一个简单的MDX案例及说明
出处:http://www.cnblogs.com/SmartBizSoft/archive/2008/11/27/1341913.html
在关系数据库中使用SQL语言来查询、管理和操作数据库中的数据。在SQL Server中使用MDX语句来进行多维数据库的操作和管理,MDX不但可以用在SSAS中进行多维数据库的查询管理,也可使用在SSIS和SSRS中分别辅助处理ETL过程和报表开发过程。因为MDX语句没有标准化,不同的BI解决方案提供使用不同的多维数据查询技术,所以SQL Server中的MDX语言只能在SQL Server中使用,如果要进行其它数据库如ORACLE,Hyperion的查询,就要了解与其相对应的MDX,可能在语法或一些用法上不同于SQL Server中的MDX。本文针对的是SQL Server中的MDX。
本文以一个简单的MDX查询开始,分别解析这个查询的各个部分,以此来学习MDX语法。但是在这之前首先要介绍使用的案例多维数据集。
一.案例所使用的多维数据集
维度:

图一:维度信息
度量值:
图二:度量信息
其中Max Units Ordered和Total Units Ordered两个度量是导出度量,即通过命名计算得到的度量。
维度结构:

图三:Product维度结构

图四:Store维度结构
图五:Time By Day维度结构,即时间维度
图六:多维数据集总体结构
二.一个完整的MDX查询
例一:一个简单完整的MDX语句
| SELECT |
| NON EMPTY { |
| [Product].[Product Category - Product Class].[产品目录] |
| } ON COLUMNS, |
| NON EMPTY { |
| [Store].[Sales Country - Sales Region - Sales District Id - Region].[地区] |
| } ON ROWS |
| FROM [Foodmart多维数据立方] |
| WHERE [Time By Day].[month_of_year].&[3] |
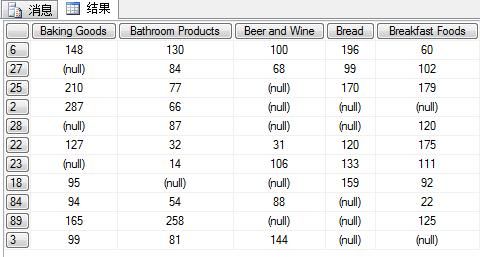
图七:例一的MDX查询得到的结果
a) SELECT子句
SELECT子句在MDX中也叫做查询器轴,在SELECT语句中总共支持128个轴(即编号从0到127)。其中前五个轴(即编号0-4)有内置命名,分别是:COLUMNS、ROWS、PAGES、CHAPTERS、SECTIONS。除了这五个轴可以通过命名和编号来访问以外,其它的轴(5-127)都只能通过编号来访问。在SSAS中通过MDX只能直接查看两个轴的信息,也就是说在SSAS中执行MDX的时候,这个MDX只能有两个轴,即COLUMNS和ROWS,如果有更多的轴在SSAS中是无法显示的。只能通过透视数据表或通过编程的方式来浏览。
在例一的MDX中,包含COLUMNS和ROWS两个轴。在COLUMNS轴中,[Product].[Product Category – Product Class].[产品目录]表示了访问的元组,这个元组的含义是:Product维度的名为Product Category – Product Class的层次下的名为“产品目录”这个等级所包含的所有成员。[Product]是维度名称,[Product Category – Product Class]是层次名称,[产品目录]是等级名称。最外面的大括号表示集合,即所有[Product].[Product Category – Product Class].[产品目录]元组所组成的集合。由此可以看出MDX中轴的访问顺序是:维度à层次à等级à成员。NON EMPTY的作用是过滤空值结果。查询结果如图七。
ROWS轴的结构与COLUMNS相同,所有128个轴的基本访问规则都是一样。每个轴之间用逗号分隔。另外,在同一个轴中不能出现不同维度的元组。如下:
例二:错误的MDX(一个轴中包含两个维度的元组)
| SELECT |
| { |
| [Product].[Product Category - Product Class].[产品目录], |
| [Store].[Store Name].[Store Name] |
| } ON COLUMNS, |
| { |
| [Store].[Sales Country - Sales Region - Sales District Id - Region].[地区] |
| } ON ROWS |
| FROM [Foodmart多维数据立方] |
| WHERE [Time By Day].[month_of_year].&[3] |
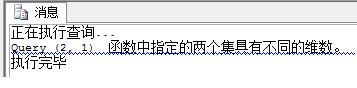
图八:错误信息
例二是一个错误的MDX查询,因为在COLUMNS轴中出现了两个维度的元组,这样的查询在SSAS中会执行的时候会报“函数中指定的两个集具有不同的维数。”这样的异常信息(如图八)。可以这样理解这种错误:多维数据集就像是一个个的正方体,正方体的每一条边都是一个维度,每一条边也都只能表示一个维度,如果让一条边表示两个维度自然就会出错,这也是不符合逻辑的。
如果要将不同维度的元组集合放到同一个轴中就要使用叉积,即不同维度之间的笛卡尔积。叉积的使用有几种不同的写法,可以使用CROSSJOIN函数、可以将集合与集合用*号相乘,不过最简单的就是直接把同一个轴中的不同维度用小括号括起来。可以把例二修改一下:
例三:修改后的例二,通过叉积使得可以在一个轴中观察不同维度的数据
| SELECT |
| NON EMPTY { |
| ( |
| [Product].[Product Category - Product Class].[产品目录], |
| [Store].[Store Name].[Store Name] |
| ) |
| } ON COLUMNS, |
| NON EMPTY { |
| [Store].[Sales Country - Sales Region - Sales District Id - Region].[地区] |
| } ON ROWS |
| FROM [Foodmart多维数据立方] |
| WHERE [Time By Day].[month_of_year].&[3] |
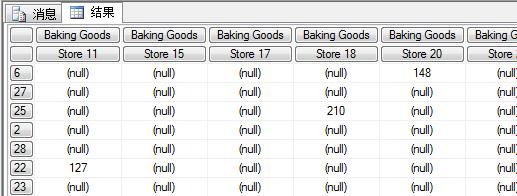
图九:叉积查询结果
例三就可以正常的运行而不会出现例二的错误了,不同之处仅仅是为两个不同的维度加了个小括号。加了小括号后元组的结构就发生了变化,不再是只由Product维度构成,而是由Product和Store两个维度共同构成。小括号中可以包含多个维度或者是同一维度不同层次的元组,但是不能有相同维度的员一层次存在。如果存在某两个相同维度的同一层次,在执行MDX的时候会报“…层次结构在CROSSJOIN函数中使用了多次”这样的异常信息。
下面再举出另外两种CROSSJOIN的用法:
例四:另一种叉积的用法
| SELECT |
| { |
| CROSSJOIN( |
| [Product].[Product Category - Product Class].[产品目录], |
| [Store].[Store Name].[Store Name] |
| ) |
| } ON COLUMNS, |
| { |
| [Store].[Sales Country - Sales Region - Sales District Id - Region].[地区] |
| } ON ROWS |
| FROM [Foodmart多维数据立方] |
| WHERE [Time By Day].[month_of_year].&[3] |
|
|
例五:第三种叉积用法
| SELECT |
| { |
| [Product].[Product Category - Product Class].[产品目录] |
| }* |
| { |
| [Store].[Store Name].[Store Name] |
| } |
| ON COLUMNS, |
| { |
| [Store].[Sales Country - Sales Region - Sales District Id - Region].[地区] |
| } ON ROWS |
| FROM [Foodmart多维数据立方] |
| WHERE [Time By Day].[month_of_year].&[3] |
例四和例五都是叉积的使用方法,可以得到和例三相同的结果。因为在SSAS中不能直接查看两个轴以上的查询,但是可以使用叉积的方式将三个轴以上的查询“平面化”到两个轴中。这样在理论上就可以直接在SSAS中查看多个轴的数据。这里我之所以要讲“理论上”,是因为叉积这种运算复杂度相当地高,如果将多个维度的元组集合进行叉积的话可能等待很久也得不到结果,计算机甚至会因为大量的运算而中断程序。所以在实际中要尽量控制这样的用法。如果要用最好首先将数据控制在一个非常有限的范围之内,减少叉积带来的运算开消。
b) FROM 子句
FROM子句表示MDX查询的来源多维数据集,FROM子句中只能包含一个多维数据集,也就是说同一个MDX查询只能来自于同一个多维数据集,而不能像SQL查询一样将多个数据表连接起来。另外,MDX中的FROM子句也可以是另一个MDX查询得到的一个子多维数据集,这样就可以更加复杂的MDX查询。如下面的例六所示:
例六:包含子多维数据集的复杂查询
| SELECT |
| { |
| [Product].[Product Category - Product Class].[产品目录] |
| }* |
| { |
| [Store].[Store Name].[Store Name] |
| } |
| ON COLUMNS, |
| { |
| [Store].[Sales Country - Sales Region - Sales District Id - Region].[地区] |
| } ON ROWS |
| FROM |
| ( |
| SELECT |
| ( |
| { |
| [Time By Day].[quarter].&[Q1] |
| } |
| ) ON COLUMNS |
| FROM [Foodmart多维数据立方] |
| ) |
c) WHERE 子句
WHERE子句的另一个名称是切片器轴,顾名思义它的作用主要就是对多维数据集进行切片和切块操作,限制数据集的大小。看下面的两个例子:
例七:多维数据集切片操作
| SELECT |
| { |
| [Product].[Product Category - Product Class].[产品目录] |
| }* |
| { |
| [Store].[Store Name].[Store Name] |
| } |
| ON COLUMNS, |
| { |
| [Store].[Sales Country - Sales Region - Sales District Id - Region].[地区] |
| } ON ROWS |
| FROM [Foodmart多维数据立方] |
| WHERE |
| ([Store].[Store Manager].&[Byrd]) |

图十:切片得到的结果
例七在前面叉积例子的基础上进行了切片操作,将数据限制在了Store Manager为Byrd的范围内。例七的查询得到的结果数据集从逻辑上包含三个轴,即产品目录、门店名称、地区编号。经过切片后,保留了产品目录和门店名称两个轴,另一个地区因为切片操作只剩下Byrd所对应的地区。查询结果如图十所示。
例八:多维数据集切块操作
| SELECT |
| NON EMPTY { |
| [Product].[Product Category - Product Class].[产品目录] |
| }* |
| { |
| [Store].[Store Name].[Store Name] |
| } |
| ON COLUMNS, |
| NON EMPTY { |
| [Store].[Sales Country - Sales Region - Sales District Id - Region].[地区] |
| } ON ROWS |
| FROM [Foodmart多维数据立方] |
| WHERE |
| ( |
| [Time By Day].[quarter].&[Q1]:[Time By Day].[quarter].[Q2], |
| [Store].[Store].&[18]:[Store].[Store].&[20], |
| [Product].[Product Category].&[Canned Clams]:[Product].[Product Category].&[Canned Sardines] |
| ) |
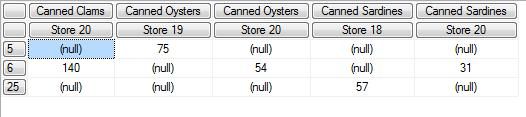
图十一:切块所得到的结果
例八在前面叉积的基础上进行了切块操作,分别在时间维度、门店维度、产品维度上进行了限制。图十一是这个MDX查询所得到的结果。
d) WITH 子句
WITH子句用于创建临时的命名计算成员及命名集合。通过WITH子句创建的命名计算成员和命名集合其生命周期有限,只限于与WITH子句相邻的MDX查询,当MDX查询结束后,用WITH子句创建的命名计算或命名集合也随之失效。如果要创建在整个会话过程中都保持有效的命名计算和命名集合的话,就要使用CREATE MEMBER和CREATE SET语句。
下面的例子演示了临时命名计算和临时命名集合的用法和查询结果:
例九:临时命名计算和临时命名集合的使用
| WITH MEMBER [Measures].[Avg Of Units Shipped] |
| AS 'AVG |
| ( |
| { |
| [Product].[Product].[Product] |
| }, |
| [Measures].[Units Shipped] |
| )' |
| ,FORMAT_STRING='###,###,###,##0.00' |
| SET [CROSSSET_StoreName] |
| AS '{ |
| [Store].[Store Name].[Store Name].[Store 1] |
| }' |
| SET [CROSSSET_TIME] |
| AS '{ |
| [Time By Day].[month_of_year].[month_of_year] |
| }' |
| SELECT NON EMPTY |
| { |
| [Measures].[Avg Of Units Shipped] |
| } |
| ON COLUMNS, |
| NON EMPTY [CROSSSET_StoreName]*[CROSSSET_TIME] |
| ON ROWS |
| FROM [Foodmart多维数据立方] |
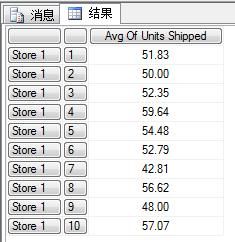
图十二:临时命名计算和命名集合的查询结果
WITH MEMBER语句最后的FORMAT_STRING是用于格式化数据结果的,在例九中,我把得到的平均值结果格式化为了保留两位小数,并进行千分位分隔。其它的常用格式符还有PERCENT、CURRENCY等。
三.常用函数
大多数聚合函数都有两个或两个以上的参数,其中第一个参数通常是用于计算的集合即进行计算的范围,后面的参数通常是用于计算的度量或数据。
1. AVG函数:
a) 功能:求平均值
b) 用法:
| AVG |
| ( |
| { |
| [Product].[Product].[Product] |
| }, |
| [Measures].[Units Shipped] |
| ) |
2. MAX函数:
a) 功能:求集合中的最大值。
b) 用法:
| MAX |
| ( |
| { |
| [Product].[Product].[Product] |
| }, |
| [Measures].[Units Shipped] |
| ) |
3. MIN函数:
a) 功能:求集合中的最小值。
b) 用法:
| MIN |
| ( |
| { |
| [Product].[Product].[Product] |
| }, |
| [Measures].[Units Shipped] |
| ) |
4. COVARIANCE函数:
a) 功能:求两个集合的协方差,这是一个统计函数。
b) 用法:
| COVARIANCE |
| ( |
| { |
| [Product].[Product].[Product] |
| }, |
| [Measures].[Units Shipped], |
| [Measures].[Units Ordered] |
| ) |
5. CORRELATION函数:
a) 功能:求两个集合的相关性,这是一个统计函数。
b) 用法:
| CORRELATION |
| ( |
| { |
| [Product].[Product].[Product] |
| }, |
| [Measures].[Units Shipped], |
| [Measures].[Units Ordered] |
| ) |
6. VARIANCE函数:
a) 功能:求集合的方差,这是一个统计函数。
b) 用法:
| VARIANCE |
| ( |
| { |
| [Product].[Product].[Product] |
| }, |
| [Measures].[Units Shipped] |
| ) |
7. IIF函数:
a) 功能:判断函数,根据布尔表达式返回二者之一。
b) 用法:
| IIF |
| ( |
| [Measures].[Avg Of Units Shipped]>50, |
| "[Units Shipped]", |
| "[Units Ordered]" |
| ) |