关于TbSchedule任务调度管理框架的整合部署
一、前言
任务调度管理作为基础架构通常会出现于我们的业务系统中,目的是让各种任务能够按计划有序执行。比如定时给用户发送邮件、将数据表中的数据同步到另一个数据表都是一个任务,这些相对耗时的操作通过任务调度系统来异步并行执行,既能提高任务的执行效率又能保障任务执行的可靠性。
实现的方式也是多种多样,比如使用Timer进行简单调度或者使用Quartz类似的框架,本文基于淘宝开源框架TbSchedule实现,其设计目的是让批量任务或者不断变化的任务能够被动态的分配到多个主机的JVM中,在不同的线程组中并行执行,所有的任务能够被不重复,不遗漏的快速处理,目前被应用于阿里巴巴众多业务系统。
请参照http://code.taobao.org/p/tbschedule/wiki/index/,相关内容不再重复介绍,本文记录了详细的部署整合操作步骤。
二、Zookeeper部署
1、TbSchedule依赖于Hadoop Zookeeper组件,实现任务的分布式配置及各服务间的交互通信,Zookeeper以TreeNode类型进行存储,支持Cluster形式部署且保证最终数据一致性,关于ZK的资料网上比较丰富,相关概念不再重复介绍,本文以zookeeper-3.4.6为例,请从官网下载http://zookeeper.apache.org。
2、创建ZookeeperLab文件夹目录,模拟部署3台Zookeeper服务器集群,目录结构如下。

3、解压从官网下载的zookeeper-3.4.6.tar文件,并分别复制到三台ZkServer的zookeeper-3.4.6文件夹。
4、分别在三台ZkServer的data目录下创建myid文件(注意没有后缀),用于标识每台Server的ID,在Server1\data\myid文件中保存单个数字1,Server2的myid文件保存2,Server3的myid保存3。
5、创建ZkServer的配置文件,在zookeeper-3.4.6\conf文件夹目录下创建zoo.cfg,可以从示例的zoo_sample.cfg 复制重命名。因为在同一台机器模拟Cluster部署,端口号不能重复,配置文件中已经有详细的解释,修改后的配置如下,其中Server1端口号2181,Server2端口号2182,Server3端口号2183。
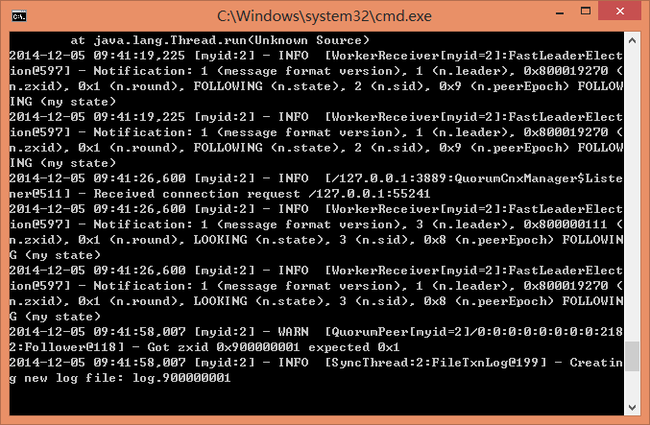
6、通过zookeeper-3.4.6\bin文件夹zkServer.bat文件启动ZKServer,由于Cluster部署需要选举Leader和Followers,所以在3个ZKServer全部启动之前会提示一个WARN,属正常现象。
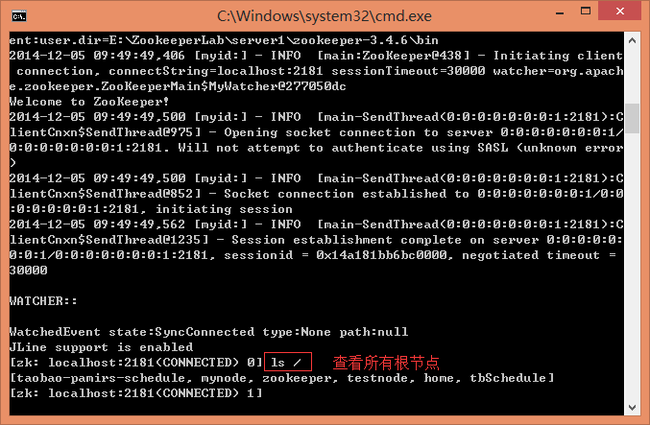
7、Zookeeper启动成功后可以通过zookeeper-3.4.6\bin文件夹的 zkCli.bat验证连接是否正常,比如创建节点“create /testnode helloworld”,查看节点“get /testnode”,连接到组群中其它ZkServer,节点数据应该是一致的。更多指令请使用help命令查看。
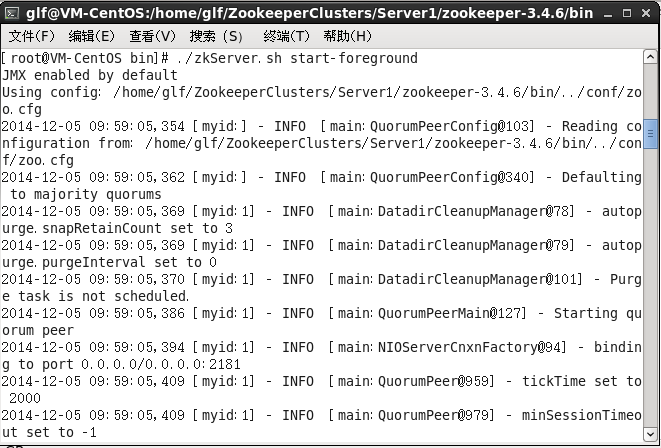
8、对于Linux环境下部署基本一致,zoo.cfg配置文件中data和datalog文件夹路径改为linux格式路径,使用“./zkServer.sh start-foreground”命令启动ZkServer,注意start启动参数不能输出异常信息。
9、至此Zookeeper的配置完毕。
三、SVN从TaoCode获取并Import TbSchedule源码(请先配置Maven环境)
四、TbSchedule控制台的部署
1、TbSchedule Console是基于web页面对调度任务配置、部署、监控的终端。
2、将源码目录下的console\ScheduleConsole.war包及depend-lib库部署到Web应用服务器,本文以Tomcat 7.0.54为例,相关步骤不再描述。
3、首次打开页面会跳转到“基础信息配置”Config.jsp页面,其中前2项为Zookeeper服务的连接配置,请正确填写前面部署的Zookeeper服务器地址和端口号,多个ZKServer可以使用逗号分隔。后3项是用于标识ZkServer中调度任务配置的根节点和节点权限,无严格要求。
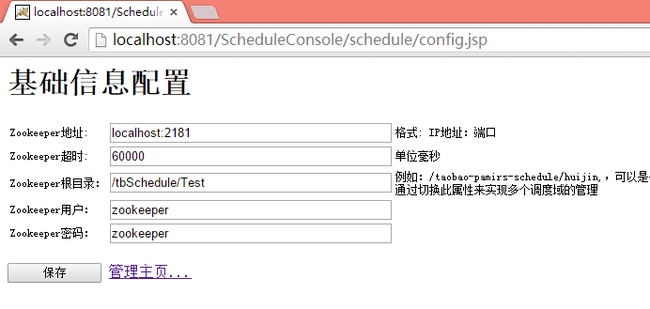
4、点击保存后,会提示 “错误信息:Zookeeper connecting ......localhost:2181”,如果ZKServer配置正确可以不用理会,直接点击“管理主页”,若不能正常跳转到Index.jsp页面请重新检查Zookeeper的配置,建议关闭防火墙。
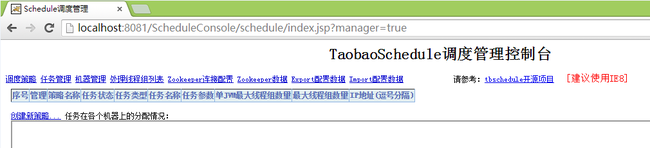
5、TbSchedule Console Web站点对应的两个地址
[监控页面] http://localhost:8081/ScheduleConsole/schedule/index.jsp
[管理页面] http://localhost:8081/ScheduleConsole/schedule/index.jsp?manager=true
如果以上地址能正常访问则TbSchedule Console的部署配置完成。
五、Task场景设计
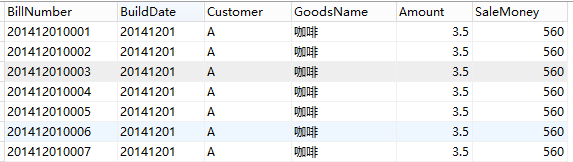
1、假设场景:任务需要将订单表tbOrder中制单日期在20141201--20141208內(共8天)的数据同步到备份tbOrder_copy 表,其中每2天分为一个任务组并行同步(每次提取500条),关于任务组的划分和TbSchedule中TaskItem的相关概念请先参考wiki,后续也会有部分解释。
2、数据环境使用MySql数据库,创建tbOrder和tbOrder_Copy数据表,结构相同,同时在tbOrder事先生成好测试数据,建议每天的数据量在1000条以上。

六、数据同步任务实现
1、创建TaskCenter Demo Project,添加对tbschedule project的依赖,并集成Spring Framework。
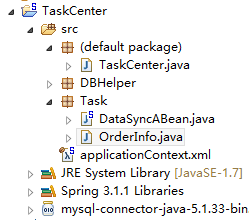
2、创建OrderInfo实体类,属性对应tbOrder表,用于映射从数据表取的数据。
3、创建DataSyncABean任务类,实现IScheduleTaskDealSingle<T>泛型接口的selectTasks和execute方法,其中selectTasks方法用于取数,execute方法用于执行selectTasks返回的Result,关于代码中任务片段的划分和TbSchedule中TaskItem的相关概念后续再解释,代码参考如下。
4、在Spring容器中注册数据同步任务Bean。
5、Main函数初始化Spring容器和TbSchedule 任务管理Factory,连接ZKServer,代码如下,也可以参照TbSchedule源码中通过Spring进行初始化TBScheduleManagerFactory 。
6、如果配置正确应该可以成功启动该TaskDeal服务。
七、在TbSchedule Console创建调度任务(请事先仔细阅读wiki中的概念解释)
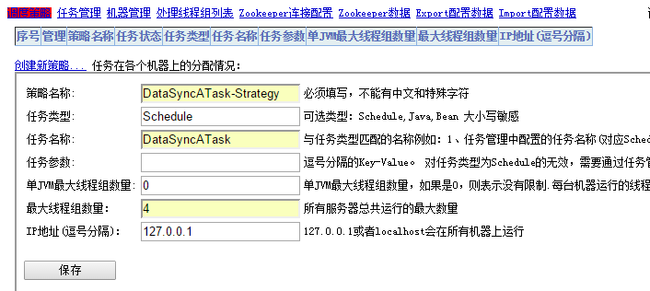
1、创建调度策略,其中“最大线程组数量”设置为4,表示在机器上的通过4个线程组并行执行数据同步任务。
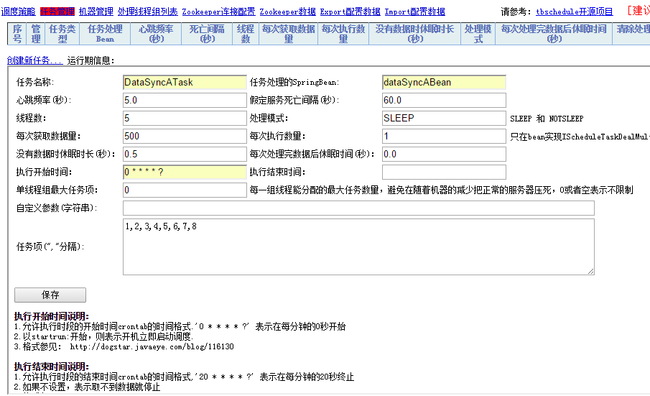
2、创建调度任务
任务名称:对应调度策略中的任务名称,标识任务和策略的关联关系;
任务处理的SpringBean:对应Demo TaskDeal服务Spring容器中的任务对象ID;
每次获取数据量:对应于bean任务类selectTasks方法参数 eachFetchDataNum;
执行开始时间:“0 * * * * ?” 表示每分钟的0秒开始,表达式同Quartz设置的Crontab格式,有工具可以生成,详细解释参照http://dogstar.iteye.com/blog/116130;
任务项:前面假设的任务场景中需要把1-8号数据按2天为1个任务组并行数据同步,所以可以把任务划分为1,2,3,4,5,6,7,8一共8个任务碎片,8个任务碎片被分配到4个线程组,那么每个线程组对应2个任务碎片,运行时任务项参数又被传递到bean任务类selectTasks方法的List<TaskItemDefine> queryCondition参数,例如第1个线程组调用selectTasks方法是queryCondition参数条件为1,2 ,第2个线程组执行参数条件为3,4,bean任务类中根据参数生成对应的BuildDate条件取数,并将结果提交到execute方法执行,从而实现并行计算。
任务项的划分:可以有非常多的分配策略和技巧,例如将一个数据表中所有数据的ID按10取模,就将数据划分成了0、1、2、3、4、5、6、7、8、9供10个任务项;将一个目录下的所有文件按文件名称的首字母(不区分大小写),就划分成了A、B、C、D、E、F、G、H、I、J、K、L、M、N、O、P、Q、R、S、T、U、V、W、X、Y、Z供26个任务项 。
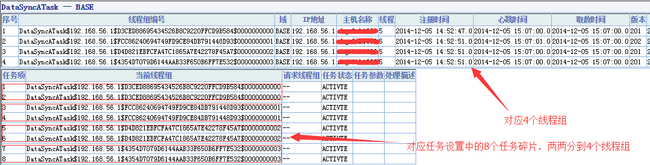
3、新增任务配置保存后,Task会按指定的时间段自动开始执行,可以从TbScheduleConsole监视到对应的线程组和任务项。
4、同时可以从任务TaskDeal服务控制台监视到Debug输出的取数SQL和 Insert语句,以及TbSchedule的Heartbeat、TaskItem Debug信息。
![]()

5、至此同步任务配置完成,并且实现了模拟场景的要求。
八、以上也只是对TbSchedule的初步认识,更多高级应用仍然在探索中,欢迎交流。