PatentTips - Method to manage memory in a platform with virtual machines
BACKGROUND INFORMATION
Various mechanisms exist for managing memory in a virtual machine environment. A virtual machine platform typically executes an underlying layer of software called a virtual machine monitor (VMM) which hosts one to many operating system (OS) sessions, also known as virtual mactines (VMs). In existing systems, a VMM controls resources on the virtualization platform, including memory. The VMM takes the amount of physical memory on the platform, i.e. 256 MB or other total, and apportions it (divides it up) among the many. OSs that are hosted in the various VMs. For instance, if the virtual machine session supports Linux and Microsoft® Windows® running simultaneously, and has a total of 256 MB physical available memory, the VMM divides the available total in half for each session. In this example, both Windows® and Linux will each have 128 MB available. Other proportions may be predetermined for the platform. Thus, a priori decision will be made on memory allocation and resource reservation.
A problem with this method is the inability to dynamically create and delete VM sessions efficiently, regarding the use of available physical memory resources. In one example, two VM sessions grows to eight VM sessions and then back to two. In this scenario, the memory must be divided up for the maximum number of sessions, i.e., eight. Thus, when only two sessions are running, ¾ of the available memory is idle and unused. The allocation cannot be changed dynamically, or on the fly.
An operating system (OS) may distinguish between user mode and kernel mode. The OS also has a notion of privileged pages and pageable (swappable) vs. non-pageable (non-swappable) memory. In normal operation of existing systems, some memory is not available for swapping. This is often due to device drivers using specific memory for buffer space. In a virtual environment, the guest OS runs in a VM with knowledge of memory that has been allocated to the guest OS. The guest OS also has knowledge of buffer space required for various device drivers. In a virtual environment of an existing system, virtualization of VM memory is not possible by a virtual machine monitor because some pages are non-swappable. In existing systems, only the guest OS knows which pages are non-swappable and thus, only the guest OS may perform virtual memory operations. The VMMs of existing systems will not be able to accommodate memory that is not available for swapping, with respect to the guest VM OS. The VMM of existing systems allocates physical memory to the guest OS and the OS keeps track of non-swappable areas.
DETAILED DESCRIPTION
An embodiment of the present invention is a system and method relating to managing memory in a virtualization platform by a virtual machine monitor (VMM). In at least one embodiment, the present invention is intended to allow dynamic allocation of memory to one or more virtual machines running on a virtual machine platform.
In existing systems, the VMM does not know what the guest OS is doing with the memory allocated to the guest OS. Thus, the VMM cannot guarantee that non-swappable pages are not swapped out, in virtual memory schemes. Direct memory access (DMA) of memory buffers, for instance, used by device drivers, causes existing VMMs to give up control of virtual memory management to the guest OS, since the guest OS knows which memory locations are needed for the device DMA, but the VMM does not. An embodiment of the present invention addresses this problem by indicating that areas of memory requiring DMA are non-swappable.
For instance, if the guest OS has directed an input/output (I/O) controller to perform a direct memory access (DMA) from the peripheral component interconnect (PCI) bus to a selected page, then the page must be swapped in and be marked as non-swappable. The memory page needs to be resident in order to receive DMA-based transactions. In existing systems, the VMM would be unaware that this memory area needed to be swapped in. Thus, if the I/O device writes directly to this area of memory and it is being used by another VM, the contents could be corrupted.
Thus, in existing systems, physical memory may not be reallocated among VMs dynamically. On the other hand, the guest OS knows when memory is used as direct memory access (DMA) and cannot be page swapped. User mode application memory may be treated as virtual memory and be swapped in and out. This memory may be stored on a disk until a user application accesses it. Swapping unused, or not recently used, memory pages to a non-volatile storage device is well known in the art. However, the agent that controls swapping must be aware of non-swappable areas.
An embodiment of the present invention creates a second level of memory abstraction to enable the VMM to dynamically reallocate memory among the VMs while ensuring that DMA memory remains pinned to a specific guest OS and marked as non-swappable. The guest OS knows which of the allocated memory is non-swappable and the VMM knows which physical memory has been assigned to the VM (guest OS).
The VMM defines a level of abstraction of a memory partition. In other words, if two partitions of physical memory are generated from the allocated physical memory, the VMM makes it appear to each of two guest OSs that their memory allocation begins at address zero. In reality, the guest OSs will be assigned a portion of physical memory according to the defined partitions. In existing systems, the VMM uses one-stage mapping, i.e., maps the virtual address known by the guest OS to physical memory, with no swapping. In one example, there is 256 MB of physical memory partitioned to two guest VMs, each OS in a guest VM has a prescribed, or virtual, 0-128 MB address space. In one example, Windows® runs in one VM and Linux runs in a second VM. The Linux OS may actually be assigned physical memory in address range 128-256 MB, but it appears to Linux that the Linux OS is using memory in the virtual address range 0-128 MB. The VMM maps the virtual memory address to the physical memory address. In this scenario, the VMM applies a fixed offset translation from virtual address range 0-128 MB to physical address range 0-128 MB or 128-256 MB. An embodiment of the present invention enables the VMM to more fully manage virtual memory among guest VMs, including reallocation of partitions.
Referring now to the drawings, and in particular to FIG. 1, there is shown a block diagram illustrating virtualization of memory in a virtual machine with respect to physical memory, according to an embodiment of the invention. In an exemplary embodiment, physical memory 101 has physical pages of memory allocated to a first VM 103, a second VM 105, and the VMM 107. A first VM has virtual address space 111 with active pages 113 and 115. The active pages 113 and 115 are mapped to pages in the physical memory 103. A second VM has virtual memory 117 with active pages 119. The active pages 119 are mapped to pages in the physical memory 105. In an embodiment of the invention, inactive pages may be stored in a store file 121 to free up pages in physical memory for re-allocation among the VMs.
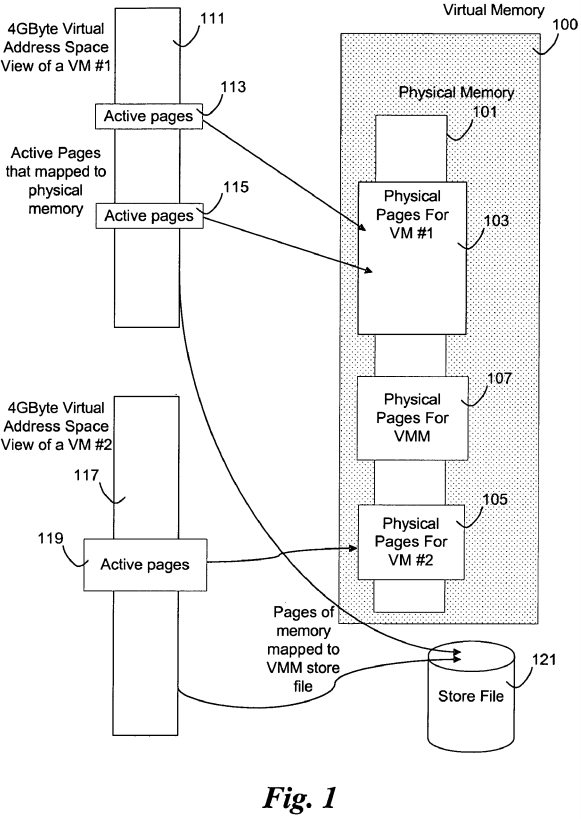
In one embodiment, the VMM performs virtualization of memory in a similar fashion to non-virtualization environments. However, DMA is handled specially. In an embodiment, DMA memory access is handled via a virtual machine call (VM_Call) method. In some embodiments, when a guest OS needs to access a DMA page, a VM_Call is made which causes an exit from the VM context and a switch to the VMM context of the platform. The VMM may then handle the access.
The VMM controls the available physical memory 103, 105, and 107, and creates a virtual range of memory 100 that may be larger than the amount of physical memory 101. When an access is attempted to a region of memory where there is not a physical backing page of memory, the VMM uses its own backing store such as a VMM store file (121).
In one example, both Linux (VM 1) and Windows® (VM 2) OSs are running as guest OSs in VMs on a virtualization platform. Suppose Linux shuts down. In existing systems, the memory 111 dedicated to Linux is wasted and remains unused. In embodiments of the disclosed system and method, Windows® may gain access to some or all of the virtual memory 111 and 117, including the memory previously dedicated to Linux 111. In one embodiment, the VMM is aware that Linux has shut down and dynamically repartitions the physical memory, allocating memory previously used by Linux to other guest OSs. In another embodiment, the newly available memory is left alone, initially. Eventually, the VMM memory management agent realizes that this memory has not been used for some time and automatically swaps the unused memory to the store file 121. The swapped memory then becomes available to be used, or reclaimed, by other VMs that are executing under the VMM control.
The VMM may perform compression and/or encryption on the swapped pages to economize on the amount of page file space needed in the store file121. In some embodiments it is desirable to encrypt the swap files to ensure that the data of one VM is inaccessible to other VMs or other systems. In an embodiment, the VMM virtualization is transparent to the OS, so the guest OS does not know that its memory is being virtualized. A guest OS may keep encryption keying materials and other secure items in memory. Thus, if that memory is virtualized, the data must be kept secure from other guest OSs. Further, the guest OS information may remain in non-volatile memory after the machine is turned off. Thus, if the swap files are encrypted, unauthorized access may be prevented.
In existing systems, the VMM does not page swap or virtualize memory. It merely performs a translation from the address used by the OS to a physical address. The VMM provides isolation and address translation of memory. Thus, in existing systems, a guest OS cannot access the memory of another guest OS. DMA, however, does not subscribe to a VMM policy. Devices will write to assigned DMA memory locations at their own whim. Thus, these areas must be protected from swapping. In one embodiment of the present invention, the VMM is to be notified of DMA areas so the OS pinning and swapping policies are not violated and to protect memory used for DMA by a guest VM OS. By keeping track of areas needed for DMA, the VMM will not swap these non-swappable regions of memory while performing resource management and virtual memory addressing.
Now referring to FIG. 2, there is shown an exemplary virtualization platform 200 and its corresponding virtual machines (VMs) and virtual machine monitor (VMM) utilizing memory virtualization, according to embodiments of the invention. In an exemplary embodiment, a virtualization platform 200 may have a system management memory (SMM) process 211 running in a special virtual machine 201. This example shows three guest VMs 203, 205, 207running three guest operating systems 213, 215, 217, respectively. In this example, guest VM 203 is running Windows® XP (213), guest VM 205 is running Windows® 95 (215), and guest VM 207 is running Linux (217) operating system (OSs).
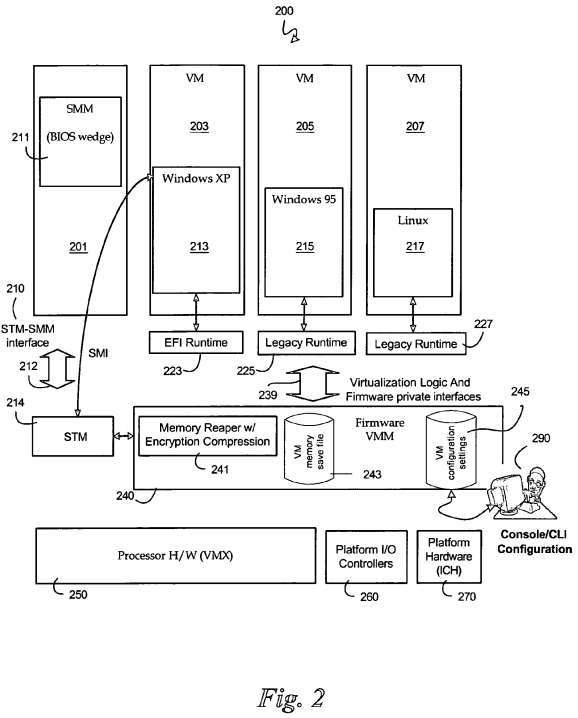
In some embodiments of platforms having a processor support for virtualization capability 250, original equipment manufacturer (OEM) SMM 211 is like a wedge of basic input output system (BIOS) code that comes from the platform. In other words, SMM is a subset of the BIOS code that comes from the platform flash memory. The SMM component is typically built into the main BIOS flash image and may be loaded into SMRAM by the main BIOS during Power-On Self Test (POST). In order to effect the isolation properties for some platform security models, the SMM 211 code runs in a VM 201 during runtime. This policy may be used for both a shrink wrapped OS and an OEM SMM. The OEM SMM may be technically a guest VM, but it may have special properties.
A system management interrupt (SMI) transfer monitor (STM-SMM) interface 210 may collaborate with the VMM 240 for the SMM 211 policies. The STM is an optional monitor for hosting the OEM SMM code. The OEM SMM may send messages to the STM regarding requests to access certain memory pages, etc. Garbage collecting, or reaping unused SMM memory, may be omitted by the SMM 211 because not much memory is typically used in the SMM process. On the other hand, since the SMM is technically a class of guest, SMM memory may be managed in the same manner as the other guests.
OEMs may choose to implement their own code in the SMI transfer monitor (STM) 214 rather than allowing this function to be a part of the VMM 240. The STM 214 may support the same policy as the main virtual machine monitor. In this example, the only guest that the STM 214 needs to control is the SMM 211. The STM executes when a SMI event 212 occurs, which may be when a signal is sent via a pin when an interrupt occurs, or another type of interprocessor interrupt.
The VMM 240 typically creates all guest VMs 203, 205, 207 other than the OEM SMM 201. The VMM 240 controls platform resources including controlling the execution of the various VMs. In virtualization platforms 250, a VM_Exit call transitions processing to the VMM 240 from VM execution. A VM_Exit may occur at various times while the processor is under VM control, and is used specifically to pass execution control to the VMM. This transfer, or context switch, may be initiated by the VM, or execute automatically like an interrupt or trap.
A variety of VMM software/firmware 240 may be utilized. Although in FIG. 2, the VMM is labeled "firmware" VMM 240, it will be apparent to one of ordinary skill in the art that embodiments of the present system and method may be implemented in software, as well as, hardware, firmware, or a combination. The VMM need not be launched from firmware, but this may be preferable by the OEM, in order for them to control the ownership of the platform and the capability. The VMM may be launched like an OS, or as an EFI driver. In some embodiments, the VMM may be launched first, from the bare hardware, before the guest VMs are loaded.
One job of the VMM is to give the guest OS the impression that the guest OS is booting from the bare hardware. The guest OSs 213, 215, 217 run in VMs 203, 205, 207, respectively, on top of the VMM 240. The VMM 240 is responsible for the mapping of, and generally, the resource management of the OSs. The virtualization platform further comprises extensible firmware interface (EFI) runtime 223 and legacy runtime 225 and 227 code and data which are also known as guest BIOSes. The guest BIOSes 223, 225, 227 look like firmware interfaces 239 such that each guest OS thinks it is communicating directly with the hardware 270. Each guest OS in a VM acts as if a dedicated BIOS or EFI (223, 225, and 227) exists as if the guest OS were the only OS executing on the platform.
The VMM may have a subset of the BIOS which is exposed to the guest OS. The VMM may expose a set of firmware services, such as the EFI Runtime Services, to the OS guest. Some services, such as the ResetSystem( ) call, may be implemented differently for use by the OS guest (e.g., fault into the VMM via a VM_Call instruction, whereas the standard BIOS ResetSystem( ) which is used by the main BIOS prior to the VMM launch may initiate an actual, hardware-based reset via programmatic access to the 0×CF9 Register in the chipset). It may appear to a guest OS running legacy BIOS that the guest OS is capable of executing an int13 or int10 system call (legacy BIOS functions) as if an actual BIOS was dedicated to the OS. The actual calls may be resolved within the VMM 240 or they may be resolved in the guest BIOS 223, 225, and 227. It appears to the guest OS that the guest OS communicates directly to the hardware via the guest OS BIOS.
In existing systems, platform firmware subscribes to a standard interface, or model, such as the PC/AT legacy BIOS and its "Intxx"—callable interface, the Extensible Firmware Interface (EFI) Specification 1.10, published Dec. 1, 2002 (available at http://developer.intel.com/technology/efi/main_specification.htm) and its CPU-neutral C-callable interface, or the OpenFirmware (Institute of Electrical and Electronics Engineers standard, 1275.2-1994 IEEE Standard for Boot (Initialization Configuration) Firmware: Bus Supplement for IEEE 1496 (SBus) (ISBN 1-55937-463-2)) and its Forth-based byte-code interface. A guest BIOS may be a subset of one of these standard-based firmware interfaces that communicates as if the BIOS were communicating directly to the actual platform firmware in order for other guest software to interact as it would with the actual platform.
In embodiments with device models within the VMM, the models may be shown as smaller boxes within the VMM (not shown). In one embodiment, the VMM 240 may be I/O agnostic and pass all of the I/O data transfers from a VM through directly to the hardware 270. In other embodiments, device models (not shown) exist within the VMM to enable platform I/O, as discussed above.
When a guest OS kernel 213, 215, and 217 performs a DMA buffer allocation, such as Windows® HAL_get_common_buffer call, it may use a device driver writer. In some embodiments, the guest OS "instruments" a small amount of the OS to make a virtual machine call (VM_Call) to notify the VMM that this piece of memory is allocated to hardware 270 and should not be swapped. For the current discussion, the term "instruments" means that the OS, such as Windows® XP, has modified a portion of the binary (or source, if desired) to replace a hardware-based call into a software VM_Call. VM_Call transitions execution to the VMM from OS-hosted VM, i.e., a context switch, such that the VMM can effect the desired behavior. The guest OS indicates that a piece of hardware, like a network controller or disk controller (not shown), needs to use this memory, so the VMM 240 should not reclaim the memory page. In some embodiments, a virtualization platform 250 includes hardware support for switching contexts and associating resources with hardware switches or interrupts, such as VM_Exit and VM_Call, which are available in some virtualization platforms available from Intel Corporation. Although it is possibly more difficult to implement, these context switches may be emulated in software, if the platform does not support hardware virtualization techniques.
A guest OS is typically in control of its device drivers. In one embodiment, the VMM passes on the device requests, without observing device operations. In other embodiments, the VMM includes device models which translate a virtualized hardware layer/interface from the OS to the actual hardware/device drivers. With virtualized hardware, the VMM may keep its own DMA area, i.e., a memory bucket for device interaction. The VMM may maintain the bucket of memory for DMA and maintain a look up table.
Another embodiment of the present invention uses a pinning method, but the guest OS must notify the VMM of non-swappable memory. For example, if a new piece of hardware is deployed and the VMM has been deployed for some period of time, the VMM may not know how to communicate with the new hardware. In this instance, the guest OS needs to notify the VMM and identify the DMA area of memory for the new hardware as non-swappable.
The device drivers may communicate with the guest OS. In this case, it is unimportant to the device drivers whether or not the OS is VMM-aware. The VMM may have a device model. Device modeling may be desirable because it would be inefficient to have to interface with every possible device driver. In some embodiments, when the device drivers operate with the guest OS, the guest OS may perform a VM_Call to initiate the DMA access. Once the VM_Call is initiated, control transfers to the VMM which performs the DMA access and may emulate the hardware with a device model.
In an embodiment, the VMM invokes the guest OS and passes a data structure, or uses another method, to inform the guest OS what memory is available to the guest OS. The VMM must satisfy any OS requests for memory. If the guest OS is told that the guest OS has access to memory in the address range between 0 and 128 MB, the VMM must make sure that the guest OS can use all memory when needed.
In some embodiments, the VMM virtualizes the hardware layer. Arbitrary pages of memory may be used for device DMA. The VMM 240 may have hardware support for the actual hardware 270 on the platform. The VMM may provide input/output (I/O) and command status registers for a prototypical piece of hardware.
The device driver corresponding to a guest OS initiates access to a virtual DMA and the VMM translates that to the real hardware and memory locations based on the prototypical model. The VMM may copy data from the actual DMA buffer to the virtual DMA buffer that is known by the guest OS.
A VM may be configurable with settings/configurations/parameters 245 that may be selected using a management console 290. The VMM is parameterized in policies. The remote console 290 may have a Command Line Interface (CLI) which enables an operator/administrator to change policies, e.g. configuration parameters 245. The platform owner typically administers the VMM 240. The guests 213, 215, 217 are simply users. The owner may have special privileges. The owner may want the best performance for one VM, or overall. An example of a desired policy is to keep Linux memory from being paged out, but to allow Windows® memory to be paged. Another possible desired policy is to select a specific key for encrypting the page files, or to select a modified least recently used (LRU) algorithm for paging.
Policies/configurations may be set using a local setup procedure or a network based setup. It will be apparent to one of ordinary skill in the art that the CLI console 290 may communicate with the VMM 240 using a variety of methods, including extensible Markup Language (XML), simple object access protocol (SOAP) and others.
In an embodiment, there may be a single processor executing a plurality of VMs. The VMM controls which VM runs at any time. In one embodiment, a round robin technique may be used. Policies regarding how to control the VM time slices may be part of the parameters configured by the CLI console.
Examples of configurable settings are: a VM save file encryption key; a policy for scheduling VMs, for instance, how long to run each VM before switching to the next one; and selection of an algorithm to be used to reap or reclaim a page of memory. In one example, the platform owner has an affinity to allow Windows® XP to have priority over Linux. The CLI console may enable the owner to specify this preference as a configuration setting.
VM memory save file 243 comprises the page file used for swapping memory pages. The save file, may be on the platform hard disk. Any non-volatile memory which is communicatively coupled with the VMM may be viable for use as the memory save file. The memory reaper with encryption/compression 241 comprises the algorithm/agent used to swap memory to the memory save file. It is the virtualized virtual memory algorithm used in this example.
Referring now to FIG. 3, there is shown a flow diagram illustrating an exemplary method for virtualizing memory in a virtual machine platform, according to an embodiment of the invention. An initialization phase 310 is shown on the left. In one embodiment, the platform is booted with a physical restart in block 301. This boot is typically a remote reset, or power on. The restart 301 is a reset of the type that will cause the platform firmware to execute its instructions. The system is then initialized in 303. This initialization includes programming the memory controller to make the dynamic random access memory (DRAM) accessible and usable, testing memory, enumerating the I/O buses, and other standard platform initialization. The VMM is then loaded in block 305. The VMM may be encapsulated in an EFI driver, or it may be loaded directly from the platform disk, flash or other storage device which is accessible in the pre-OS firmware operational environment.
In block 307 a determination is made as to whether a configuration or policy action is requested/exists. For instance, a configuration policy may be to update the memory set-point in block 309. The set-point may be that the system administrator for each VM tries to make a certain amount of memory available. The configuration may occur prior to OS boot. It may also be possible to perform some configuration modifications after OS boot.
For each OS launch as determined in block 311, an OS is launched in a VM in block 313. In the example shown in FIG. 2, Windows® XP 213 is launched in VM 203; Windows® 95 215 is launched in VM 205; and then Linux 217 is launched in VM 207. A memory map from 0 to some defined address is prepared with a resource list for each OS 203, 205, and 207. In one embodiment, a VM_Enter call may be performed for each OS to prepare a VM environment for each OS. At this point, the VMs are populated and running under the VMM.
The evaluation phase 320 is shown on the right of FIG. 3. Under normal conditions, a VM will execute in VM mode until some event causes a switch to VMM mode, or context. Until this event occurs, a VM executes at block 350. When a context switch occurs, the VMM takes control. FIG. 3 illustrates an exemplary process for virtualization of memory by a VMM, but does not attempt to show other processes which may occur upon switching context to the VMM mode. Once the context switch occurs, control passes to block 315.
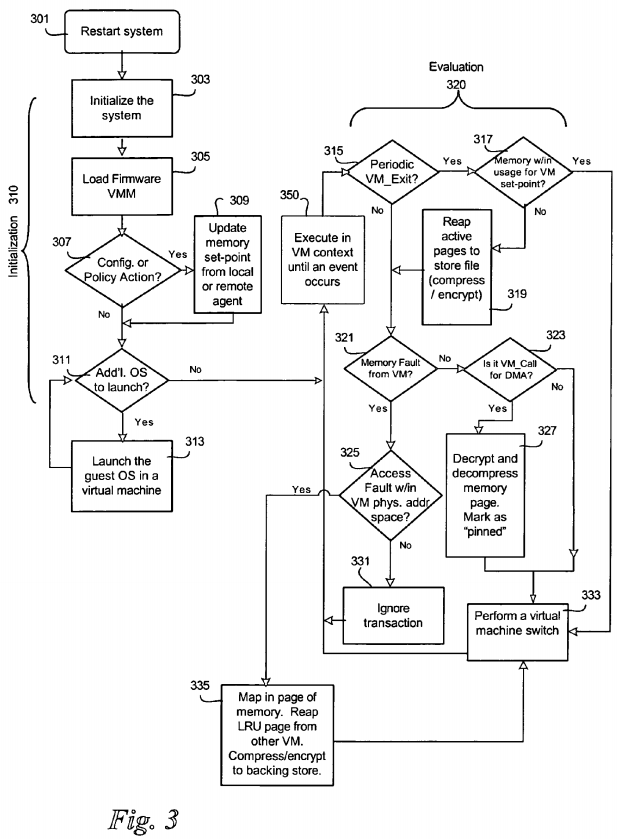
A timer may be set up to schedule a VM_Exit at a periodic specific time in order to effect automatic periodic memory swapping and reallocation. At block315, a determination is made as to whether a periodic VM_Exit is set. If so, then a check is performed to see if the memory is within the usage for a VM set-point in block 317. If so, then a virtual machine switch is performed in block 333 to switch back to the VM context, and control passes back to 350.
If memory is not within the set-point parameters, then, a VM may have too much memory allocated for the session. If the VM has too much memory, at least in comparison to the other VMs, then active pages may be reaped from the VM and stored in the store file after compression and/or encryption, in block 319.
If the context switch was not caused by a periodic VM_Exit, then there may have been a memory fault, as determined in block 321. If so, then it is then determined whether the fault is accessed within the VM physical address space in block 325. In other words, it is determined whether memory in the physical address space is accessed, but the VM does not have its own memory there—it had been swapped out. At this point, perhaps the address space access was to a memory-mapped I/O region where there are no peripherals or some other artifact that the VMM does not manage.
If memory in the physical address space was not accessed, then the transaction is ignored at block 331. If physical memory has been faulted, then it is necessary to recover memory from another VM. In this event, the memory page is mapped in block 335. In addition, the least recently used (LRU), or other preferred method, is used to reap pages from another VM. The reaped pages are compressed and encrypted and stored in the store file. A virtual machine switch is then performed in block 333 to switch the context back to the VM.
If there was not a memory fault while executing a VM and a periodic VM_Exit did not occur, as determined in block 321, then a determination is made as to whether the context switch is due to a VM_Call for direct memory access (DMA) in block 323. If so, then the memory page is decrypted and decompressed and marked as "pinned" by the VMM so it will not be swapped out, in block 327. If the context switch is not caused by a DMA, then processing continues at 333. A context switch is performed in block 333 and control is transferred back to block 350. In other words, the VMM has control in order to manage virtual memory and when this management is completed, the processor switches back to VM context.