使用 .Net Memory Profiler 诊断 .NET 应用内存泄漏(方法与实践)
做过应用诊断与优化的朋友都知道内存泄漏和带来的危害,对这种情况的分析和定位一般会比较困难,尤其在 .NET/Java 应用中,隐式的堆内存管理以及托管对象间纷繁复杂的引用关系,使分析和定位问题更加复杂。本文以我的了解,尽量说明了:
- 一种对 .NET/Java 托管内存类应用的内存泄漏分析和诊断方法;
- 使用 .Net Memory Profiler 工具对一个真实 ASP.NET 应用中存在内存泄漏问题的分析、诊断实践过程作为示例。
本文包括以下问题、不足:
- 本文以我的现有理解写成,尤其是“方法”相关的内容,每个人在不同情况下会有不同的方式;
- 不是 .Net Memory Profiler 工具的全面讲解,实践中所涉及的功能仅是为了定位这里 ASP.NET 应用中的问题。可参见 .Net Memory Profiler 文档 。
.NET/Java 托管内存类应用的内存泄漏分析和诊断方法
首先是些科普知识,理解的兄弟请自行快速跳过。
在托管内存管理中,“泄漏”意义不同与传统 Native 应用中的忘记显式释放(delete/delete[] 等)不同,当然对于非托管资源之类(如句柄等)还是需要在 Finalize (析构方法等同于 Finalize)方法中显式释放的,在托管内存管理中“泄漏”对象实例指的是,由于与 Root 对象集中的对象存在本应断开的引用关系,而让 GC 线程认为该对象还被使用,因而不能被释放,尽管其不再会被使用。决大部分情况下,由于应用(程序员)认为该对象不会存在了,而在再次使用时,又在托管堆中再次创建了该对象实例,可以想象这样的后果很严重,随着创建次数增加堆内存会爆满。(托管堆中 G3 区爆满,G2 区无法腾出空间)。
GC 判断一个对象是否可以被释放是通过从被称为 Root 对象集中的根对象开始(如 Main 函数的 args 形参、static 变量及其对象成员等),遍历出所有被其引用的对象和子对象。GC 执行时通过标记这些引用中的对象,清除未标记上的对象来完成内存释放(标记、清理算法),当然清除也可能分步(如移送 Finalize 队列等)。由于标记、清理算法的中断时间等性能考虑,托管堆会分区(代),当前 CLR 是 3 代 – G1、G2、G3。伴随 Age(GC 一次 Age 加 1)增加,对象会逐渐从 G1 移送到 G3 代中(复制、整理算法),即 G1 是新生代,都是些短期对象,G3 是老年对象的永久居留地。需要说明的是,实际上在当前版本的 .NET CLR 中有 2 个托管堆(SOH 和 LOH),其中一个叫大对象托管堆(LOH),专门用来存放大于 84, 999 Bytes 的对象。程序只能在 SOH G1 和 LOH 中分配对象空间,只有 CLR GC 线程可以在 SOH 的 G2、G3 中分配(移送)对象。
明白上面的基本道理,下面看看和托管对象实例内存泄漏的图例:
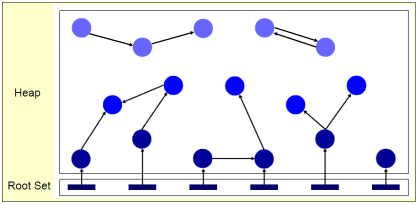
上面图中表示的意思是使用一段时间后,堆中对象与 Root 对象的引用关系,其中颜色由浅到深表示了 Age 的因素。如果此时,GC 线程执行,堆情况将如下所示:

其中所有 Unreachable 的对象实例都将被 GC 所释放,这样托管堆内存会被正确回收。但需要说明的是,如果在 Reachable 的区域中(这部分 GC 是不会释放的),有一些被引用的对象在以后不会再使用,而且应用(程序员)在下次使用时还会创建新的对象时“泄漏”就发生了。当涉及对此类对象创建操作的业务被用户反复执行后,CLR 的 G3 代托管堆段会逐渐增长,服务的死期也就不远了。
有了以上的知识,可以说对内存泄漏的结构化诊断、定位方法如下:
- 监控托管堆使用量(查看进程的内存占用量也可以),找到内存只长不降的业务,这些代码有内存泄漏的危险。这个过程我一般会使用 LoadRunner 脚本来做,毕竟小尺寸对象的泄漏需要较长的时间才能发生,靠手工操作不靠谱。这个一般不需要并发;
- 重新启动应用,让托管堆清理无关对象;
- 执行一次第1步发现的存在内存泄漏缺陷的业务;
- 使用工具将托管堆导出(dump)来,或对托管堆做一次快照(snapshot)。在 dump/ snapshot 前要做一次全面 GC(full GC),尽量把可对象释放干净,排除干扰。此时泄漏的对象已经不能 GC 掉了,会保存在托管堆中,都会被 dump/shot 出来;
- 重复步骤 3。这会再次创建上次执行时(步骤 3)泄漏的对象;
- 重复步骤 4。此时,泄漏的对象是作为本次 dump/shot 的新对象存在的,相对于步骤 4 中泄漏的同类对象而言;
- 通过对比步骤 4 和 6 两次 dump/snapshot 结果,下面就需要在茫茫对象中找出泄漏的对象/对象类型来了。实际上这个过程是相对比较困难的,需要了解应用设计,相关背景知识,了然的越详细,定位越快,结果越准、完整。做两次 dump/snapshot 的目的在于,泄漏对象将属于“新”创建对象集范围,这将有效缩小需检查的对象范围。需要说明的是,这里的“新”指的是第二个 dump/snapshot 相对于第一个 dump/snapshot 里存在的新对象;
- 可能前步骤的对象范围还是比较大,接下来可以从对象类型角度排个检查的优先级顺序:
- 检查应用命名空间中类型的对象;
- 检查框架所提供的类型的对象;检查已经执行过手动关闭/释放方法的对象。如 .NET 中的 IDisposable 接口的 Dispose 方法。因为一旦调用了这种方法,对象本应该被 GC 所释放的,它是不应该再存在的。对于此类对象,存在的原因有可能:
A.被短生命周期的对象所引用,如局部变量(包括形参变量)等,造成无法 GC。但在,在再次执行 dump/snapshot 时,它应该已经 GC 释放掉。
B.应用中设计了“池”,对象虽然被关闭,但它仍然会在池中存放,供下次使用时再打开。一般这种情况比较少见,尤其在 .NET 中,放入池中的对象很少会调用其 Dispose 方法。这方面 Java 也类似。
实际上面所说的结构化方法只是表达个意思,真实的过程会是一个逐步定位、迭代的过程,在理解其中意义的前提下,灵活使用。通过上面的一系列分析、诊断方法来定位到泄漏的对象后,就查找是它们是被哪些对象所引用,即 Root Path 中都有哪些对象,通过修改代码来切断不应存在的引用,就可以使泄漏对象进行正常的 Unreachable 状态,GC 线程也就会正确处理它们了。实际上,重点还是在分析、诊断、定位,修复方法还是很容易找到的。
解决 ASP.NET 应用内存泄漏问题 - .Net Memory Profiler 工具实践
首先要看下 .NET Memory Profiler 是什么,就不翻译了。我理解它实际就是个托管堆的 snapshot 工具,可以标记出非托管资源。显示实时堆使用图形的功能实在没大用。
.NET Memory Profiler is a tool for the .NET Common Language Runtime that allows the user to retrieve information about all instance allocations performed on the garbage collected heap (GC heap) and all instances that reside on the GC heap. The retrieved information is presented in real time, both numerically and graphically.
再说说这个 ASP.NET 应用,前两天事业部的一个 ASP.NET 应用出现了内存泄漏的情况。现象是,在一个查询业务场景中,发现查询几次之后 IIS 的 w3p 工作进程会增长几兆、十几兆、几十兆不等的内存(这和查询结果大小成正比),而且通过 perfmon 监控可以看到 w3p 的 CLR 及时执行了 GC,但托管堆使用量始终只增不减,直到服务宕掉(在 LoadRunner 测试时还有 w3p crash 的情况)。
这里就不详细说明使用 .NET Memory Profiler 工具使用细节了,相信能看到这里的朋友,对这个工具的基本使用肯定不会成问题的。下面直接说重点。
按照上面提供的方法(内存泄漏的结构化诊断、定位方法),首先我们已经找到了在在问题的业务,也能够重现它。接下来将服务重启,让 w3p 的托管堆初始干净,排除无关对象。然后执行一次有问题的业务,这里我使用的 LoadRunner Vuser 回放测试脚本。接下来就要请 .NET Memory Profiler 出马,对 w3p 进程托管堆做次 snapshot。每个快照之前 .NET Memory Profiler 会自动做一次 Full GC。再来做一次执行查询业务,然后再做snapshot。通过过两次比较可以看到如下内容:

从中可以了解到:
- 展现的所有内容是其于 3# snapshot 与 2# snapshot 两次快照的对比结果;
- .NET Memory Profiler 提供了 Types 所有照到的对象类型,Show types 可以指定显示类型的范围,包括所有、“新”对象(第二个 dump/snapshot 相对于第一个 dump/snapshot 里存在的新对象)等;Type details 每个类型的对象实例信息;Instance details 每个实例的详细信息;Call stacks/Methods 方法调用栈;Native memory 非托管内存信息;
- 另外需要注意的是 Field Sets,包括 Standard、Dispose Info、Heap Utilization,用于过滤显示的 Types 类型结果。比较有用,能够看到上面方法中提到的 Dispose 方法调用后仍然在在的对象类型有哪些,这可以缩小检查范围,下面会涉及到。
接下来就需要有针对性的逐一排查了,道先要考虑的是哪种类型的对象最有可能发生泄漏。上面的方法中提供了优先级别。我在这里是这样考虑的,因为对应用比较了解,我知道在有问题的业务页面中,有一个 static 类型的成员变量,它是 XmlDataSource 类型的对象,由于 static 所以实例不会被 GC,所以检查它所引用的有哪些对象实例就很有意义了。查看该类型的详细信息可见:
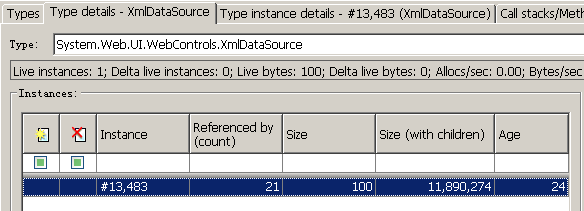
唯一的 XmlDataSource 类型实例是 #13, 483 号(全局实例编号)对象,通过详细信息可以看到如下被其引用的对象集:
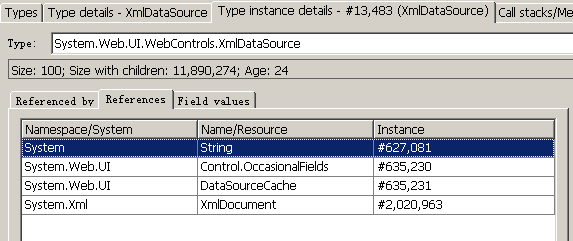
通过对引用它的对象一一检查后发现,#13, 483 号的 XmlDataSource 类型实例共引用了 6 个 XmlDataSourceView 对象(之所以是 6 个,是因为我做了 3 次 snapshot,每次 LoadRunner 测试脚本中都执行了 2 次查询操作),通过它们的 Age 可以看到都经过了多次 GC,但都没有释放掉。

具体到 Root 对象集的引用路径也很简单,只有一条,它们都引用了#13, 483 号实例的事件。通过这样的分析,我们就能够找到由于与 static XmlDataSource 类型对象的引用关系,这造成了每次查询生成的 XmlDataSourceView类型对象都无法被 GC 回收,因此形成了内存泄漏情况。解决办法也很简单,可以通过将页面中 XmlDataSource 类型对象做为非 static 成员变量即可。
通过修复上面这个对象泄漏问题,我们每次业务可以节约接近 11M 的托管内存。但是通过之前的监控来看,每次业务所增加的内存量要比这大很多,而且通过修复上面的问题也不能完全解决内存持续上涨的情况。可以认定,该业务中还存在有内存泄漏的其它位置,需要继续分析、诊断。这次我通过 Dispose Info 着手,上面说过了,.NET 对象在经过程序调用 Dispose 方法后,就应该不再被使用并被 GC 所回收,如果在 snapshot 发现执行 Dispose 方法后 GC 多次仍未能回收的,就需要关注了。下面就是 Dispose 过后的对象类型:

果然,可以看到在我们业务页面及其 Master 页面对象全部都是执行过 Dispose,但未 GC 掉。通过打开类型详细信息来查看可以发现,他们都被 SiteMap 所引用。

我们都知道 SiteMap 及 XmpSiteMapProvider 等 ASP.NET 2.0 中站点地图的组件,它们都是由 .NET Framework 提供和管理的,我们是通过 site 文件配置出来的,那么造成这个原因是什么呢?通过调查了解到 SiteMap 对象的 SiteMapResolve 事件是static的,而 SiteMap 也是全局性质的,只要我们这些页面订阅了 SiteMapResolve 事件,就都会引用到 SiteMap 上去。有兴趣的朋友可参见 MSDN SiteMap::SiteMapResolve Event 的SiteMapResolve causing memory leaks 小节。而且,从对象树的内存使用量上看也比较合理了,每个页面由于包括了大量的控件及其状态数据,因此都很大,每个页面对象有 46M 多。
写在最后
整个这个东西我写得是相对较完整、详细和易实践的,主要的原因是发现身边的一些人觉得托管堆的内存泄漏分析、诊断和定位是个能够用来“吃饭”的活,非常不愿意和别人分享。应该说这个事的确是很有经验含量的,这种经验化的东西都愿意私藏,等必要的时候拿来炫耀。但我想说的是,我们需要开放,需要传承,但凡是能够文字化的东西都是可以用来言传的(文字的意义)。在一个不提倡分享的环境里要么自己研究,要么裹足不前,如果没有想法的根本不要关注。
希望有用,如有想法请分享。晚安~
// 2009.03.06 01:01 添加 ////
补充个附件“lesson2.zip”,是 .NET Memory Profiler 内存泄漏分析、诊断的官方视频。使用的版本有点老了,而且例子应用太简单,不过其中的一些提示值得考虑。
// 2009.03.07 13:23 添加 ////
作者:lzy.je
出处:http://lzy.iteye.com
本文版权归作者所有,只允许以摘要和完整全文两种形式转载,不允许对文字进行裁剪。未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。