网络爬虫初级实践
第一次做爬虫,记录一下。
(一)显示影片基本信息
访问豆瓣电影Top250(豆瓣电影 Top 250),获取每部电影的中文片名、排名、评分及其对应的链接,按照“排名-中文片名-评分-链接”的格式显示在屏幕上。
import requests
from bs4 import BeautifulSoup
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.245.60"
}#需要改成自己的
url='https://movie.douban.com/top250?start=0'
def get_info(url):# 发送HTTP请求,并获取响应内容
response = requests.get(url, headers=headers)
# 使用BeautifulSoup解析HTML内容
soup = BeautifulSoup(response.text, 'html.parser')
# 找到页面中所有class属性为item的div标签
item_list = soup.find_all('div', attrs={"class": "item"})
results=[]
for item in item_list:
# 获取排行
rank = item.find('div', attrs={'class': 'pic'}).find('em').text
# 获取电影名称
title = item.find('div', attrs={'class': 'hd'}).find('span', {'class': 'title'}).text
# 获取评分
rating_num = item.find('div', {'class': 'star'}).find('span', {'class': 'rating_num'}).text
# 获取连接
link = item.find('div', {'class': 'hd'}).find('a')['href']
print(f'{rank}-{title}-{rating_num}-{link}(二)存储影片详细信息
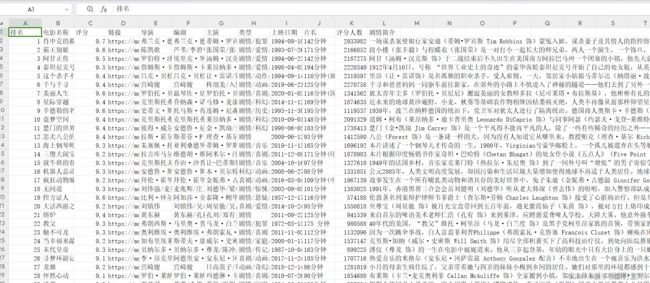
访问豆瓣电影Top250(豆瓣电影 Top 250),在问题1的基础上,获取每部电影的导演、编剧、主演、类型、上映时间、片长、评分人数以及剧情简
介等信息,并将获取到的信息保存至本地文件中。
直接在原来的代码上修改
import time
import csv
import requests
from bs4 import BeautifulSoup
import re
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.245.60"
}#需要改成自己的
def get_info(url):# 发送HTTP请求,并获取响应内容
response = requests.get(url, headers=headers)
# 使用BeautifulSoup解析HTML内容
soup = BeautifulSoup(response.text, 'html.parser')
# 找到页面中所有class属性为item的div标签
item_list = soup.find_all('div', attrs={"class": "item"})
results=[]
for item in item_list:
# 获取排行
rank = item.find('div', attrs={'class': 'pic'}).find('em').text
# 获取电影名称
title = item.find('div', attrs={'class': 'hd'}).find('span', {'class': 'title'}).text
# 获取评分
rating_num = item.find('div', {'class': 'star'}).find('span', {'class': 'rating_num'}).text
# 获取连接
link = item.find('div', {'class': 'hd'}).find('a')['href']
# 解析电影详细页面
detail_response=requests.get(link,headers=headers)
detail_soup=BeautifulSoup(detail_response.content,'html.parser')
# 获取电影详细信息的区域
info_block = detail_soup.find('div', {'id': 'info'})
if info_block:
# 获取电影信息的文本内容
info_text = info_block.get_text('\n', strip=True)
# 初始化各个电影详细信息变量
cast = ''
genre = ''
duration = ''
votes = ''
summary = ''
director_span = info_block.find('span', text='导演')
if director_span:
director_links = director_span.parent.find_all('a')
directors = [link.text.strip() for link in director_links]
director = '/'.join(directors)
else:
director = ''
# 提取编剧信息
writer_span = info_block.find('span', text='编剧')
if writer_span:
writer_links = writer_span.parent.find_all('a')
writers = [link.text.strip() for link in writer_links]
writer = '/'.join(writers)
else:
writer = ''
# 提取主演信息
cast_block = info_block.find('span', {'class': 'actor'})
if cast_block:
cast = cast_block.get_text(strip=True)
cast = cast[len('主演:'):] # 删除开头的"主演:"
# 提取类型信息
genre_block = detail_soup.find_all('span', {'property': 'v:genre'})
if genre_block:
genre = '/'.join([x.get_text(strip=True) for x in genre_block])
# 提取上映日期信息
release_dates = info_block.find(attrs={'property': 'v:initialReleaseDate'})['content']
# 提取片长信息
duration_block = info_block.find('span', {'property': 'v:runtime'})
if duration_block:
duration = duration_block.get_text(strip=True)
# 提取评分人数信息
votes_block = detail_soup.find('span', {'property': 'v:votes'})
if votes_block:
votes = votes_block.get_text(strip=True)
# 获取电影简介
summary_block = detail_soup.find('span', {'property': 'v:summary'})
if summary_block:
summary = summary_block.get_text(strip=True)
results.append(
[rank, title, rating_num, link, director, writer, cast, genre, release_dates, duration, votes, summary])
return results
output_file='D:\\pyCourse\\dataCollect\\movie_top250.csv'#设置成自己想存的地址
urls = ['https://movie.douban.com/top250?start={}'.format(str(i)) for i in range(0, 226, 25)]
try:
with open(output_file,'w',encoding='utf-8',newline='') as f:
# 创建csv.writer对象
writer=csv.writer(f)
column_names=['排名', '电影名称', '评分','链接', '导演', '编剧', '主演', '类型', '上映日期', '片长', '评分人数', '剧情简介']
writer.writerow(column_names)
for url in urls:
movies=get_info(url)
for movie in movies:
writer.writerow(movie)#将爬取到的内容写入表中
print('网页'+url+'已爬取')
time.sleep(0.5)
# 输出完成信息
print('电影信息已保存至文件:', output_file)
except Exception as e:
print('写入文件出错:', str(e))结果: