SQL开发中容易忽视的一些小地方(二)
目的:继上一篇:SQL开发中容易忽视的一些小地方(一) 总结SQL中的null用法后,本文我将说说表联接查询.
为了说明问题,我创建了两个表,分别是学生信息表(student),班级表(classInfo).相关字段说明本人以SQL创建脚本说明:
测试环境:SQL2005
CREATE TABLE [dbo].[student](
[ID] [int] IDENTITY(1,1) NOT NULL,
[sUserName] [nchar](10) COLLATE Chinese_PRC_CI_AS NULL,--姓名
[sAddress] [varchar](200) COLLATE Chinese_PRC_CI_AS NULL,--地址
[classID] [int] NULL,--班级
[create_date] [datetime] NULL CONSTRAINT [DF_student_create_date] DEFAULT (getdate())--入班时间
) ON [PRIMARY]
学生表记录:插入数据999999行.可以说的上是一个不大不小的表.
CREATE TABLE [dbo].[classInfo](
[classID] [int] IDENTITY(1,1) NOT NULL,--所属班级ID
[sClassName] [varchar](50) COLLATE Chinese_PRC_CI_AS NULL,--班级名称
[sInformation] [varchar](50) COLLATE Chinese_PRC_CI_AS NULL,--班级相关信息
[sDescription] [varchar](50) COLLATE Chinese_PRC_CI_AS NULL,--班级描述
[iSchooling] [int] NULL,--学费
CONSTRAINT [PK_classInfo] PRIMARY KEY CLUSTERED
(
[classID] ASC
)WITH (IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
班级表:共插入100行,实际可能不存在这么多的班级.
示例需求:查询学生的基本信息以及所属班级名称,我们都会第一时间想到用表关联,这里我列出相关实现方法.
第一:将数据量较大的学生表放在前面.
--大表在前
select top 1000 a.sUserName,b.sClassName from student a
inner join classInfo b on
a.classID=b.classID
第二:将数据量较小的班级表放在前面.
--小表在前
select top 1000 a.sUserName,b.sClassName from classInfo b
inner join student a on
a.classID=b.classID
第三:用where 实现.
--join与where
select top 1000 a.sUserName,b.sClassName from classInfo b, student a
where a.classID=b.classID
归纳:以上三种方式查询的结果都完全相同,但它们在实现效率上会有不同吗?这里首先提出两个网络上的观点:
网络观点一:一般要使得数据库查询语句性能好点遵循一下原则:在做表与表的连接查询时,大表在前,小表在后.
执行计划效果如图一:
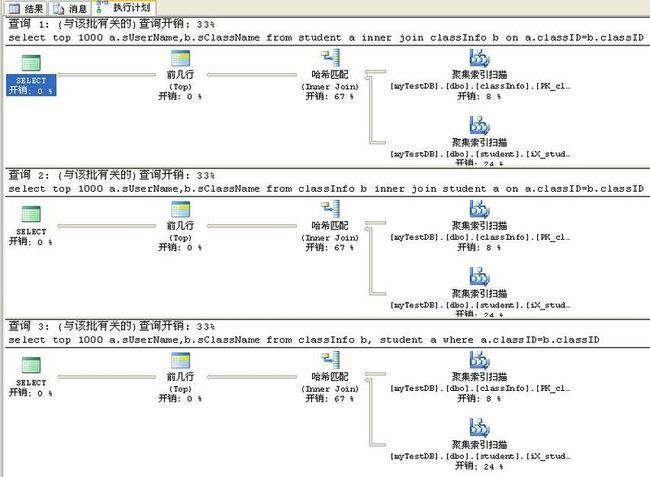
说明:
1:WHERE子句中使用的连接语句,在数据库语言中,被称为隐性连接。INNER JOIN称为显性连接。WHERE 和INNER JOIN产生的连接关系,没有本质区别,结果也一样。但是!隐性连接随着数据库语言的规范和发展,已经逐渐被淘汰,比较新的数据库语言基本上已经抛弃了隐性连接,全部采用显性连接了。
2:join的分类:
1> inner join:理解为“有效连接”,
2>left join:理解为“有左显示”,
3> right join:理解为“有右显示”
4> full join:理解为“全连接”
3 .join可以分主次表 左联是以左边的表为主,右边的为辅,右联则相反
网络观点二:inner join 与 where 在效率上是否一样?原文地址: http://topic.csdn.net/t/20050520/13/4022440.html 原文中有下面一段话:
---------------------------引用----------------------------------------------
SELECT A.X,B.Y FROM A B WHERE A.X=B.X
SELECT A.X,B.Y FROM A INNER JOIN B ON A.X=B.X
2句结果一样,但是速度相差很多,时间复杂度分别是 O(2n)和O(n*n)
------------------------------------------------------------------------------
我的观点:联接查询的时间复杂度并不是固定的,更不能说是由两种表现方式不同而决定的.join在查询的算法根据联接表的不同分三种情况:
第一种算法:NESTED LOOP:
定义: 对于被连接的数据子集较小的情况,嵌套循环连接是个较好的选择。在嵌套循环中,内表被外表驱动,外表返回的每一行都要在内表中检索找到与它匹配的行,因此整个查询返回的结果集不能太大(大于1 万不适合),要把返回子集较小表的作为外表。
示例:上面有了一个班级表,下面我再创建一个班级课程表,
CREATE TABLE [dbo].[course](
[ID] [int] IDENTITY(1,1) NOT NULL,
[sCourseName] [nchar](10) COLLATE Chinese_PRC_CI_AS NULL,--课程名称
[classID] [int] NULL,--所属班级ID
CONSTRAINT [PK_CKH] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
业务需求:查询所有班级对应的课程情况.
select sCourseName,sClassName from classInfo a
inner join course b
on a.classID=b.classID
执行计划效果图:
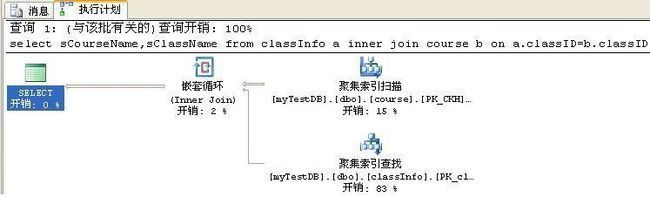
第二种算法:HASH JOIN :
定义: 散列连接是做大数据集连接时的常用方式,优化器使用两个表中较小的表(或数据源)利用连接键在内存中建立散列表,然后扫描较大的表并探测散列表,找出与散列表匹配的行。这种方式适用于较小的表完全可以放于内存中的情况,这样总成本就是访问两个表的成本之和。但是在表很大的情况下并不能完全放入内存,这时优化器会将它分割成若干不同的分区,不能放入内存的部分就把该分区写入磁盘的临时段,此时要有较大的临时段从而尽量提高I/O 的性能。
结论:从图一中可能看出SQL在联接班级表和学生表是采用了hash join方式,因为班级表数据量大,班级表数据量小.这种方式的查询时间复杂度为2n.
注意点:hash join可能非常容易的变成nested loop,下面的查询为hash join
inner join student a on
a.classID=b.classID
转换(hash join变nesteed loop):如果在后面组加上排序呢?此是会变成嵌套查询
select top 10000 a.ID,a.sUserName,b.sClassName from classInfo b
inner join student a on
a.classID=b.classID
order by a.ID
转换( nesteed loop 变 hash join ):上面的嵌套查询又可以改选成hash join
select * from(
select top 10000 a.ID,a.sUserName,b.sClassName from classInfo b
inner join student a on
a.classID=b.classID) as tbl
order by ID
第三种算法:排序合并连接
定义:通常情况下散列连接的效果都比排序合并连接要好,然而如果行源已经被排过序,在执行排序合并连接时不需要再排序了,这时排序合并连接的性能会优于散列连接。
网络观点二结论:inner join和where 在查询效率上没有区别,只是体现形式不同而已.
总结:我们可以通过查看SQL的执行计划来分析SQL的性能,一句话正确与否不在于说话的人,而在于实践验证结果.本人就表联接谈了自己的理解,如果有不对的地方还望各们指教.
注:
本文引用:
http://blog.chinaunix.net/u1/46451/showart.php?id=415529