couchDB在旅行网站的一次实践
CouchDB的特点
CouchDB是用Erlang开发的面向文档的数据库系统,不是一个传统的关系数据库,而是面向文档的数据库,其数据存储方式有点类似lucent的index文件格式,CouchDB最大的意义在于它是一个面向web应用的新一代存储系统,事实上,CouchDB的口号就是:下一代的Web应用存储系统。我们可以在couchDB系统内直接写入自己的静态页面,其中数据部分用js从couchDB获取,这样做可以降低应用服务的负荷,因为数据是从用户端直接到couchDB服务器获取的。
CouchDB采用RESTFul接口,数据是JSON格式。
在我们的生活中,有很多document,比如信件,账单,笔记等,他们只是简单的信息,没有关系的需求,我们可能仅仅需要存储这些数据。这样的情况下,CouchDB应该是很好的选择。当然其他使用关系型数据库的环境,也可以使用CouchDB来解决。
兔子旅行网的couchDB实践
在说数据库选型的时候是必须要谈项目特点的。
兔子旅行网是给客户提供旅游线路、当地导游(包车)查询和预订的网站,里面包含了两个重要的数据导游信息和旅游线路信息。这两个信息的特点是一旦写入几乎不在更改,而且数据字段(嵌套)较多,数据层级比较复杂,尤其是行程安排上的数据结构非常复杂。正是这个复杂的数据结构才让我们决定使用NoSQL来存储这两块数据,其实NoSQL还适合保存日志类的数据,例如评论数据等。实际运用感觉NoSQL更易于和对象建立关系,不像关系数据库还要做映射,程序设计的层次上也简单些,尤其是在变更的情况下显得更突出。
我们的网站是用JAVA开发的,有些像订单、团期等还使用了MySQL这样的关系数据库。我们选择了jcouhDB,考虑过couchDB4j,发现couchDB4j的视图处理不是很好,因此放弃couchDB4j。
在写代码前先复制jcouchdb-1.0.1-1.jar文件到项目的lib目录下。有两个类很重要,也经常接触到,Database和BaseDocument,Database负责数据连接等基本的功能外,还有数据创建和更新等,BaseDocument提供了一个文档的基本信息,例如文档ID和文档版本等。
在本系统中共设计了两层,底层是数据结构的定义,这些类都继承了jcouhDB中的BaseDocument类,为了实现代码重用,我首先定义了MyBaseDocument,MyBaseDocument从BaseDocument类继承,其他的数据结构类都从MyBaseDocument继承。另一个层次为服务层,即提供基本服务的层,在服务层完成搜索,查询、统计等。在服务层处理了数据库的连接。
下面是一个数据结构层的定义举例:

在TourComments定义了与评论有关的参数,例如:评论日期、评论内容等,这里的参数可以是任意类型或者是其他的自定义数据结构。TourComments中包含两个方法一个是Add另一个是Unserialble,其中add是增加或者更新一个数据记录,说道Unserialble方法有点不好意,jcouchDB的例子是支持转换到对应类的,但本人一直没有成功,因此自己通过Unserialble函数实现了,这里也希望网友能提供帮助。
先看一下Add方法

首先我建立的临时视图,用于查找是否有相同的数据存在,我们的项目里规定,每个导游的手机号码是唯一索引,不能重复。没有发现重复的数据则调用createDocument方法创建新文章;若发现有重复数据,则调用updateTour函数,更新数据,其实更新数据也只调用了updateDocument方法,那为什么要写个单独的函数来更新呢?先看下面的更新函数。
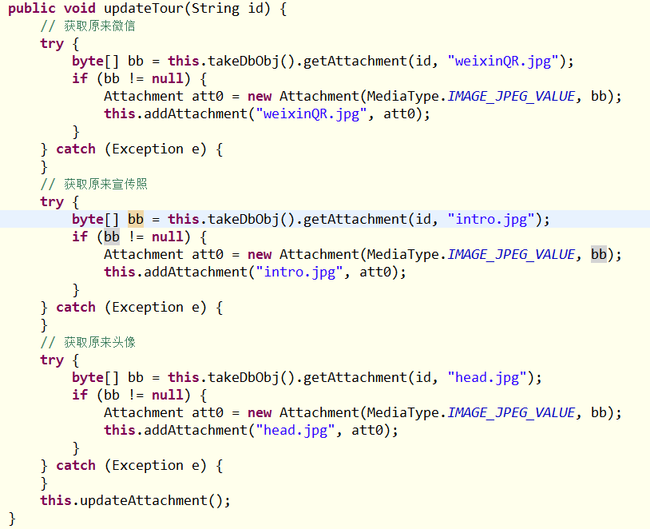
这里我们使用了文档的附件功能,每个导游的头像,宣传照和微信二维码这些图片都以附件的形式保存在文档中,这里附件只涉及到了图片,像其他的pdf文档等也可以这样使用,图片的链接地址类似http://couchDB server/tours/65ee0915c289090bd637c421a200cd5d/intro.jpg,图片的链接地址由四个部分组成,couchDB 的server地址(含端口号,可以使用nginix做重定向)、数据库名、文章key(或者叫ID)和附件名。是不是感觉管理起来很容易,拿到文章的key就获得了文章的所有内容。
在updateTour方法中实际做文档更新的是updateAttachment方法,前面的那些代码是为了获取已经上传的附件信息的,可能是jcouchDB的bug或者是我调用的方法不对,如果每次不保存已经上传的附件信息的话,相关的附件内容会随着数据更新而丢失,每次更新数据版本都会加1。这个方法看上去有点笨拙,不够优雅,目前也是不得已的办法,希望有机会找到好的解决方法,让代码看着优雅一点,这也是花了点时间才找到的解决办法。
视图的使用
永久视图
永久视图比较适合做统计分析,效率还是比较高的。使用java调用map/reduce很简单,例子代码如下:
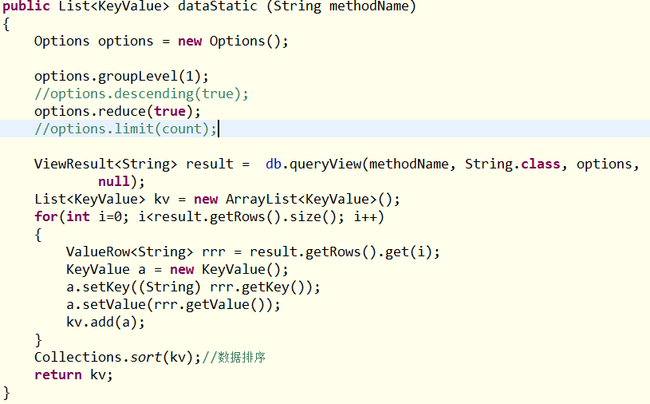
dataStatic方法要求输入视图名称,调用代码如下图:
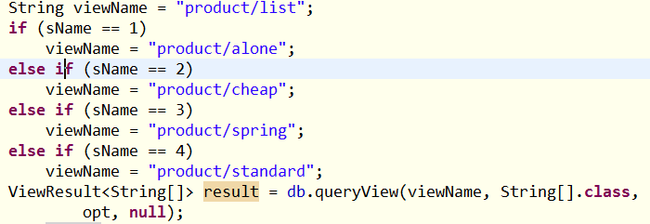
这里需要注意的是:如果是想包含reduce方法,就必须要让options的reduce属性为true,groupLevel属性为1,目前笔者还不清楚groupLevel方法值的含义,也是多次尝试出来的,groupLevel为1时,couchDB回把key值相同的结果合并。Key值就是map函数中emit函数的第一个参数。emit函数的第一个参数是有很多技巧的,在后面也会继续说。
Map/reduce举例如下:
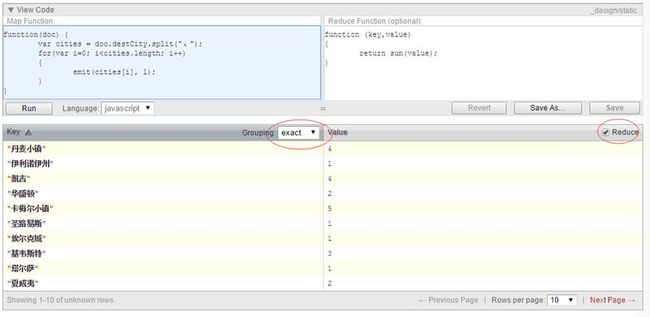
这里使用couchDB自带的futon录入map/reduce方法,其中map方法中可以包含自己写的其他函数,语法和javascript一致。
如何将参数带到永久视图中?
先看下面的map/reduce方法,这里是统计导游的评论次数的。
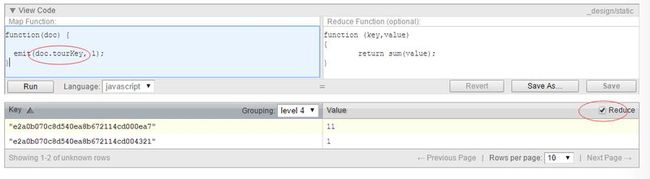
注意emit函数的第一个参数是doc.tourKey,tourKey是导游的唯一key,记住这是永久视图,下面展示如何将导游身份参数带到map函数中:
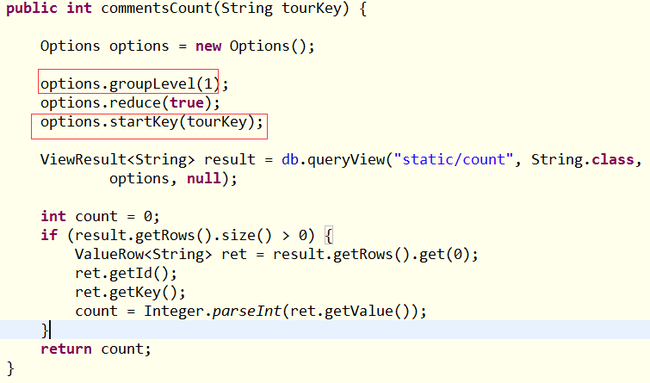
这里首先要设置options的reduce为true;设置groupLevel为1,然后将标识导游身份的key参数放到options的startKey属性中,这样就可以统计指定的导游了。
临时视图
在系统中旅游线路查询和导游查询都使用了临时试图,使用临时视图可以传入更多,更自由的参数。先看下面的代码:
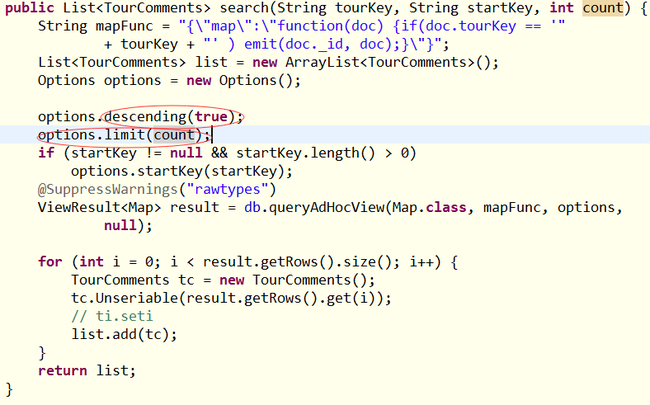
其中options.descending是排序的设置。Limit是输出结果数量的限制。这里startKey是用来实现更多的,具体的做法是每次查询的时候都比要求显示的数量多一个,保留最后一个文档的key作为更多的输入参数,最后一个不在页面显示,这里的startKey的值就是上一组的最后一个文档的key。(实现更多不像MySQL那样容易,希望couchDB以后改进一下。)
临时视图里可以编写自己的函数,提高代码的可读性和易维护性。
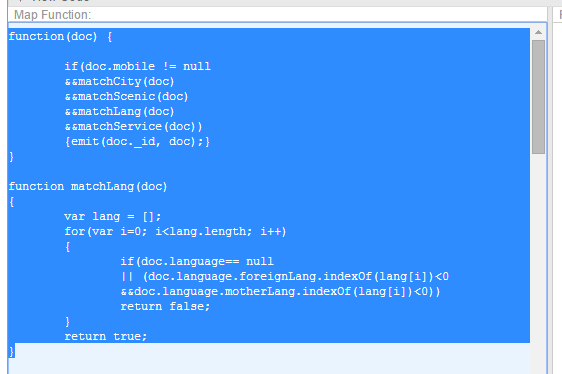
上面的代码中的matchLang函数是自定义的函数,在实际中是动态生成的函数,lang的值是根据用户的输入动态填入的。这样就可以实现多参数的传入了。
关于传参数这块,看到国外的站点有讲用show函数实现的,还没有来得及实践,毕竟couchDB的文档比较少,包括英文资料也很少。
总结
在决定是否使用couchDB前一定要仔细分析业务需求,一般满足以下几点才考虑使用couchDB:
1、数据一旦写入不再更改,或者很少更改;
2、做日志存储,文档归档比较合适;
3、统计分析比较固定,可以实现设定几个模式;
4、较少的使用动态参数;
5、不要求翻页,可以使用更多来实现翻页的效果;
不知道couchDB是否适合做图片存储,couchDB是支持分布式的,有兴趣的欢迎一起探讨实践。孔子曰:学而实习之,不亦乐乎。学习,实践,再学习,再实践……,让实践去检验学习效果。
说到调用couchDB的语言问题,虽然笔者使用的是java,但还是认为javascript更合适一些。使用java是因为这个项目一开始是用spring开发的,很多数据还要依赖MySQL实现,比如发团日期的数据,会员的登录等信息都是在MySQL中的。
上面是我的一次肤浅实践,系统中使用了较多的临时视图,下一步规划网站功能的时候希望能减少,最好是消灭临时视图的使用。欢迎大家指出其中的不足一起探讨改进。