《零成本实现Web自动化测试--基于Selenium》 第四章 Selenium 命令
Selenium 命令,通常被称为Selenese,由一系列运行测试案例所需要的命令构成。按顺序排列这些命令就构成了测试脚本。
一. 验证颜面元素
1.Assertion或者Verification
断言会使测试案例执行失败(Fail),并终止当前案例的执行,而验证也会使测试案例执行失败(Fail),但允许测试案例继续执行。
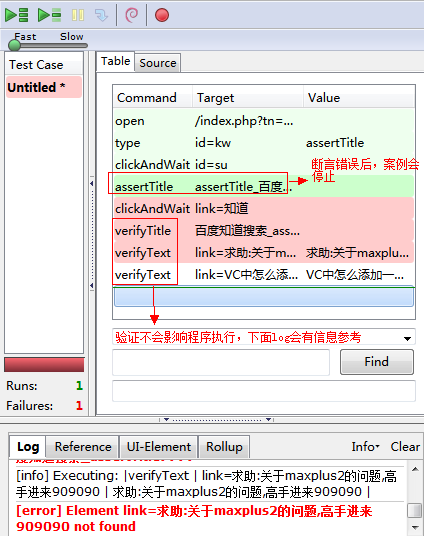
2.verifyTextPresent
verifyTextPresent 命令被用来验证特定的文本是存在于页面的某处,它携带一个参数(test pattern)用于验证。例如:
| Command | Target | Value |
| verifyTextPresent | hao123 |
这将会使得Selenium在当前测试页面上,搜寻和验证“hao123”是否存在于页面某处。(注意:一般搜寻英文没有问题,如果是中文网站,需要做一些设置)
3.verifyElementPresent
当测试待定UI元素是否存在、且不关心其内容时,可以使用这一条命令。这个命令不检查文本,仅检查HTML tag。一个常见的应用是检查图片是否存在,例如:
| Command | Target | Value |
| verifyElementPresent | //div/p/img |
4.verifyText
当文本和它的UI元素都要被测试时,请使用verifyText命令。verifyText 必须使用定位器。例如:
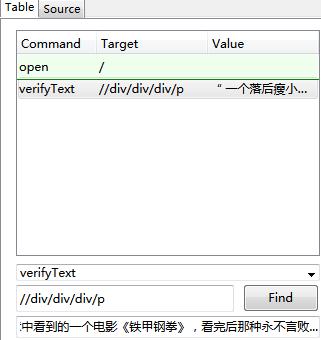
(标签P中的文本要和页面中的一致)
二. 定位页面元素
对于很多Selenium命令,target域是必需的。Target在web页面范围内识别UI元素,它使用locatorType=location的格式,咋很多情况下locatorType可以省略。下面用举例的方式来描述各种类型的locatorType。
1. 默认定位器
面临如下情况时,你可以忽略locatorType:
①定位器以“Document”开始,使用DOM定位策略;
②定位器以“//”开始,使用XPath定位策略;
③定位器没有以locatorType开头,默认使用identifier定位策略。
2. identifier(标识符)
这是最普通的一种定位方式。当不能识别为其他定位方式后,默认为identifier定位。举例如下:
<html> <body> <form id="loginForm"> <input name="username" type="text" /> <input name="password" type="password" /> <input name="continue" type="submit" value="login" /> </form> </body> </html>
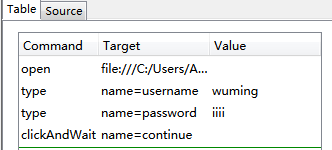
其中,identifier可以不写,上面的例子中,Target可以直接写username(只针对本例)。
3. id定位
这种定位方式比identifier定位更窄,所以精确性更高。使用上例,那么格式:id=loginForm
4. Name定位
相对于identifier来说,格式举例为:name=username,名称定位方式将会识别第一个匹配名称属性的UI元素。
5. XPath定位
XPath是一种咋XML文档中定位元素的语言。因为HTML可以被看做XML的一种实现,所以Selenium用户可以使用这种强大语言在web应用中定位元素。XPath扩展了上面介绍的id和name定位方式,提供了很多可能性,比如定位页面上的第三个多选框,请先参考下面所示的页面源代码:
<html> <body> <form id="loginForm"> <input name="username" type="text" /> <input name="password" type="password" /> <input name="continue" type="submit" value="Login" /> <input name="continue" type="button" value="Clear" /> </form> </body> </html>
使用XPath定位的主要原因是,你可能没有合适的id和name特性来定位元素。
XPath定位以“//”开始,因此xpath=标签并非是必须的。
- xpath=/html/body/form[1] --绝对路径(HTML的任何轻微改变都会导致失败);
- //form[1] -- HTML中的第一个form元素;
- xpath=//form[@id='loginForm'] --id为“loginForm”的元素;
- xpath=//form[input^@name='username'] --定位form,且它有name为"username"的input子元素;
- //input[@name='username'] --input 元素且name为'username';
- //form[@id='loginForm']/input[1] --针对id为'loginForm'的form,定位它的第一个input元素;
- //input[@name='continue'][@type='button'] -- name 为'continue'且type为“button”的input;
- //form[@id='loginForm']/input[4]--id 为'loginForm'的form,定位它的第四个input元素
此外,Firefox还有一些很有用的插件,可以帮助我们获取页面元素的XPath:
Firebug 和 XPath Checker
6. 通过link专门定位超链接
可以通过链接文字来定位超链接,请参考如下的页面代码,如果有两个链接文字相同,那么第一个匹配的将被识别出来
<html> <body> <p>Who is the first?</p> <a href=“baidu.com”>baidu</a> <a href="cnblogs.com">cnblogs</a> </body> </html>
其中:
- link=baidu 定位页面元素连接文字为baidu
- link=cnblogs定位页面元素文字为cnblogs
7. DOM定位
Document Object Model被用于描述HTML文档,可以使用JavaScript来访问。这一定位策略通过JavaScript评估页面上的元素,可以使用分级符号来简化元素定位。
因为只有DOM定位以“Document”开始,所以“dom=”标签不是必须的。举例如下:
<html> <body> <form id="loginForm"> <input name="username" type="text" /> <input name="password" type="password" /> <input name="continue" type="submit" value="Login" /> <input name="continue" type="button" value="Clear" /> </form> </body> </html>
- dom=document.getElementByID('loginForm') 定位页面元素form
- dom=document.forms['loginForm'] 定位页面元素的form
- dom=document.forms[0] 定位页面元素的form
- document.forms[0].username 定位页面元素username
- document.forms[0].elements['username'] 定位页面元素username
- document.forms[0].elements[0] 定位页面元素username
- document.forms[0].elements[3] 定位页面元素continue,而它是form的第4个元素
8. CSS定位
CSS(Cascading Style Sheets)是一种语言,它被用来描述HTML和XML文档的表现。CSS使用选择器来为页面元素绑定式样属性。这些选择器可以被Selenium用作另外的定位策略。示例如下:
<html> <body> <form id="loginForm"> <input class="required" name="username" type="text" /> <input class="required passfield" name="password" type="password" /> <input name="continue" type="submit" value="login" /> <input name="continue" type="button" value="Clear" /> </form> </body> </html>
- css=form#loginForm 定位元素的form;
- css=input[name="username"] 定位页面元素 username;
- css=input.required[type="text"] 定位页面元素,其类型为text;
- css=input.passfield 定位页面元素password;
- css=#loginForm input[type="button"] 定位页面元素,其类型是bitton;
- css=#loginForm input:nth-child(2) 定位页面元素passfield,且它为form的第二个input子元素
三. 文字范本匹配
同定位器一样,范本(patterns)也是一种经常被Selenium命令使用的参数。需要范本的命令包括verifyTextPresent、verifyTitle、verifyAlert、assertConfirmation、verifyText和verifyPrompt。就想上面提到的那样,连接定位器也可以利用范本。范本允许你使用特殊字符来描述期望值,而不是准确的说期望值。
1. globbing范本
在Selenium实现中,globbing只支持一下两种特殊符号:
- * 意思是“匹配任何东西”,比如:空、一个字符或者多个字符;
- [] (字符集)意思是“匹配任何方括号内的字符”。连接符合一被用来缩短穷举字符(必须在ASCII字符集内连续),下面举例:
①[aeiou]--匹配任何小写原因字母;
②[0-9]--匹配任何数字;
③[a-zA-Z0-9]——匹配任何字母和数字
下面拿百度首页做一个示例,命令如下:
| Command | Target | Value |
| clickAndWait | link=*About*Baidu* | |
| verifyTitle | glob:*Baidu* | |
| verifyTitle | glob:*Baidu*123 |
上面的例子中,第一,第二步是可以执行成功的,第三步,因为没有匹配的文字范本,所以IDE会报错
2. regular expressions(正则表达式)
Regular Expressions范本是Selenese支持的三种范本中功能最强大的。 regular expressions同样被很多高级编程语言所支持。此外, regular expressions范本支持JavaScript的所有特殊字符。
在Selenese中 regular expressions范本需要加上“regexp:”(大小写敏感)或者“regexpi”(大小写不敏感)。
下面举一些例子来理解 regular expressions范本怎样在Selenese命令中使用。第一个例子,使用范本“.*”,这两个字符可以翻译为“0或者更多任意字符”或者更简单的“任何东西或者空”。它等同于单字符globbing范本“*”(单星号)。
| Command | Target | Value |
| clickAndWait | link=regexp:Baidu.* | |
| verifyTitle | regexp:.*Baidu.* |
3. Exact范本
exact类型范本很少被使用。它完全不使用特殊字符。如果你需要寻找一个真实的星号字符(在globbing和regular expression范本都是特殊字符),exact范本将是一种解决办法。用法示例:
| Command | Target | Value |
| Select | //select | exact:Real * |
(正则表达式中,Value应该写成:regexp:Real \*)
四. 命令使用技巧
1. AndWait命令
命令和其AndWait变种之间的差别在于,常规命令执行后会立即执行下面的其他的操作,而AndWait变种会等待页面完全加载。
如果操作不会触发导航或者刷新的话,使用AndWait变种会导致失败。在AndWait命令超时前没有法耶页面导航或者刷新操作,将会导致Selenium报告超时错误。
2. 在Ajax应用中使用waitFor命令
在Ajax驱动的web应用中,数据从服务器取回后并不需要刷新页面。所以AndWait命令无法正常工作。
通过waitFor命令可以实现以动态周期等待页面元素,例如:waitForElementPrement 或者waitForVisible 。他们会每秒动态地周期检查期望的条件,一旦条件满足就会执行脚本中的下一条命令。
3. 执行顺序和控制流
很多测试实际上离不开控制流,,例如动态内容测试,可能会涉及到多个页面,经常需要使用到程序逻辑控制。
如果需要使用控制流,这里有三种选择
①使用Selenium-RC来运行脚本,并用Java或者PHP等高级语言来控制执行流;
②通过storeEval 命令在脚本中执行JavaScript片段;
③安装goto_sel_ide.js扩展
4.存储命令和 Selenium 变量
可以在测试脚本开头,使用Selenium变量来存储常量。Selenium变量可以被用来从命令行、其他程序、其他文件中获取数据,并传递给你的测试程序,如此就能实现数据驱动。
普通store命令是众多store命令中最基本的一个,可以被用来将常量存储到Selenium变量中,它携带两个参数,存储的文本和Selenium变量。使用变量的标准命令惯例,即仅使用字母数字来命名变量,示例如下:

一些常用的store命令如下:
①storeElementPresent
相对于verifyElementPresent,它简单地存储不二变量-“true” or “false”-,由页面元素是否存在决定;
②storeText
storeText相对于verifyText。它使用定位器来标识特定页面文本。如果文本被找到,就被存储到变量中。storeText可以从测试页面提取文本。
③storeEval
这条命令使脚本作为它的第一个参数,在Selenese中集成JavaScript,将在下一个节中介绍。
5. Javascript和Selenese参数
JavaScript可以被用做两种类型的Selenese参数,-script和non-script(通常作为表达式)。
在测试案例中创建的所有变量都被存储在一个与JavaScript关联的数组中,关联数组拥有字符串索引,而不是顺序的数字索引。包含测试案例中变量的关联数组,被命名为storeVars。当你想要访问或者操作JavaScript片段中的变量时,你必须通过storeVars['yourVariableName']来关联它
6. 使用 JavaScript 作为脚本参数
7. 使用JavaScript 作为非脚本参数
8. echo-Selenese打印函数
<6,7,8以后再做补充>