Kafka 与 RocketMQ 如何保证消息顺序性?代码实战与架构设计解析
前言
在分布式系统中,消息中间件是实现高并发、解耦和异步处理的重要工具。然而,在一些关键业务场景(如订单状态流转、银行账户流水处理等)中,消息的消费顺序必须与发送顺序严格一致,否则会导致业务逻辑错误。本文将深入探讨 Kafka 和 RocketMQ 是如何保证消息顺序性的,并通过代码实战和架构设计为您解析其底层机制。
一、为什么需要顺序消息?
在某些业务场景中,消息的顺序性至关重要:
- 订单状态流转:订单从“创建”到“支付”再到“发货”,每一步都依赖于前一个状态。
- 银行账户流水处理:用户的每一笔交易记录(存款、取款、转账)需要按照时间顺序处理,以确保账户余额的准确性。
如果消息乱序消费,可能会导致以下问题:
- 业务状态不一致;
- 数据重复或丢失;
- 系统异常甚至崩溃。
因此,在这些场景中,我们需要消息中间件能够保证消息的顺序性。
二、Kafka 的顺序性实现
2.1 核心机制
Kafka 通过分区(Partition)来实现消息的顺序性:
- 单个分区内有序:Kafka 只能保证同一个分区内消息的顺序性。
- 全局有序:如果需要全局有序,则必须创建仅包含一个分区的 Topic,但这会显著降低吞吐量。
2.2 UML 架构图
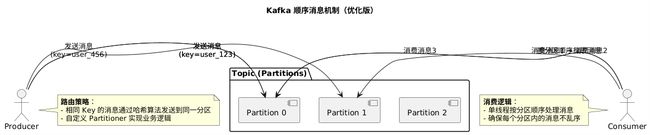
2.3 生产者代码:指定分区发送
// 配置生产者指定分区策略
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, CustomPartitioner.class);
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// 发送消息时指定Key(相同Key路由到同一分区)
String userId = "user_123";
ProducerRecord<String, String> record =
new ProducerRecord<>("bank-topic", userId, "存款操作");
producer.send(record);
// 自定义分区策略
public class CustomPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
if (key == null) {
throw new IllegalArgumentException("Key cannot be null for bank messages.");
}
return Math.abs(key.hashCode()) % partitions.size();
}
@Override
public void close() {}
@Override
public void configure(Map<String, ?> configs) {}
}
2.4 消费者代码:单线程按分区消费
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList("bank-topic"));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
for (ConsumerRecord<String, String> record : partitionRecords) {
// 按分区顺序处理消息
processTransaction(record.value());
}
consumer.commitSync(); // 手动提交偏移量,确保消息顺序性
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
consumer.close();
}
private void processTransaction(String message) {
System.out.println("Processing Transaction: " + message);
}
三、RocketMQ 的顺序消息方案
3.1 顺序消息类型
RocketMQ 提供两种顺序消息:
- 分区有序(Partition Order):同一用户 ID 的消息按顺序消费。
- 全局有序(Global Order):所有消息严格顺序(需单队列)。
3.2 UML 架构图

3.3 生产者代码:队列选择器
DefaultMQProducer producer = new DefaultMQProducer("BankProducerGroup");
producer.setNamesrvAddr("localhost:9876");
producer.start();
try {
String userId = "user_123";
Message message = new Message("BankTopic", "存款操作".getBytes());
SendResult sendResult = producer.send(message, new MessageQueueSelector() {
@Override
public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {
String userId = (String) arg;
int index = Math.abs(userId.hashCode()) % mqs.size();
return mqs.get(index);
}
}, userId); // 传入业务键userId
System.out.printf("Send Result: %s%n", sendResult);
} catch (Exception e) {
e.printStackTrace();
} finally {
producer.shutdown();
}
3.4 消费者代码:顺序监听器
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("BankConsumerGroup");
consumer.setNamesrvAddr("localhost:9876");
consumer.subscribe("BankTopic", "*");
consumer.registerMessageListener(new MessageListenerOrderly() {
@Override
public ConsumeOrderlyStatus consumeMessage(List<MessageExt> msgs, ConsumeOrderlyContext context) {
context.setAutoCommit(true); // 开启自动提交
for (MessageExt msg : msgs) {
try {
handleTransaction(msg.getBody());
} catch (Exception e) {
e.printStackTrace();
return ConsumeOrderlyStatus.SUSPEND_CURRENT_QUEUE_A_MOMENT; // 暂停当前队列消费
}
}
return ConsumeOrderlyStatus.SUCCESS;
}
});
consumer.start();
System.out.println("Consumer started...");
private void handleTransaction(byte[] body) {
System.out.println("Handling Transaction: " + new String(body));
}
四、Kafka vs RocketMQ 对比总结
| 特性 | Kafka | RocketMQ |
|---|---|---|
| 顺序保证级别 | 分区顺序 | 队列顺序/全局顺序 |
| 实现方式 | 依赖分区策略 | MessageQueueSelector + 消费锁 |
| 吞吐量影响 | 单分区时显著下降 | 多队列下仍可保持高并发 |
技术选型建议
- 如果需要严格的全局顺序,建议使用 RocketMQ 的单队列模式。
- 如果业务允许分区顺序,Kafka 和 RocketMQ 均可满足需求,可根据生态和技术栈选择。
五、结束语
通过合理设计消息路由策略和消费端处理逻辑,Kafka 和 RocketMQ 都能满足顺序性要求。理解它们的底层机制(结合 UML 架构图),才能在高并发与数据一致性之间找到最佳平衡点。希望本文对您有所帮助!如果有任何疑问,欢迎留言讨论!
Happy Coding!