linux概念之计算机系统架构
29.openfiler
- Reliability - Openfiler supports both software and hardware RAID with monitoring and alert facilities; volume snapshot and recovery
- Availability - Openfiler supports active/passive high availability clustering, MPIO, and block level replication
- Performance - Linux 2.6 kernel supports the latest CPU, networking and storage hardware
- Scalability - filesystem scalability to 60TB+, online filesystem and volume growth support
- 可靠性,可用性,性能,扩展(伸缩)。
1.可靠性与稳定性,可扩展性,高可用,高性能
可靠性 质量系统上的用语
国外标准 MIL-STD-781D-86
国内标准 GJB 899A-2009 可靠性鉴定和验收试验
GB/T 3187-1994 可靠性、维修性术语
GB/T 5080.7-1986 设备可靠性试验恒定失效率假设下的失效率与平均无故障时间的验证试验方案
稳定性 数学或工程上的用语
稳定性 判别一系统在有限的输入是否也产生有限的输出。
Lyapunov stability (李亚普诺夫稳定性) 运动稳定性的一般问题
实现高吞吐量和低延迟高性能
可伸缩性(可扩展性)是一种对软件系统计算处理能力的设计指标
高可伸缩性代表一种弹性
正如Hibernate框架创建人所说:关系数据库是最不可扩展的。
不理解不是问题,去看看“运动稳定性的一般问题” 这份资料,看过后应该会有更深入的理解。
稳定性,一般是对于一个系统,要维持一个恒定的生产率或一系列的功能,即工艺的稳定能力,
可靠性,一般单指设备的可靠性,不牵扯工艺,当设备稳定的时候,工艺状况未必稳定,这是两个概念
包括单机与多机
 决定业务中断的持续时间。根据公式计算出的衡量HA的指标,可以得到一段时间内可以中断的时间。但可能很大量的短时间中断是可以忍受的,而少量长时间的中断却是不可忍受的。
 在统计中表明,造成非计划的宕机因素并非都是硬件问题。硬件问题只占40%,软件问题占30%,人为因素占20%,环境因素占10%。您的高可用性系统应该能尽可能地考虑到上述所有因素。
 当出现业务中断时,尽快恢复的手段。
导致计划内的停机因素有:
 周期性的备份
 软件升级
 硬件扩充或维修
 系统配置更改
 数据更改
导致计划外停机的因素有:
 硬件失败
 文件系统满错误
 内存溢出
 备份失败
 磁盘满
 供电失败
 网络失败
 应用失败
 自然灾害
 操作或管理失误
通过有针对性的设计,可以避免上述全部或部分因素带来的损失。当然,100%的高可用系统是不存在的。
创建高可用性的计算机系统
在UNIX系统上创建高可用性计算机系统,业界的通行做法,也是非常有效的做法,就是采用群集系统(Cluster),将各个主机系统通过网络或其他手段有机地组成一个群体,共同对外提供服务。创建群集系统,通过实现高可用性的软件将冗余的高可用性的硬件组件和软件组件组合起来,消除单点故障:
 消除供电的单点故障
 消除磁盘的单点故障
 消除SPU(System Process Unit)单点故障
 消除网络单点故障
 消除软件单点故障
 尽量消除单系统运行时的单点故障
对集群的研究起源于集群系统的良好的性能可扩展性(scalability)。提高CPU主频和总线带宽是最初提供计算机性能的主要手段。但是这一手段对系统性能的提供是有限的。接着人们通过增加CPU个数和内存容量来提高性能,于是出现了向量机,对称多处理机(SMP)等。但是当CPU的个数超过某一阈值,象SMP这些多处理机系统的可扩展性就变的极差。主要瓶颈在于CPU访问内存的带宽并不能随着CPU个数的增加而有效增长。与SMP相反,集群系统的性能随着CPU个数的增加几乎是线性变化的。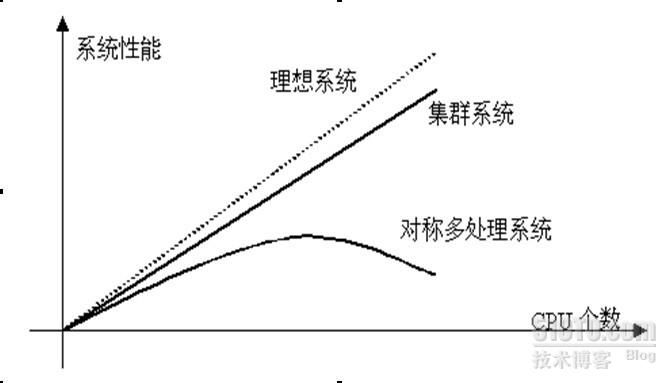
集群系统的优点并不仅在于此。下面列举了集群系统的主要优点:
高可扩展性:如上所述。
高可用性:集群中的一个节点失效,它的任务可以传递给其他节点。可以有效防止单点失效。
高性能:负载平衡集群允许系统同时接入更多的用户。
高性价比:可以采用廉价的符合工业标准的硬件构造高性能的系统。
集群类型 :
最常见的三种集群类型包括:
负载均衡集群: LB: load balancing
高可用性集群: HA:High Availability
高性能也叫科学集群:HP : High Performance
所谓集群是指一组独立的计算机系统构成的一个松耦合的多处理器系统,它们之间通过网络实现进程间的通信。应用程序可以通过网络共享内存进行消息传送,实现分布式计算机。通俗一点来说,就是让若干台计算机联合起来工作(服务),可以是并行的,也可以是做备份。
网络的负载均衡是一种动态均衡技术,常见的实现方式是通过一些工具实时地分析数据包,掌握网络中的数据流量状况,把任务合理均衡地分配出去。这种技术基于现有网络结构,提供了一种扩展服务器带宽和增加服务器吞吐量的廉价有效的方法,加强了网络数据处理能力,提高了网络的灵活性和可用性。负载均衡的核心就是“分摊压力”。
大规模集群,通常具备以下一些特点:
(1)高可靠性(HA)。
利用集群管理软件,当主服务器故障时,备份服务器能够自动接管主服务器的工作,并及时切换过去,以实现对用户的不间断服务。
(2)高性能计算(HP)。
即充分利用集群中的每一台计算机的资源,实现复杂运算的并行处理,通常用于科学计算领域,比如基因分析、化学分析等。
(3)负载平衡(LB)。
即把负载压力根据某种算法合理分配到集群中的每一台计算机上,以减轻主服务器的压力,降低对主服务器的硬件和软件要求。
当然,以上的这些特点,在某些适应场合下是需要同时具备的。常用的集群又分以下几种:
load balance cluster (负载均衡集群)
一共有四兄弟开裁缝铺,生意特别多,一个人做不下来,老是延误工期,于是四个兄弟商量:老大接订单, 三个兄弟来干活。 客户多起来之后,老大根据一定的原则(policy) 根据三兄弟手上的工作量来分派新任务.
负载均衡集群:集群中所有的节点都处于活动状态,它们分摊系统的工作负载。一般Web服务器集群、数据库集群和应用服务器集群都属于这种类型。
负载均衡集群一般用于响应网络请求的网页服务器,数据库服务器。这种集群可以在接到请求时,检查接受请求较少,不繁忙的服务器,并把请求转到这些服务器上。从检查其他服务器状态这一点上看,负载均衡和容错集群很接近,不同之处是数量上更多。
负载均衡又有DNS负载均衡(比较常用)、IP负载均衡、反向代理负载均衡等,当用户来一个请求,由负载均衡器的算法来决定由哪台机器进行处理
High availability cluster(高可用集群)
两兄弟开早餐铺,生意不大,但是每天早上7点到9点之间客户很多并且不能中断。为了保证2个小时内这个早餐铺能够保证持续提供服务,两兄弟商量几个方法:
方法一:平时老大做生意,老二这个时间段在家等候,一旦老大无法做生意了,老二就出来顶上,这个叫做 Active/Standby.(双机热备)
方法二:平时老大做生意,老二这个时候就在旁边帮工,一旦老大无法做生意,老二就马上顶上,这个叫做Active/Passive.(双机双工)
方法三:平时老大卖包子,老二也在旁边卖豆浆,老大有问题,老二就又卖包子,又卖豆浆,老二不行了,老大就又卖包子,又卖豆浆.这个叫做Active/Active (dual Active)(双机互备)
包子= application package, 互相照应叫做heartbeat, 顶替对方工作叫做 failover/takeover. 如果两个兄弟突然都瞎了聋了,不知道现在对方到底是否正在干活,都认为自己要顶对方的工作,这个叫做brain-split, 然后需要第三者,比如他们的老爹来解决问题,这个叫做tier-breaker, 或者让他们两个的媳妇过来拉走其中一个,这个叫做fency.
high computing clustering (高性能计算集群)
10个兄弟一起做手工家具生意,一个客户来找他们的老爹要求做一套非常复杂的仿古家具,一个人做也可以做,不过要做很久很久,为了1个星期就交出这一套家具,10个兄弟决定一起做。
老爹把这套家具的不同部分分开交给儿子们作,然后每个儿子都在做木制家具的加工,最后拼在一起叫货.
老爹是scheduler任务调度器,儿子们是compute node. 他们做的工作叫做作业。
从运维人员和系统架构师的角度来看,不仅需要具备丰富的操作系统配置和管理的经验,更要具备网络协议、存储等相关的知识(懂算法和底层的就更完美了)。
从开发人员和软件架构师的角度来看,需要考虑的重点又不同了。
分布式是指将不同的业务分布在不同的地方。
而集群指的是将几台服务器集中在一起,实现同一业务。
分布式中的每一个节点,都可以做集群。
而集群并不一定就是分布式的。
本文介绍并分析了目前比较流行的几种数据库高可用性的架构:Oracle Replication、Oracle Rac、Oracle 主机HA等
使用 Linux-HA 为复合应用程序实现高可用性。向复合应用程序交付高可用性具有很大的挑战性。由于复合应用程序由一些不同类型的应用程序组成,每个应用程序都具有不同的可用性需求,所以配置相当复杂。
从网络技术的发展来看,网络带宽的增长远高于处理器速度和内存访问速度的增长,如100M Ethernet、ATM、Gigabit Ethernet等不断地涌现,10Gigabit Ethernet即将就绪,在主干网上密集波分复用(DWDM)将成为宽带IP的主流技术
Lucent已经推出在一根光纤跑800Gigabit的WaveStar,OLS 800G产品。所以,我们深信越来越多的瓶颈会出现在服务器端。
很多研究显示Gigabit Ethernet在服务器上很难使得其吞吐率达到1Gb/s的原因是协议栈(TCP/IP)和操作系统的低效,以及处理器的低效,这需要对协议的处理方法、操作系统的调度和IO的处理作更深入的研究。在高速网络上,重新设计单台服务器上的网络服务程序也是个重要课题。
高可用性(HA) 这是一个公司能够全天候访问其数据并确保通过中间件向需要数据的用户提供这些数据的能力
灾难恢复(DR) 这是在灾难意外导致数据中心或服务器脱机时恢复系统的过程
数据备份
高可用性(HA)是在意外停机时保持重要业务服务的正常运行。现在,
许多业务应用程序依赖于多部分的协作来支持单个服务(例如,数据库应用程序、Web?服务器、应用程序服务器、身份服务器、目录访问服务器等)。当系统的一个部分出现故障时,其他很多部也会无法运行。HA使企业可保持达到与其客户和业务伙伴签订的服务水平协议(SLA)定的标准。但是,只有50%的公司具有HA保持计划。
对于与主数据中心分离的备份数据中心的管理
可伸缩性(Scalability),当服务的负载增长时,系统能被扩展来满足需求,且不降低服务质量。
高可用性(Availability),尽管部分硬件和软件会发生故障,整个系统的服务必须是每天24小时每星期7天可用的。
可管理性(Manageability),整个系统可能在物理上很大,但应该容易管理。
价格有效性(Cost-effectiveness),整个系统实现是经济的、易支付的。
SMP-紧耦合多处理系统
对称多处理(Symmetric Multi-Processor,简称SMP)是由多个对称的处理器、和通过总线共享的内存和I/O部件所组成的计算机系统。SMP是一种低并行度的结构,是我们通常所说的"紧耦合多处理系统",它的可扩展能力有限,但SMP的优点是单一系统映像(Single System Image),有共享的内存和I/O,易编程。
由于SMP的可扩展能力有限,SMP服务器显然不能满足高可伸缩、高可用网络服务中的负载处理能力不断增长需求。随着负载不断增长,会导致服务器不断地升级。这种服务器升级有下列不足:一是升级过程繁琐,机器切换会使服务暂时中断,并造成原有计算资源的浪费;二是越往高端的服务器,所花费的代价越大;三是 SMP服务器是单一故障点(Single Point of Failure),一旦该服务器或应用软件失效,会导致整个服务的中断。
服务器集群-松耦合多处理系统
通过高性能网络或局域网互联的服务器集群正成为实现高可伸缩的、高可用网络服务的有效结构。这种松耦合结构的服务器集群系统有下列优点:
性能
网络服务的工作负载通常是大量相互独立的任务,通过一组服务器分而治之,可以获得很高的整体性能。
性能/价格比
组成集群系统的PC服务器或RISC服务器和标准网络设备因为大规模生产降低成本,价格低,具有最高的性能/价格比。若整体性能随着结点数的增长而接近线性增加,该系统的性能/价格比接近于PC服务器。所以,这种松耦合结构比紧耦合的多处理器系统具有更好的性能/价格比。
可伸缩性
集群系统中的结点数目可以增长到几千个,乃至上万个,其伸缩性远超过单台超级计算机。
高可用性
在硬件和软件上都有冗余,通过检测软硬件的故障,将故障屏蔽,由存活结点提供服务,可实现高可用性。
当然,用服务器集群系统实现可伸缩网络服务也存在很多挑战性的工作:
透明性(Transparency)
如何高效地使得由多个独立计算机组成的松藕合的集群系统构成一个虚拟服务器;客户端应用程序与集群系统交互时,就像与一台高性能、高可用的服务器交互一样,客户端无须作任何修改。部分服务器的切入和切出不会中断服务,这对用户也是透明的。
性能(Performance)
性能要接近线性加速,这需要设计很好的软硬件的体系结构,消除系统可能存在的瓶颈。将负载较均衡地调度到各台服务器上。
高可用性(Availability)
需要设计和实现很好的系统资源和故障的监测和处理系统。当发现一个模块失败时,要这模块上提供的服务迁移到其他模块上。在理想状况下,这种迁移是即时的、自动的。
可管理性(Manageability)
要使集群系统变得易管理,就像管理一个单一映像系统一样。在理想状况下,软硬件模块的插入能做到即插即用(Plug & Play)。
可编程性(Programmability)
在集群系统上,容易开发应用程序。
一.应用架构之共享存储架构
http://bbs.chinaunix.net/thread-1644309-1-1.html
由于用户数量的不断攀升,我对访问量大的应用实现了可扩展、高可靠的集群部署(即lvs+keepalived的方式),但仍然有用户反馈访问慢的 问题。通过排查个服务器的情况,发现问题的根源在于共享存储服务器NFS。在我这个网络环境里,N个服务器通过nfs方式共享一个服务器的存储空间,使得 NFS服务器不堪重负。察看系统日志,全是nfs服务超时之类的报错。一般情况下,当nfs客户端数目较小的时候,NFS性能不会出现问题;一旦NFS客 户端数目过多,并且是那种读写都比较频繁的操作,所得到的结果就不是我们所期待的。
这种架构除了性能问题而外,还存在单点故障,一旦这个 NFS服务器发生故障,所有靠共享提供数据的应用就不再可用,尽管用rsync方式同步数据到另外一个服务器上做nfs服务的备份,但这对提高整个系统的 性能毫无帮助。基于这样一种需求,我们需要对nfs服务器进行优化或采取别的解决方案,然而优化并不能对应对日益增多的客户端的性能要求,因此唯一的选择 只能是采取别的解决方案了;通过调研,分布式文件系统是一个比较合适的选择。采用分布式文件系统后,服务器之间的数据访问不再是一对多的关系(1个NFS 服务器,多个NFS客户端),而是多对多的关系,这样一来,性能大幅提升毫无问题。
到目前为止,有数十种以上的分布式文件系统解决方案可 供选择,如lustre,hadoop,Pnfs等等。我尝试了PVFS,hadoop,moosefs这三种应用,参看了lustre、KFS等诸多技 术实施方法,最后我选择了moosefs(以下简称MFS)这种分布式文件系统来作为我的共享存储服务器。为什么要选它呢?我来说说我的一些看法:
1、 实施起来简单。MFS的安装、部署、配置相对于其他几种工具来说,要简单和容易得多。看看lustre 700多页的pdf文档,让人头昏吧。
2、 不停服务扩容。MFS框架做好后,随时增加服务器扩充容量;扩充和减少容量皆不会影响现有的服务。注:hadoop也实现了这个功能。
3、 恢复服务容易。除了MFS本身具备高可用特性外,手动恢复服务也是非常快捷的,原因参照第1条。
4、 我在实验过程中得到作者的帮助,这让我很是感激。
gfs 是google 私有的,nfs 不是分布式的。hadoop的hdfs ceph是一个 Linux PB 级分布式文件系统
Hadoop危机?替代HDFS的8个绝佳方案
用户空间文件系统(Filesystem in Userspace,简称FUSE)是操作系统中的概念,指完全在用户态实现的文件系统。目前Linux通过内核模块对此进行支持。一些文件系统如ZFS,glusterfs和lustre使用FUSE实现。
Linux用于支持用户空间文件系统的内核模块名叫FUSE,FUSE一词有时特指Linux下的用户空间文件系统。
文件系统是一个通用操作系统重要的组成部分。传统上操作系统在内核层面上对文件系统提供支持。而通常内核态的代码难以调试,生产率较低。
Linux从2.6.14版本开始通过FUSE模块支持在用户空间实现文件系统。
在 用户空间实现文件系统能够大幅提高生产率,简化了为操作系统提供新的文件系统的工作量,特别适用于各种虚拟文件系统和网络文件系统。上述ZFS和 glusterfs都属于网络文件系统。但是,在用户态实现文件系统必然会引入额外的内核态/用户态切换带来的开销,对性能会产生一定影响。
moosefs是一个开源的分布文件系统软件,可提供高效,可靠的数据存储能力.配置,维护都比较简单。
MOOSEFS对离散读写的性能提升明显。
建议底层使用xfs文件系统,支持更大的文件系统和更多的文件,这个的话rhel6已经加入支持了。
二.计算架构之HA
三.网络架构之
moosefs是一个开源的分布文件系统软件,可提供高效,可靠的数据存储能力.配置,维护都比较简单。
MOOSEFS对离散读写的性能提升明显。
建议底层使用xfs文件系统,支持更大的文件系统和更多的文件,这个的话rhel6已经加入支持了。
图片服务器架构演进 http://kb.cnblogs.com/page/516256/