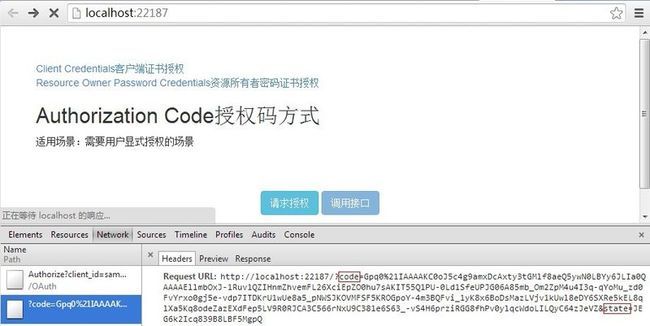
建议在了解了一定网络爬虫的基本原理和Heritrix的架构知识后进行配置和扩展。相关博文:http://www.cnblogs.com/hustfly/p/3441747.html
摘要
随着网络时代的日新月异,人们对搜索引擎,网页的内容,大数据处理等问题有了更多的要求。如何从海量的互联网信息中选取最符合要求的信息成为了新的热点。在这种情况下,网络爬虫框架heritrix出现解决了这个问题。
Heritrix是一个开源的、java开发的、可扩展的web爬虫项目。用户可以使用它来从网上抓取想要的资源。其最出色之处在于它良好的可扩展性,方便用户实现自己的抓取逻辑。
本文在已经简单分析过heritrix的工作流程,模块划分的基础上,在本地主机搭建heritrix的环境,实现基本的网页抓取过程,最后通过heritrix进行面向特定主题的网页抓取试验并进行结果分析。
关键词:网络爬虫;网页搜集;heritrix;主题抓取
Abstract
With the development of network, user’s requirement for search engines, webpage content, large data processing problems increases all the time. How to select most valuable information from massive Internet information has become a new hotspot. In this case, a new web crawler frame-heritrix solved this problem.
The heritrix web crawler is a java-developed, open-source, extensible project. Users can use it fetch resources from Internet. Its most outstanding feature lies in its good scalability, makes users can fetch information in their own logic.
This paper bases on analysis of work process, module division of heritrix. Then build the environment of heritrix, at last uses heritrix to fetch the specific web pages and analyzes the result.
Key words: heritrix; web crawler; source code analysis; focused crawl
一、引言
搜索引擎的实现过程,可以看作三步:1. 从互联网上抓取网页; 2. 对网页进行处理,建立索引数据库; 3. 进行查询。因此无论什么样的搜索引擎,都必须要有一个设计良好的爬虫来支持。Heritrix 是 SourceForge 上基于 Java 的开源爬虫,它可以通过 Web 用户界面来启动、设置爬行参数并监控爬行,同时开发者可以随意地扩展它的各个组件,来实现自己的抓取逻辑,因其方便的可扩展性而深受广大搜索引擎爱好者的喜爱。
网络爬虫工具Heritrix是由面向对象的程序设计语言java开发的,开源的网络爬虫工具包,它的程序执行速度之快是传统搜索引擎无法企及的。作为一个专为互联网网页进行存档而开发的网页检索器,开发者可利用其出色可扩展性来实现自己的抓取逻辑。虽然 Heritrix 功能强大,但其配置复杂,而且官方只在 Linux 系统上测试通过,用户难以上手。
本文在深入分析核心,然后在本地对该系统构建环境进行测试,详细介绍 Heritrix 在 windows 下 Eclipse 中的配置运行,并对其进行简单扩展,实现自己定义的搜索逻辑,最后对整个结果进行测试分析。
二、Window系统下Heritrix环境的搭建
2.1配置环境说明
- 系统环境:Windows7
- IDE工具:Eclipse
- 本次用到的版本是Heritrix1.14.4,由于开源,可以从SourceForge(http://sourceforge.net/projects/archive-crawler/files/ )上获取。下载zip文件来在windows平台使用
2.2在Eclipse中的配置
首先在Eclipse中新建Java工程MyHeritrix。然后利用下载的源代码包按一下步骤配置这个工程。
- 导入类库
Heritrix 所用到的工具类库都在 heritrix-1.14.4-src\lib 目录下,需要将其导入 MyHeritrix 工程。
1)将 heritrix-1.14.4-src 下的 lib 文件夹拷贝到 MyHeritrix 项目根目录;
2)在 MyHeritrix 工程上右键单击选择“Build PathàConfigure Build Path …”,然后选择 Library 选项卡,单击“Add JARs …”
3)在弹出的“JAR Selection”对话框中选择 MyHeritrix 工程 lib 文件夹下所有的 jar 文件,然后点击 OK 按钮。
设置完成后如图 2.1 所示:

图 2.1. 导入类库 - 导入后
- 拷贝源代码
1)将 heritrix-1.14.4-src\src\java 下的 com、org 和 st 三个文件夹拷贝进 MyHeritrix 工程的 src 下。这三个文件夹包含了运行 Heritrix 所必须的核心源代码;
2)将 heritrix-1.14.4-src\src\resources\org\archive\util 下的文件tlds-alpha-by-domain.txt 拷贝到 MyHeritrix\src\org\archive\util 中。该文件是一个顶级域名列表,在 Heritrix 启动时会被读取;
3)将 heritrix-1.14.4-src\src 下 conf 文件夹拷贝至 Heritrix 工程根目录。它包含了 Heritrix 运行所需的配置文件;
4)将 heritrix-1.14.4-src\src 中的 webapps 文件夹拷贝至 Heritrix 工程根目录。该文件夹是用来提供 servlet 引擎的,包含了 Heritrix 的 web UI 文件。需要注意的是它不包含帮助文档,如果想使用帮助,可以将 heritrix-1.14.4.zip\docs 中的 articles 文件夹拷贝到 MyHeritrix\webapps\admin\docs(需新建 docs 文件夹)下。或直接用 heritrix-1.14.4.zip 的webapps 文件夹替换 heritrix-1.14.4-src\src 中的 webapps 文件夹,缺点是这个是打包好的 .war 文件,无法修改源代码。
拷贝完毕后的 MyHeritrix 工程目录层次如图 2.2所示。这里运行 Heritrix 所需的源代码等已经准备完备,下面需要修改配置文件并添加运行参数。
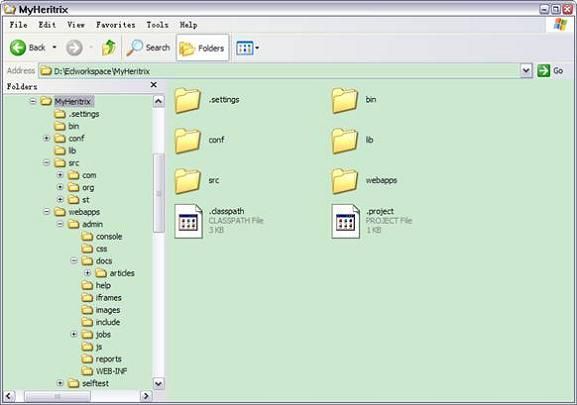
图 2.2 MyHeritrix 工程的目录层次
- 修改配置文件
conf 文件夹是用来提供配置文件的,里面包含了一个很重要的文件:heritrix.properties。heritrix.properties 中配置了大量与 Heritrix 运行息息相关的参数,这些参数的配置决定了 Heritrix 运行时的一些默认工具类、Web UI 的启动参数,以及 Heritrix 的日志格式等。当第一次运行 Heritrix 时,只需要修改该文件,为其加入 Web UI 的用户名和密码。如图2.3所示,设置 heritrix.cmdline.admin = admin:admin,“admin:admin”分别为用户名和密码。然后设置版本参数为 1.14.4。

图 2.3. 设置登陆用户名和密码
- 配置运行文件
在 MyHeritrix 工程上右键单击选择“Run AsàRun Configurations”,确保 Main 选项卡中的 Project 和 Main class 选项内容正确,如图 2.4所示。其中的 Name 参数可以设置为任何方便识别的名字。
然后在 Classpath 页选择 UserEntries 选项,此时右边的 Advanced 按钮处于激活状态,点击它,在弹出的对话框中选择“Add Folders”,然后选择 MyHeritrix 工程下的 conf 文件夹。如图 2.5所示。

图 2.4 配置运行文件—设置工程和类

图 2.5. 添加配置文件
至此我们的 MyHeritrix 工程已经可以运行起来了。下面我们来看看如何启动 Heritrix 并设置一个具体的抓取任务。
三、创建网页抓取任务
找到 org.archive.crawler 包中的 Heritrix.java 文件,它是 Heritrix 爬虫启动的入口,右键单击选择“Run AsàJava Application”,如果配置正确,会在控制台输出如图 3.1 所示的启动信息。

图 3.1. 运行成功时控制台输出
在浏览器中输入 http://localhost:8080,会打开Web UI 登录界面。
输入之前设置的用户名 / 密码:admin/admin,进入到 Heritrix 的管理界面,如图3.2所示。因为我们还没有创建抓取任务,所以 Jobs 显示为 0。
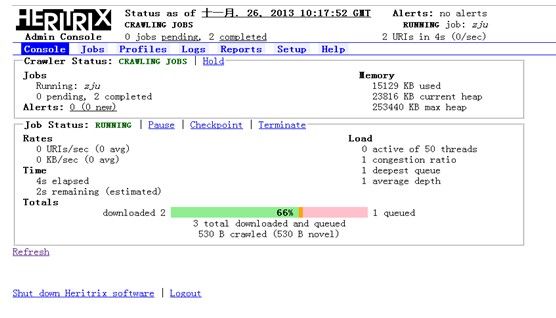
图3.2. Heritrix 控制台
Heritrix 使用 Web 用户界面来启动、设置爬行参数并监控爬行,简单直观,易于管理。下面我们以浙江大学软件学院首页 (http://www.cst.zju.edu.cn/) 为种子站点来创建一个抓取实例。
在 Jobs 页面创建一个新的抓取任务,如图3.3所示,可以创建四种任务类型。
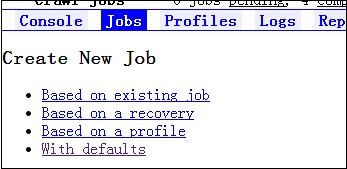
图 3.3. 创建抓取任务
Based on existing job:以一个已经有的抓取任务为模板生成新的抓取任务。
Based on a recovery:在以前的某个任务中,可能设置过一些状态点,新的任务将从这个设置的状态点开始。
Based on a profile:专门为不同的任务设置了一些模板,新建的任务将按照模板来生成。
With defaults:这个最简单,表示按默认的配置来生成一个任务。
这里我们选择“With defaults”,然后输入任务相关信息。
首先点击“Modules”按钮,在相应的页面为此次任务设置各个处理模块,一共有七项可配置的内容,这里我们只设置 Crawl Scope 和 Writers 两项,下面简要介绍各项的意义。
1)Select Crawl Scope:Crawl Scope 用于配置当前应该在什么范围内抓取网页链接。例如选择 BroadScope 则表示当前的抓取范围不受限制,选择 HostScope 则表示抓取的范围在当前的 Host 范围内。在这里我们选择 org.archive.crawler.scope.BroadScope,并单击右边的 Change 按钮保存设置状态。
2)Select URI Frontier:Frontier 是一个 URL 的处理器,它决定下一个被处理的 URL 是什么。同时,它还会将经由处理器链解析出来的 URL 加入到等待处理的队列中去。这里我们使用默认值。
3)Select Pre Processors:这个队列的处理器是用来对抓取时的一些先决条件进行判断。比如判断 robot.txt 信息等,它是整个处理器链的入口。这里我们使用默认值。
4)Select Fetchers:这个参数用于解析网络传输协议,比如解析 DNS、HTTP 或 FTP 等。这里我们使用默认值。
5)Select Extractors:主要是用于解析当前服务器返回的内容,取出页面中的 URL,等待下次继续抓取。这里我们使用默认值。
6)Select Writers:它主要用于设定将所抓取到的信息以何种形式写入磁盘。一种是采用压缩的方式(Arc),还有一种是镜像方式(Mirror)。这里我们选择简单直观的镜像方式:org.archive.crawler.writer.MirrorWriterProcessor。
7)Select Post Processors:这个参数主要用于抓取解析过程结束后的扫尾工作,比如将 Extrator 解析出来的 URL 有条件地加入到待处理的队列中去。这里我们使用默认值。
设置完“Modules”后,点击“Settings”按钮,这里只需要设置 user-agent 和 from,其中:
“@VERSION@”字符串需要被替换成 Heritrix 的版本信息。
“PROJECT_URL_HERE”可以被替换成任何一个完整的 URL 地址。
“from”属性中不需要设置真实的 E-mail 地址,只要是格式正确的邮件地址就可以了。
对于各项参数的解释,可以点击参数前的问号查看。本次任务设置如图3.4所示。

图 3.4. 设置 Settings
完成上述设置后点击“Submit job”链接,然后回到 console 控制台,可以看到我们刚刚创建的任务处于 pending 状态。
点击“Start”启动任务,刷新一下即可看到抓取进度以及相关参数。同时可以暂停或终止抓取过程。需要注意的是,进度条的百分比数量并不是准确的,这个百分比是实际上已经处理的链接数和总共分析出的链接数的比值。随着抓取工作不断进行,这个百分比的数字也在不断变化。
同时,在 MyHeritrix 工程目录下自动生成“jobs”文件夹,包含本次抓取任务。抓取下来网页以镜像方式存放,也就是将 URL 地址按“/”进行切分,进而按切分出来的层次存储。如图 3.5所示。
图 3.5. 抓取到的网页
因为我们选择了 BroadScope 的抓取范围,爬虫会抓取所有遇到的 URL,这样会造成 URL 队列无限制膨胀,无法终止,只能强行终止任务。尽管 Heritrix 也提供了一些抓取范围控制的类,但是根据实际测试经验,如果想要完全实现自己的抓取逻辑,仅仅靠 Heritrix 提供的抓取控制是不够的,只能修改扩展源代码。
四、扩展Heritrix实现自定义抓取任务
扩展 FrontierScheduler 来抓取特定网站内容
FrontierScheduler 是 org.archive.crawler.postprocessor 包中的一个类,它的作用是将在 Extractor 中所分析得出的链接加入到 Frontier 中,以待继续处理。在该类的 innerProcess(CrawlURI) 函数中,首先检查当前链接队列中是否有一些属于高优先级的链接。如果有,则立刻转走进行处理;如果没有,则对所有的链接进行遍历,然后调用 Frontier 中的 schedule() 方法加入队列进行处理。
从源代码可以看出 innerProcess() 函数并未直接调用 Frontier 的 schedule() 方法,而是调用自己内部的 schedule() 方法,进而在这个方法中再调用 Frontier 的 schedule() 方法。而 FrontierScheduler 的 schedule() 方法实际上直接将当前的候选链接不加任何判断地直接加入到抓取队列当中了。这种方式为 FrontierScheduler 的扩展留出了很好的接口。
这里我们需要构造一个 FrontierScheduler 的派生类 FrontierSchedulerForZju,这个类重载了 schedule(CandidateURI caUri) 这个方法,限制抓取的 URI 必须包含“zju”,以保证抓取的链接都是浙江大学内部的地址。派生类 FrontierSchedulerForZju 具体代码如下:
package org.archive.crawler.postprocessor; import org.archive.crawler.datamodel.CandidateURI; public class FrontierSchedulerForZju extends FrontierScheduler { private static final long serialVersionUID = 1L; public FrontierSchedulerForZju(String name) { super(name); } //重载schedule方法 protected void schedule(CandidateURI caUri) { String uri = caUri.toString(); //设置抓取规则:URI中包含有zju的抓取 if (uri.contains("zju")) { System.out.println(uri); getController().getFrontier().schedule(caUri); } } }
然后,在 modules 文件夹中的 Processor.options 中添加一行“org.archive.crawler.postprocessor.FrontierSchedulerForBjfu|FrontierSchedulerForBjfu”,这样在爬虫的 WebUI 中就可以选择我们扩展的 org.archive.crawler.postprocessor.FrontierSchedulerForBjfu 选项。
最终的抓取页面如图4.1所示,可以看出,抓取到的页面都是zju内部的URI,与第一次的抓取结果相比,多余的无关的URI已经全部排除。这样简单的一个扩展类就实现了简单的抓取目标。当然还可以在扩展类里添加更多的抓取规则,获取更精确更有意义的抓取结果。
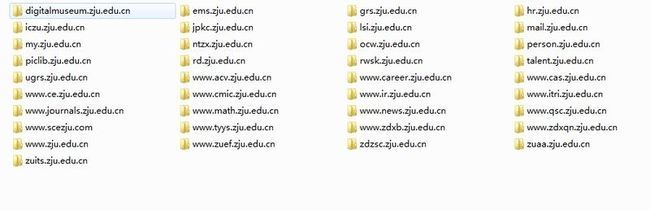
图4.1 第二次抓取任务结果
五、小结
目前,搜索引擎技术越来越受关注,其应用领域也越来越广。在搜索引擎的开发过程中,使用一个优秀的爬虫来获得所需要的网页信息是第一步,也是整个系统成功的关键。本文首先详细介绍了在Windows环境用Eclipse配置Heritrix的方法,配置成功后,实现第一个抓取任务。然后对控制类进行扩展。实现一个面向特定主题的抓取任务。
文中所设计的面向特定主题的网络爬虫的扩展应用,可针对某一特定主题快速搜集数据,并且该方法具有通用性,易于移植到其他网站上应用,例如可为电子商务的数据挖掘准备数据源。
参考文献
[1] Kristinn Sigurðsson. Incremental crawling with Heritrix. National and University Library of Iceland[M].2008
[2] 白万民,苏希乐.Heritrix在垂直搜索引擎中的应用[J].计算机时代,2011(9)
[3] 朱 敏,罗省贤.基于 Heritrix 的面向特定主题的聚焦爬虫研究[J]. 计算机技术与发展,2012 (2)
[4] 刘显一. 基于Lucene和Heritrix的主题搜索引擎的设计与实现[M].北京邮电大学.2012.8
[5] 张敏. 基于Heritrix 限定爬虫的设计与实现[J].计算机应用与软件.2013.4(4)
[6] 杨 颂,欧阳柳波.基于 Heritrix 的面向电子商务网站增量爬虫研究[J]. 软件导刊,2010,9( 7) : 38-39.
[7] 杨定中,赵 刚,王 泰.网络爬虫在 Web 信息搜索与数据挖掘中的应用[J].计算机工程与设计,2009,30( 24)
[8] 邱 哲,符滔滔. Lucene 2.0+Heritrix 开发自己的搜索引擎[M].北京: 人民邮电出版社,2007
Dive into Spring framework -- 了解基本原理(一)
在继续我们的分析之前,推荐各位静心来读一下<<Expert_OneOne_J2EE_Design_and_Development>> 第四章, 正如spring BeanFactory
API 中描述的。这一章主要说明了设计原则,设计模式,异常处理,反射等各个方面。本来也是想着直接来分析代码,但我们应该知其然也要知其所以然,为了能加深理解Johnson创建框架的设计思路,就引入了这一部分。
从spring的核心概念IoC入手,IoC的主要含义到底是针对哪个部分来说明的?是在xml配置的对象之间的关系么?针对这个IoC,我们应该如何应用?还是应该看看spring到底是怎么应用的。
关于设计原则,比较推荐看看《敏捷软件开发》,这里面有最基本的设计原则的汇总,而expert书中都有不谋而合的理论。为了全面,还是结合了《敏捷》里面的原则,主要罗列如下:
OCP(开闭原则)
在日常的开发分析过程中,经常会遇到设计问题,我们的框架需要满足任何需求的变更,设计模式里面经常这样来说明某个设计模式如何应对变化。但是所有的设计模式实际上都是建议我们如何应对这样的变化,应该如何考虑我们的框架,于是按照《敏捷》里面的定义:对扩展开放,对更改封闭。所以对于特定的需求设计,主要需要考虑的就变成了,如何来划分扩展的部分和更改的部分。不再重复《敏捷》里面的例子,但是看完其Shape的例子,首先应该考虑的就是抽象,抽象就是我们要找的扩展和更改的界限。
在接收到一个需求的时候,我们可以不顾一切的面向对象,直接写出一些class,然后让他们互相依赖,快速的完成这些功能。那么接下来如果还有任何需求变更,就要直接修改那些类之间的依赖关系,这就如一个食物链,如果最底层的生物有什么问题,那这条链子就会受影响,当然食物链这个类比有点牵强,毕竟一种生物不会一直吃一种食物,但我们假设是那样的。类之间的直接依赖类似于这样的关系,如果我们变了最底层的依赖,可能影响它的上层,上层也有可能进一步影响上层。如果像食物链那样,每种生物有多种食物,也就是在处理依赖时,能给依赖多重选择。应该如何来考虑这个“多重选择” , 当然应该是接口。《敏捷》在Shape示例中,由过程性代码转变成OO代码,主要是加入了抽象,使得“引用”依赖接口中的“动作”,而并不是“具体对象”。这是需要特别强调的,就是不要依赖对象,要依赖动作,而java里面的interface就是“动作”的集合。
SRP(单一职责)
首先我们要明确的是何为职责,根据《敏捷》里面的定义,“引起变化的原因”。在日常开发里面,这种状况太普遍了,作为开发大军中的一员,就是这么过来的,曾经有个action类可以有3W行代码。想想这个代码行数,就知道导致它发生变化的原因多的很。如果(要是都有如果就好了)当年咱能顿悟出这么几个原则,就不说当年了,现在起就应该结合SRP和OCP来进行最初始的设计划分。
一般的web应用项目,在action之后总是按照三层的概念实现底层,一个使用struts 1/struts2的项目总是会有比较雍容的action层,但service层却仅仅是dao的封装。于是一个贫血的架构就变得家喻户晓。
但我们经常忽略那些业务上的划分,那么结合框架和业务,应该如何来考虑这种划分呢?首先一个action受http的影响(输入和输出),输入参数的各种验证,然后根据各种判断来调用某个service。从整体架构上讲,虽然是隔离了dao,但在业务层(action+service)会很臃肿。尤其是action就是个定时炸弹,承担各种职责。这个时候,就应该考虑一下设计模式来隔离一部分,划分出变化的和不变的。
LSP(Liskov替换原则)
《敏捷》定义为:子类型必须能够替换基类型。
这个定义里面有着对继承关系的强制性定义。其实在我们的日常使用中,出现比较多的问题应该是,一个类继承了很多没用的功能,这多是由于没有明确划分功能范围引起的接口方法污染。其实在一个子类不能完全替换父类的时候,就应该引起我们的警觉,是否应该按照SRP和OCP进行调整,LSP就像是一个标杆原则,总是要我们检验继承关系。
DIP(依赖注入)
《敏捷》认为所有的依赖都不应该是直接的类依赖,而应该是基于抽象。这个跟《Expert》的Achieve Loose Couple with Interfaces的出发点是一致的。上层不应该直接依赖底层,而都应依赖抽象,这里要强调两个东西,一个是何为抽象,一个是何为依赖。抽象应该是动作的抽象,那就是接口。而依赖则不仅仅是引用某个对象算是依赖,实现了某个接口也是一种依赖。
ISP(接口隔离)
在SRP的阐述中,就说起那个场景,我们的一个类里面可能不得不实现不必要的接口,这些上层接口的变化会影响实现类。在ISP中,就要求“不要强迫用户依赖不使用的方法”。接口的划分应该是基于业务需要的,如果一个interface中包含了几个业务动作,那么这不仅仅不符合SRP的原则,同时给依赖方也带来不必要的麻烦,那就是他们不得不实现不用的方法。出现这种情况的时候,我们应该考虑精细划分客户方的范围,从而针对不同的客户方,提供特别的接口动作。
以上主要是从《敏捷》中借鉴来的基本的设计原则,最开始的时候说过了,就是因为有异曲同工的基础,才考虑到直接引用《敏捷》的内容。在我看完《敏捷》之后的感觉就是,这本书要一直伴随我的左右,要深入的实践体会那些设计原则和模式。实际上这些原则都不能独立的套用,而是相辅相成的。在上面的原则描述中,都基于一个最基本的基础就是抽象。依赖抽象去实现OCP,如确认一种依赖之后,为了以后的变化,上层依赖的是接口,而底层则可能是通过策略模式等设计模式来开放给需求的变更,而这又恰恰是DIP所要求的。spring作为使用如此广泛的框架,其设计必然符合这些基本原则,才能为我们提供那些不变的依赖,和我们业务中变化的需求,那么spring中的OO设计原则又特别强调哪几个方面?
再次强调,《Expert》的chapter 4绝对值得读5遍以上,这一章摊开来就可以写一本书,其中有一些引用资料,也极有参考价值。在写这篇blog的时候,最开始特别想赶进度快点写点东西,但是再来回味《Expert》却发现以前那么一些原则,在前几年的开发里面好像没有多少顾忌的。所以就把这一章反复读了4遍,才略下本文,希望以后能够铭记和实践。
下一部分看看spring的作者Rod Johnson是参考了哪些基本原则,考虑到哪些方面来实现了伟大的spring framework?
转载请注明出处。