C代码交互。
-
-
std::array类:-
仅限C++11及以上版本,需支持STL的编译器。
-
总结对比表
| 特性 | 静态数组 | std::array类 |
|---|---|---|
| 类型安全性 | 弱(退化为指针) | 强(保留大小和类型) |
| 越界检查 | 无 | 支持(通过 .at()) |
| 成员函数 | 无 | 丰富(size(), fill(), 等) |
| 赋值操作 | 不支持直接赋值 | 支持整体赋值 |
| 迭代器支持 | 需手动处理指针 | 支持STL迭代器 |
| 作为返回值 | 需额外处理 | 直接支持 |
| 兼容性 | 兼容C | 仅限C++11+ |
使用建议
-
优先使用
std::array:
在C++11及以上环境中,推荐使用std::array,因其安全性、功能性和与现代STL的兼容性。 -
静态数组适用场景:
-
需要与C代码交互时。
-
对旧代码兼容性要求较高时。
-
2.模板的特化
2.1 概念
通常情况下,使用模板可以实现一些与类型无关的代码,但对于一些特殊类型的可能会得到一些错误的结果,需要特殊处理,比如:实现了一个专门用来进行小于比较的函数模板
// 函数模板 -- 参数匹配
template
bool Less(T left, T right)
{
return left < right;
}
int main()
{
cout << Less(1, 2) << endl; // 可以比较,结果正确
Date d1(2025, 4, 26);
Date d2(2025, 4, 27);
cout << Less(d1, d2) << endl; // 可以比较,结果正确
Date* p1 = new Date(2025, 4, 26);
Date* p2 = new Date(2025, 4, 27);
cout << Less(p1, p2) << endl; // 可以比较,结果错误
return 0;
} 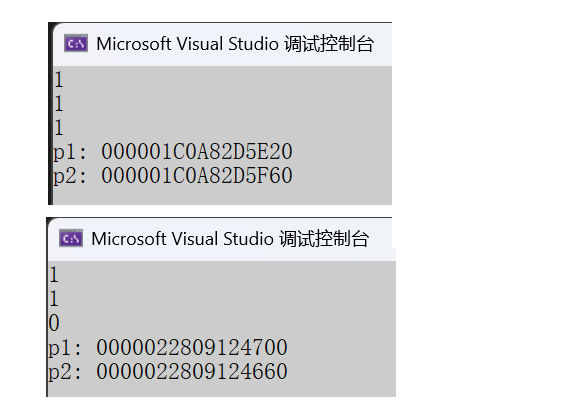
可以看到,Less绝对多数情况下都可以正常比较,但是在特殊场景下就得到错误的结果。上述示例中,p1指向的d1显然小于p2指向的d2对象,但是Less内部并没有比较p1和p2指向的对象内容,而比较的是p1和p2指针的地址,这就无法达到预期而错误。 此时,就需要对模板进行特化。即:在原模板类的基础上,针对特殊类型所进行特殊化的实现方式。模板特化中分为函数模板特化与类模板特化。
2.2 函数模板特化
函数模板的特化步骤:
1. 必须要先有一个基础的函数模板
2. 关键字template后面接一对空的尖括号<>
3. 函数名后跟一对尖括号,尖括号中指定需要特化的类型
4. 函数形参表: 必须要和模板函数的基础参数类型完全相同,如果不同编译器可能会报一些奇怪的错误
// 对Less函数模板进行特化
template<>
bool Less(Date* left, Date* right)
{
return *left < *right;
} 只要特化一下,比较的就不是地址了,编译器这里会优先调用特化版本的Less,毕竟编译器也知道省点懒,有现成的就用现成的。
注意:一般情况下如果函数模板遇到不能处理或者处理有误的类型,为了实现简单通常都是将该函数直接给出。
bool Less(Date* left, Date* right)
{
return *left < *right;
}
三者都存在时,编译器会优先走函数重载,因为函数重载是直接能用的,比函数模板特化更加现成
该种实现简单明了,代码的可读性高,容易书写,因为对于一些参数类型复杂的函数模板,特化时特别给出,因此函数模板不建议特化。
2.3 类模板特化
2.3.1 全特化
全特化即是将模板参数列表中所有的参数都确定化
template
class Data
{
public:
Data() { cout << "Data" << endl; }
private:
T1 _d1;
T2 _d2;
};
// 全特化
template<>
class Data
{
public:
Data() { cout << "Data" << endl; }
private:
int _d1;
char _d2;
};
void Test1()
{
Data d1;
Data d2;
} 
当两个类模板传的类型不同时,我们就需要全特化
2.3.2 偏特化(半特化)
偏特化又叫半特化,注意函数模板只有全特化,没有偏特化,这里偏特化只适用于类模板
偏特化:任何针对模版参数进一步进行条件限制设计的特化版本。比如对于以下模板类
template
class Data
{
public:
Data() { cout << "Data" << endl; }
private:
T1 _d1;
T2 _d2;
}; 偏特化有以下两种表现方式:
部分特化:将模板参数类表中的一部分参数特化。
// 将第二个参数特化为int
template
class Data
{
public:
Data() { cout << "Data" << endl; }
};
void Test2()
{
Data d1;
Data d2;
} 
-
全特化优先于偏特化:
如果存在全特化版本且参数完全匹配,优先选择全特化。 -
偏特化优先于通用模板:
若参数部分匹配偏特化的条件,优先选择偏特化。 -
通用模板是最后选择:
仅当无特化版本匹配时,才会使用通用模板。
参数更进一步的限制 :偏特化并不仅仅是指特化部分参数,而是针对模板参数更进一步的条件限制所设计出来的一个特化版本。
//两个参数偏特化为指针类型
template
class Data
{
public:
Data() { cout << "Data" << endl; }
private:
T1 _d1;
T2 _d2;
};
//两个参数偏特化为引用类型
template
class Data
{
public:
Data(const T1& d1, const T2& d2)
: _d1(d1)
, _d2(d2)
{
cout << "Data" << endl;
}
private:
const T1& _d1;
const T2& _d2;
};
void Test3()
{
Data d1; // 调用特化的int版本
Data d2; // 调用基础的模板
Data d3; // 调用特化的指针版本
Data d4(1, 2); // 调用特化的指针版本
} 
3 模板分离编译
3.1 什么是分离编译
一个程序(项目)由若干个源文件共同实现,而每个源文件单独编译生成目标文件,最后将所有 目标文件链接起来形成单一的可执行文件的过程称为分离编译模式。
3.2 模板的分离编译
假如有以下场景,模板的声明与定义分离开,在头文件中进行声明,源文件中完成定义:
// a.h
template
T Add(const T& left, const T& right);
// a.cpp
template
T Add(const T& left, const T& right)
{
return left + right;
}
// main.cpp
#include"a.h"
int main()
{
Add(1, 2);
Add(1.0, 2.0);
return 0;
}
分析:

3.3 解决方法
1. 将声明和定义放到一个文件 "xxx.hpp" 里面或者xxx.h其实也是可以的。推荐使用这种。
2. 模板定义的位置显式实例化。这种方法不实用,不推荐使用。
【分离编译扩展阅读】
http://blog.csdn.net/pongba/article/details/19130
4.模板的优缺点
一、模板的优点
1. 代码复用与泛化
-
泛型编程:
允许编写与类型无关的代码,适用于多种数据类型。
例如:std::vector可以存储任意类型的元素,无需为每种类型重复实现容器逻辑。 -
减少冗余:
避免为相似逻辑但不同数据类型的函数或类编写重复代码(如排序、交换等操作)。
2. 类型安全
-
编译时类型检查:
模板在实例化时会生成具体类型的代码,编译器会进行严格的类型匹配,避免运行时类型错误。
例如:std::vector和std::vector是完全不同的类型,不能隐式转换。
3. 性能优化
-
编译时多态:
通过模板展开生成具体类型的代码,无需运行时虚函数表(vtable)查找,性能接近手写代码。
例如:std::sort的模板实现比运行时多态的排序算法更快。 -
零成本抽象:
模板的高效性使得抽象(如STL容器和算法)几乎不带来额外性能开销。
4. 灵活性
-
支持元编程:
模板元编程(TMP)允许在编译时进行计算和类型推导,实现高度优化的逻辑(如编译时条件判断、循环展开等)。
例如:std::tuple的递归实现和std::enable_if的条件编译。 -
与类型系统结合:
可以结合constexpr、concepts(C++20)等特性,实现更复杂的编译时逻辑。
5. 标准库支持
-
STL的基石:
标准模板库(STL)完全基于模板构建,提供了通用的容器(vector、map)、算法(sort、find)和迭代器。
二、模板的缺点
1. 编译时间膨胀
-
代码生成开销:
每个模板实例化都会生成独立的代码,若模板被频繁用于不同类型,可能导致编译后二进制文件体积增大(代码膨胀)。
例如:std::vector和std::vector会生成两份完全不同的机器码。 -
编译速度下降:
模板的递归展开和复杂实例化逻辑会显著增加编译时间,尤其是大型项目或深度嵌套的模板。
2. 错误信息晦涩
-
难以调试的报错:
模板错误通常会在实例化时暴露,编译器报错信息冗长且难以理解,尤其是涉及嵌套模板或元编程时。
例如:一个简单的类型不匹配可能导致数十行的错误链。
3. 代码可读性降低
-
语法复杂性:
模板语法(如typename依赖、特化规则)对初学者不友好,复杂模板代码可能难以维护。
例如:templateusing EnableIf = typename std::enable_if<...>::type; -
元编程的隐式逻辑:
模板元编程依赖编译时计算,逻辑可能隐藏在类型推导和特化中,增加理解成本。
4. 跨平台兼容性挑战
-
编译器差异:
不同编译器对模板的支持可能存在差异(如旧版本编译器对C++11/14/17特性的支持不完整),导致移植性问题。
5. 运行时动态性受限
-
编译时确定类型:
模板的类型必须在编译时确定,无法实现真正的运行时多态(需结合虚函数或类型擦除技术如std::any)。
三、使用场景与替代方案
1. 适用场景
-
需要高度复用且类型无关的代码(如容器、算法)。
-
对性能要求严格的场景(如数值计算、游戏引擎)。
-
编译时逻辑优化(如条件编译、静态检查)。
2. 替代方案
-
运行时多态(虚函数):
适用于需要动态类型或接口统一的场景,但会引入运行时开销。 -
宏(Macro):
简单代码生成,但缺乏类型安全且难以调试(不推荐替代模板)。 -
C++20概念(Concepts):
增强模板的类型约束,提升错误信息的可读性。
四、总结
| 优点 | 缺点 |
|---|---|
| 代码复用与泛化 | 编译时间膨胀 |
| 类型安全 | 错误信息晦涩 |
| 高性能(编译时多态) | 代码可读性降低 |
| 灵活支持元编程 | 跨平台兼容性挑战 |
| 与STL深度集成 | 运行时动态性受限 |
五、最佳实践
-
优先使用STL:避免重复造轮子,直接使用标准库中的模板组件。
-
限制模板复杂度:避免过度使用元编程,保持代码可维护性。
-
结合C++20概念:使用
concepts约束模板参数,提升代码清晰度和错误信息质量。 -
类型萃取与SFINAE:合理使用
std::enable_if或if constexpr实现条件编译。 -
模块化设计:将模板声明与实现分离到头文件中,减少编译依赖。
模板是C++的核心特性之一,正确使用可以大幅提升代码的灵活性和效率,但需权衡其复杂性和编译成本。在性能关键型项目和泛型库开发中,模板几乎是不可替代的工具;而在需要动态多态或快速迭代的场景中,需谨慎选择其使用范围。