【spark的集群模式搭建】spark集群之Yarn集群模式搭建(清晰明了的搭建流程)
文章目录
-
- 1、使用Anaconda部署Python
- 2、上传、解压、重命名
- 3、创建软连接(如果在Standalone模式中创建有就删除)
- 4、配置spark环境变量
- 5、修改spark-env.sh配置文件
- 6、修改spark-defaults.conf 配置文件
- 7、修改log4j.properties配置文件
- 8、上传spark jar包
- 9、修改yarn-site.xml
- 10、分发
- 11、启动
搭建Standalone模式 或者 将Standalone模式换成Yarn模式的小伙伴可以参考:
【spark的集群模式搭建】Standalone集群模式的搭建(简单明了的安装教程)
spark 和 Anaconda 资源下载链接:
spark-3.1.2 和 Anaconda3 的安装包下载
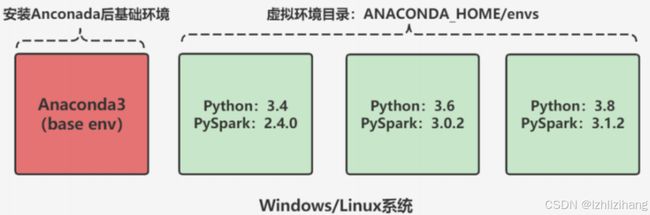
1、使用Anaconda部署Python
使用anaconda的好处:具有资源环境隔离功能,方便基于不同版本不同环境进行测试开发
# 上传
cd /opt/modules
# 同步给其他两个节点
xsync.sh /opt/modules/Anaconda3-2021.05-Linux-x86_64.sh
# 以下操作在三个节点都需要进行
# 添加执行权限
chmod u+x Anaconda3-2021.05-Linux-x86_64.sh
# 执行
./Anaconda3-2021.05-Linux-x86_64.sh
# 过程
#第一次:【直接回车,然后按q】
Please, press ENTER to continue
>>>
#第二次:【输入yes】
Do you accept the license terms? [yes|no]
[no] >>> yes
#第三次:【输入解压路径:/opt/installs/anaconda3】
[/root/anaconda3] >>> /opt/installs/anaconda3
#第四次:【输入yes,是否在用户的.bashrc文件中初始化
Anaconda3的相关内容】
Do you wish the installer to initialize Anaconda3
by running conda init? [yes|no]
[no] >>> yes
# 配置环境变量
vi /etc/profile
# 添加以下内容
# Anaconda Home
export ANACONDA_HOME=/opt/installs/anaconda3
export PATH=$PATH:$ANACONDA_HOME/bin
# 刷新环境变量
source /etc/profile
# 创建python3的软连接
ln -s /opt/installs/anaconda3/bin/python3 /usr/bin/python3
# 验证
echo $ANACONDA_HOME
2、上传、解压、重命名
# 上传、解压、重命名
cd /opt/modules/
tar -zxf spark-3.1.2-bin-hadoop3.2.tgz -C /opt/installs
cd /opt/installs
mv spark-3.1.2-bin-hadoop3.2 spark-yarn
3、创建软连接(如果在Standalone模式中创建有就删除)
# 创建软连接(如果在Standalone模式中创建有就删除)
rm -rf /opt/installs/spark
ln -s /opt/installs/spark-yarn /opt/installs/spark
4、配置spark环境变量
export SPARK_HOME=/opt/installs/spark
export PATH=$SPARK_HOME/bin:$PATH
5、修改spark-env.sh配置文件
cd /opt/installs/spark/conf
mv spark-env.sh.template spark-env.sh
vim /opt/installs/spark/conf/spark-env.sh
# 添加如下内容
export JAVA_HOME=/opt/installs/jdk
export HADOOP_CONF_DIR=/opt/installs/hadoop/etc/hadoop
export YARN_CONF_DIR=/opt/installs/hadoop/etc/hadoop
## 历史日志服务器
export SPARK_DAEMON_MEMORY=1g
export SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node01:9820/spark/eventLogs/ -Dspark.history.fs.cleaner.enabled=true"
6、修改spark-defaults.conf 配置文件
cd /opt/installs/spark/conf
mv spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
## 添加内容:
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node01:9820/spark/eventLogs
spark.eventLog.compress true
spark.yarn.historyServer.address node01:18080
spark.yarn.jars hdfs://node01:9820/spark/jars/*
7、修改log4j.properties配置文件
# 重命名
mv log4j.properties.template log4j.properties
# 修改级别为WARN,打印日志少一点。
# 19行:修改日志级别为WARN
log4j.rootCategory=WARN, console
8、上传spark jar包
#因为YARN中运行Spark,需要用到Spark的一些类和方法
#如果不上传到HDFS,每次运行YARN都要上传一次,比较慢
#所以自己手动上传一次,以后每次YARN直接读取即可
hdfs dfs -mkdir -p /spark/jars/
hdfs dfs -put /opt/installs/spark/jars/* /spark/jars/
9、修改yarn-site.xml
cd /opt/installs/hadoop/etc/hadoop
检查以下内置少什么,就配什么。
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 历史日志在HDFS保存的时间,单位是秒 -->
<!-- 默认的是-1,表示永久保存 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://bigdata01:19888/jobhistory/logs</value>
</property>
<!-- 缺少以下这些 -->
<!-- 关闭yarn内存检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
10、分发
分发脚本编写可以参考文章:
大数据集群搭建以及使用过程中几个实用的shell脚本
xsync.sh yarn-site.xml
xsync.sh /opt/installs/spark-yarn
# 软链接也分发一下:
xsync.sh /opt/installs/spark
11、启动
# 启动yarn
start-yarn.sh
# 启动MR的JobHistoryServer:19888
mapred --daemon start historyserver
# 启动Spark的HistoryServer:18080
/opt/installs/spark/sbin/start-history-server.sh