什么是Grunt?
grunt是javascript项目构建工具,在grunt流行之前,前端项目的构建打包大多数使用ant。(ant具体使用 可以google),但ant对于前端而言,存在不友好,执行效率低,学习成本高的问题。所以最近几年对于前端构建工具--grunt就应运而生。
Grunt能做什么呢?
按任务目标大致可分为四类:
1. 文件操作型:比如合并、压缩js和css文件等(包括)。
2. 预编译型:比如编译less、sass、coffeescript等。
3. 类库项目构建型:比如 angular、ember、backbone等.
4. 工程质量保障型:比如jshint、jasmine、mocha等.
下面我们最主要来讲下 第一种(文件合并与压缩)。因为不管什么项目在上线之前都要对文件压缩 或者 有合并的文件要合并,也就是说减少请求数和代码体积减少,提高前端性能方面。 在学习grunt之前 我们都知道grunt依赖于nodeJS平台。也就是说我们要安装grunt 必须先安装nodeJS环境和NPM环境。
1.nodeJS的安装
由于我目前做的项目都是基于window下的 所以我这边讲的都是基于windows下的安装,如果想要了解linux或者unix环境下安装 可以google下。
我这边只讲下普通安装方法。其实就是最简单的方法了,对于大多Windows用户而言,都是不太喜欢折腾的人,你可以从这里(http://nodejs.org/dist/v0.6.1/node-v0.6.1.msi )直接下载到Node.js编译好的msi文件。然后双击即可在程序的引导下完成安装。
然后再命令行中直接运行如下命令即可:
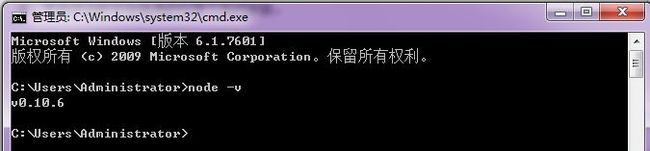
打印出版本号 说明已经安装好了。该引导步骤会将node.exe文件安装到C:\Program Files (x86)\nodejs\目录下,并将该目录添加进PATH环境变量。
2.NPM安装
1. 首先我们需要了解的是 什么是NPM?NPM能做什么?
npm是node的包管理器,我们在开发nodejs应用程序的过程中,可能需要依赖许许多多的第三方模块以提高开发效率,那么此时,我们就需要npm来辅助安装所需package。
2. 按照步骤如下:
1. 下载npm源码 https://github.com/isaacs/npm/tags
2. 将npm源代码解压到比如D:\npm目录中。
3. 执行命令 进入npm文件中 执行如下命令:
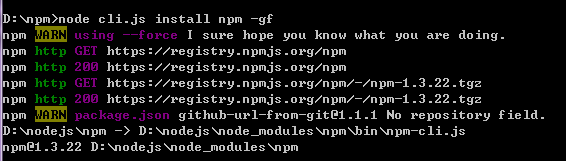
出现如上面信息 说明npm已经按照好了。
3.Grunt的安装
特别留意下grunt是有二个版本:服务器端版本(grunt)和客户端版本(grunt-cli),我们需要安装的是客户端版本。如果我们现在已经安装了服务器版本的话,我们可以卸载掉:如下命令就ok npm uninstall -g grunt 。
客户端安装命令npm install -g grunt-cli 如下图所示:

出现如上显示 说明也已经安装好了!其中 -g安装全局NodeJs模块。下面我们需要package.json文件。
package.json文件
假设你有个工程目录叫nodejsDemo,在工程根目录放个package.json.
package.json是npm的包配置文件,package.json用于配置你需要拉取的grunt插件信息,比如下面的代码:
{ "name": "gruntJs", "version": "1.0.0", "devDependencies": { "grunt": "~0.4.0", "grunt-contrib-jshint": "~0.1.1", "grunt-contrib-uglify": "~0.1.2", "grunt-contrib-concat": "~0.1.1" } }
但是要提醒下大家 package.json 中 devDependencies 内部的版本一定要对应,刚开始配置时候 一直配置不上 报错 有可能是版本的问题 所以安装我上面的版本来是ok的。
留意devDependencies字段,定义你要拉取的依赖模块,上面的代码,拉取grunt-contrib-uglify插件(用于压缩js)及grunt-contrib-concat 插件(用于合并文件),字段的值~0.1.1,指明需要模块的版本号,“~”是至少的意思。
在工程根目录启动命令行工具,运行npm install 如下图所示:
出现如上面信息 也说明已经配置成功了,依赖拉取成功后,在nodejsDemo工程中生成了node_modules目录,该目录就包含了如下几个文件:

到此 准备工作已经ok了!接下来我们需要Gruntfile.js配置。
Gruntfile.js配置
1. 先在工程目录nodejsDemo下 创建一个文件夹src 用于存放所有的js文件。里面目前包含2个js文件 grunt.js 和bb.js 现在我需要的是对src目录下的grunt.js和bb.js进行压缩与合并操作。
2. 接下来我要在工程目录nodejsDemo创建一个Gruntfile.js 内容代码如下:
module.exports = function(grunt) { // 配置 grunt.initConfig({ pkg : grunt.file.readJSON('package.json'), concat: { domop: { src: ['src/grunt.js', 'src/bb.js'], dest: 'dest/domop.js' } }, uglify: { build: { src : 'dest/domop.js', dest : 'dest/domop-min.js' } } }); // 载入concat和uglify插件,分别对于合并和压缩 grunt.loadNpmTasks('grunt-contrib-concat'); grunt.loadNpmTasks('grunt-contrib-uglify'); // 注册任务 grunt.registerTask('default', ['concat','uglify']); };
说明有concat是合并的意思 他的意思是指src文件夹下的grunt.js和bb.js 先合并到dest文件夹下的domop.js中。然后接着压缩 压缩文件为domop-min.js。
接下来我们只需要运行如下命令即可:
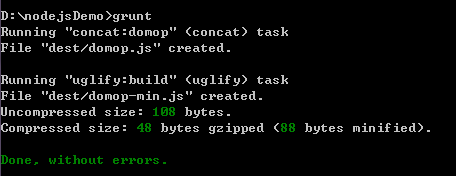
如上所示:说明已经完成合并与压缩操作了。 我们可以在根目录看到 动态生成了文件夹 dest 然后在里面有2个文件 如下:

说明一切都ok了!
接下来我们来重点看下Gruntfile.js代码的含义。
所有grunt的代码,必须放在module.exports函数内,参数grunt为grunt对象,当你运行命令grunt时,grunt系统会去读此函数的grunt构建配置。
grunt.initConfig(obj)
initConfig用于配置构建信息,第一个参数必须是个object。
// 构建任务配置 grunt.initConfig({ });
grunt.file.readJSON(path)
读取一个json文件,通常我们会把构建任务的基本配置写在独立的json文件内,方便我们修改。
// 构建任务配置 grunt.initConfig({ //读取package.json的内容,形成个json数据 pkg: grunt.file.readJSON('package.json') });
grunt.loadNpmTasks(pluginName).
加载指定插件任务.
grunt.registerTask(taskName,taskArray)
注册任务,比如下面的代码:
grunt.registerTask('default', ['concat','uglify']);
注册默认执行的任务,即你运行grunt命令时,触发的任务构建。 第二个参数为任务目标名,在initConfig()中配置:
// 配置 grunt.initConfig({ pkg : grunt.file.readJSON('package.json'), concat: { domop: { src: ['src/grunt.js', 'src/bb.js'], dest: 'dest/domop.js' } }, uglify: { build: { src : 'dest/domop.js', dest : 'dest/domop-min.js' } } });
文件的简单正则匹配语法
文件名(目录路径)的匹配,基本上和ant一样。
1. * 指匹配除了/外的任意数量的字符,比如foo/*.js.
2. ? 指匹配除了/外的单个字符.
3. ** 指匹配包含/的任意数量的字符,比如foo/**/*.js.
4. ! 指排除指定文件,比如src: ['foo/*.js', '!foo/bar.js']。
5. {} 可以理解为“or”表达式,比如src: 'foo/{a,b}*.js' 。