李沐08线性回归和基础算法优化——自学笔记
线性回归简化模型
-
输入、权重、偏差、输出
给定n维输入: x=[x1, x2,…,xn]^T
线性模型有一个n维权重和一个标量偏差: w=[w1, w2, …,wn]^T, b
输出是输入的加权和: y=w1x1+w2x2+…+wnxn+b
向量版: y= -
平方损失:比较真实值和预估值
假设y是真实值,y^是估计值
l(y,y)=0.5*(y-y)^2
- 训练数据:收集一些数据点来决定参数值(权重和偏差,过去的值)
训练数据通常越多越好,假设有n个样本
X=[x1, x2, …,xn]^T
Y=[y1, y2, …,yn]^T
- 训练损失
l(X,y,w,b)=1/2n * ||y-Xw-b||^2
- 最小化损失来学习参数:找到w和b使得损失最小
w*,b*= {argmin(w,b) l(X,y,w,b)}
- 最优解
w*=(XTX)(-1) * X^T * y
- 总结:
线性回归是n维输入的加权,外加偏差。
使用平方损失来衡量预测值和真实值的差异。
线性回归有显示解。
线性回归可以看作是单层神经网络。
基础优化方法
- 梯度下降
挑选一个随机的初始值w0
不断更新w0,使之接近最优值
沿着梯度方向将增加损失函数值(梯度,上升最快的方向,负梯度:下降最快的方向)
学习率:步长的超参数,不能太小也不能太大
- 小批量随机梯度下降
在整个训练集上算梯度太贵:一个深度神经网络模型可能需要数分钟甚至数小时
我们可以随机采样b个样本i1, i2,…,ib来近似损失
b是批量大小,另一个重要的超参数:不能太大,也不能太小
总结:
梯度下降通过不断沿着反梯度方向更新参数求解
小批量随机梯度下降是深度学习默认的求解算法
两个重要的超参数是批量大小和学习率
线性回归从零实现
从零实现整个方法:数据流水线、模型、损失函数、小批量随机梯度下降优化器
# matplotlib inline # plot.show可以在pycharm里面显示图形
import random
import torch
from d2l import torch as d2l
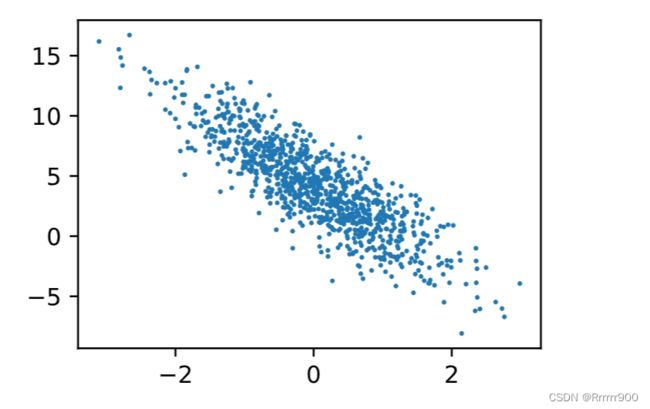
根据带有噪音的线性模型,构造一个人造数据集。我们使用线性模型参数y=Xw+b+c,w=[2,-3.4]^T、b=4.2和噪声项c
def synthetic_data(w, b, num_examples):
'''生成y=Xw+b+噪声 '''
X = torch.normal(0,1,(num_examples,len(w))) # 均值为0,标准差1的随机数,n个样本,大小是w的长度
# X是个矩阵,行数表示多少个样本,;列数表示feature
# normal是高斯分布
y = torch.matmul(X,w)+b # matmul: 矩阵乘法
y+= torch.normal(0,0.01,y.shape) # 此处是+随机噪声,形状和y一样
return X,y.reshape((-1,1)) # X和y做成列向量返回(1列)
true_w = torch.tensor([2, -3.4]) # 真实的w
true_b = 4.2 # 真实的b
features, labels=synthetic_data(true_w,true_b,1000) # 函数synthetic_data生成特征和标号
补充:
reshape(1,-1)转化成1行;reshape(2,-1)转换成两行;
reshape(-1,1)转换成1列;reshape(-1,2)转化成两列
reshape(2,8)转化成两行八列
print('features: ', features[0], '\nlabels: ',labels[0])