MySQL复制(三) --- 高可用性和复制
实现高可用性的原则很简单:
- 冗余(Redundancy):如果一个组件出现故障,必须有一个备用组件。这个备用组件可以是standing by的,也可以是当前系统部署中的一部分。
- 应急计划(Contigency plans):如果一个组件出现故障,你必须知道做什么。这依赖于哪个组件出现故障以及如何发生故障。
- 程序(Procedure):如果一个组件出现故障,你能够及时发现并迅速有效的执行你的计划。
冗余(Redundancy)
只要有单点故障(SPOF:Single Point of Failure)的存在,就无法保证系统的高可用性(关于单点故障可以参考Fenng的这篇文章,比较通俗易懂)。
为了搞清楚哪里需要冗余机制,我们需要找到部署中所有潜在的单点。虽然说起来简单,但是需要一点想象力,以确保真正找到全部单点。交换机,路由器,网卡甚至电缆都是单点,除了这些,电源和物理设施也很重要。还有一些也为成为单点,比如只有一个员工知道如何处理某种类型的故障,所有的网络都被集中到一个web页面进行管理等。但定位到所有的单点并不意味着你必须要全部消除它们,因为有些单点或许因为经济上,技术上或者地理上的原因而无法完全消除,但知道这些单点的存在将有助于出错时排错。
在考虑要不要消除某个单点,有些因素需要考虑:复制组件的成本,不同组件发生故障的概率,替换组件的时机以及修复组件时的担当的风险。比如你替换一个组件需要一周时间,在这一周期间,运行中的备用组件也有可能出现故障,这些你都必须要考虑到。
一旦确定要消除的单点,接下来就需要考虑如何建立冗余机制,有两种方案可供选择:1)为每一个组件建立一个备用组件,如果原始组件发生故障,立即启用备用组件;2)系统本身有额外的容量,当一个组件出现故障时仍能hold住。第一种方案,虽然看起来简单,但是成本高。你必须让备用组件处于standby状态,一直和主组件保持一致。其优点就是在切换组件的时候不会损失性能,而且切换到standby组件所花的时间通常要比重新构建组件快。方案二为系统构建额外容量的方案可以让你使用所有组件(资源)来运行系统,这样系统可以处理更高的瞬间峰值负载。但有一点必须明白,这种方案时,系统必须拥有额外的容量以保证在某些组件出现故障时系统仍然能hold住。有时候只为一个服务器发生故障留有余地还不够,这个时候你需要权衡,以及这种情况出现的概率是多少。比如安装了100台服务器,其中一台服务器发生故障的概率是1%,那么1台,2台,3台服务器发生故障的概率会是多少呢?根据二项式定理计算可得到依次为100%,20.33%,16.17%。
应急计划(Contigency plans)
只做冗余还是不够,当你一个组件发生故障时,你还需要知道如何去应对。在之前的例子里,当Slave服务器出现故障时很容易去处理,因为只需把新的连接全部重定向到能工作的Slave服务器,同时你需要考虑:1)现有的连接怎么处理?仅仅中止程序并给用户返回一个出错信息明显不是一个好主意。通常情况下,在用户和数据库之间有一个应用层,这个时候应该让应用层向别的服务器提交查询;2)如果Master发生故障怎么处理?假设你已经提供了一个额外的Master做冗余,你还必须提供机制让所有Slave重定向新的Master。
下面介绍一下如何处理各种拓扑结构下MySQL服务器宕机的技术。一般来说,需要考虑三种角色:Master,Slave,Relay。
- Slave故障:这是最简单处理的故障。因为Slave仅仅是用于读查询,只需通知负载均衡器该Slave出故障,然后负载均衡器就会把新的请求都重定向到工作中的其他Slave。这就需要剩下的Slave能够处理这些额外的负载。除了这之外,发生故障的Slave一般来说不会影响复制机制的拓扑结构,也就不用去考虑特殊的拓扑结构以保证在Slave发生故障时易于管理。当Slave发生故障时,对于已经提交给该Slave并等待响应的查询,需要重新向工作的其他Slave提交查询请求。
- Master故障:如果Master发生故障,就必须用备用的Master替换以保证部署的系统能正常运行,并且要快。当Master发生故障时,所有的写请求立即终止,因此首先要做的就是启用新Master并把所有的写请求重定位过去。因为主Master发生故障了,所有的Slave都失去了Master连接。这就意味着Slave上数据已不是最新的,虽然还能够继续响应读请求。尽管如此,如果有些请求需要监听到达Slave的变化,这些请求可能会被阻止,而有些请求或许把自己写进Slave中继日志,并最终由Slave执行,这类请求就无需考虑。Master发生故障时,对于那些正在Master上等待某个事件的请求来说情况更加糟糕。对于这种情况,需要进行处理,一般来说就是用户被通知请求失败,然后需要重新发送请求。
- Relay故障:Relay服务器发生故障时需要进行一些特殊处理。如果Relay服务器发生故障,其他的Slave必须被重定向到其他的Relay服务器或者直接定向到Master。因为Relay服务器是用于缓解Master的负载,那么有可能出现Master无法处理Relay上的负载。
- 灾难恢复:在高可用性的世界里,灾难并不意味着地震或者洪水,它只是表示服务器发生了极坏的状况,并不是局部的状况。比如说数据中心断电了。灾难的本质在于很多事情都同时出现故障,无法在一个数据中心通过备份服务器提供冗余解决问题。因此有必要要确保数据被保存在另外一个安全的地方。很多公司会把不同的组件放在不同的办公室,即使公司相对较小的时候也这么干。
程序(Procedure)
如果你管理一个小站点,你可以不用规划并手动管理这些服务器,但是随着服务器数量的快速增长,自动化就变得很有必要。特别是下列的这些工作:
- 追加新Slave:追加新Slave的方法有很多。一般的步骤是先获取现有一个服务器的快照,通常是一个Slave服务器,然后在新服务器上恢复快照,并在正确的位置开始复制。这个里需要注意的是获取服务器快照这一步,因为这将直接决定你可以多长时间让一个新Slave服务器上线。获取快照的方法有以下几种:
- 使用mysqldump:使用mysqldump安全但比较慢。这种方法允许你用与之前不同的存储引擎去恢复数据。如果使用InnoDB表的话,还可以得到一致性快照,这也意味着你不需要脱机进行快照。
- 复制数据库文件:这个相对来说要快一点,但是需要脱机。
- 使用在线备份方法:有不同的方法,比如InnoDB的热备份(Hot Backup)
- 使用LVM获取快照:在Linux系统,可以使用Logical Volume Manager(LVM)来获得卷快照。它要求你事先创建好特殊的LVM卷。
- 使用文件系统的快照方法:Solaris ZFS文件系统支持内置快照,这种方法用于备份非常快。除了mysqldump以外,这些方法都不能使用一个不同的存储引擎来重建数据。
- 删除Slave:删除Slave只需要通知负载均衡器该Slave不可使用即可。
- 切换Master:对于日常维护,将连在Master上的所有Slave切换到备份Master上,并通知负载均衡器该Master不可使用,是一件很平常的事。这个过程应该可以无须宕机处理。这个可以通过Slave提升来完成,也可以采用更简单的host standby来解决。
- 处理Slave故障:Slave会出现故障,这只是一个频率问题。所以处理Slave故障在任何部署中都必须作为一个常规事件来对待。如果检测到Slave不在,通知负载均衡器该Slave不可使用即可。
- 处理Master故障:当Master突然出现故障时,你必须检测到这个故障,并把所有的Slave都连到一个备用服务器上,或者把其中一个Slave提升为新Master。
- Slave升级:把Slave升级到一个新版本一般不会有问题,但会暂时不可使用,跟删除Slave操作差不多。
- Master升级:为了升级Master,经常有必要首先升级所有的Slave。但这也不一定。升级的时候,Master肯定不可用,这跟处理Master故障操作差不多。
热备份(Hot Standby)
最简单的复制服务器的拓扑就是热备份的拓扑。该拓扑结构里面包括一个Master和一个被称作热备份的专用服务器。工作原理就是当Master发生故障时,热备份立即充当Master的镜像服务器,所有的客户端和Slave服务器全部切换到热备份服务器进行工作。不过切换的时候需要考虑一些细节的问题:1)当切换到热备份的服务器时,你需要重新定位需要从哪里开始复制二进制日志,一般热备份的日志位置信息和Master不一样;2)某个Slave可能需要的二进制日志在热备份服务器上不一定有;3)当修好的Master切换回来的时候,它上面的有些修改可能任何其他Slave都未来得及复制。
首先,问题简单化,我们看看从Master切换到热备份服务器的过程,该过程Master并不宕机。默认情况下,slave线程执行的事件并不写入二进制日志,但是作为热备份的slave明显是需要这些二进制日志的,所以为热备份服务器增加这样一个参数。
[mysqld]
log-slave-updates
切换时的主要问题在于,如何使得从热备份服务器开始复制的位置和从Master停止复制的位置完全相同。有很多原因可以使得热备服务器和Master服务器的二进制日志位置信息不一致,比如Master启动的时候热备份服务器并没有连上,即使这个没问题,也不能保证同一个事件写入Master和热备份服务器二进制日志的过程和时机完全一样。
切换的基本思路是:确认让slave和热备份服务器在同一点上停止复制,然后让salve连到热备份服务器。
standby>SHOW SLAVE STATUS\G
...
Relay_Master_Log_File: master-bin.000096
...
Exec_Master_Log_Pos: 756648
slave>SHOW SLAVE STATUS\G
...
Relay_Master_Log_File: master-bin.000096
...
Exec_Master_Log_Pos: 743456
# 从上可知说明热备份服务器的日志位置要领先于Slave,所以需要让Slave从Master继续复制到和热备份一样的位置
slave>START SLAVE UNTIL MASTER_LOG_FILE = 'master-bin.000096' MASTER_LOG_POS = 756648;
slave>SELECT MASTER_POS_WAIT('master-bin.000096', 756648);
# 现在Slave和热备份服务器都在同一个点停止复制,就可以让Slave连到热备份服务器上,但是指定从哪个文件和位置开始复制呢。对于同一个复制点在Master上的文件和位置和热备份上的文件和位置是不一样的。
standby>SHOW MASTER STATUS\G
File: standby-bin.000019
Position: 56447
Binlog_Do_DB:
Binlog_Ignore_DB:
slave>CHANGE MASTER TO
MASTER_HOST = 'standby-1',
MASTER_PORT = 3306,
MASTER_USER = 'repl_user',
MASTER_PASSWORD = 'xyzzy',
MASTER_LOG_FILE = 'standby-bin.000019',
MASTER_LOG_POS = 56447;
slave>START SLAVE;
如果Slave的复制位置在热备份服务器之前的话,我们只需互换一下上面的步骤。下一节我们将考虑如何处理Master意外停止的情况。
双Master(Dual Master)
双Master拓扑结构中,两个Master互相复制数据以保持同步。因为是对称的,这种设置容易使用。这种设置中,服务器可以是主动的(active),也可以是被动(passive)的。主动的服务器是指接受写操作,然后这些变化通过复制传播到其他Slave上。被动的服务器是指不接受写而仅仅是跟随主动Master,随时准备切换。两个服务器有两种设置,一种是active-active,一种是active-passive,第二种很像热备份的的拓扑,带是由于是对称,切换起来比较方便。在双Master配置中,passive服务器并不一定要求接受读请求,这个时候其实就是一个冷备份。在双Master的拓扑中,并不一定非要通过复制来保证两个Master的同步。
active-active型双Master的常用的一个场景就是让服务器在物理上接近不同的用户组。用户使用本地服务器,更改会被复制到另外一台服务器来保持两者同步。由于事务是在本地提交的,所以响应比较快。但由于事务是本地提交的,两个服务器并不是时时刻刻完全一致的。这就会有些问题:1)如果同一个信息在两台服务器上更新,将会服务器将会产生冲突,复制也会终止。你可以只让其中一台接受写操作,可以在某种程度上避免冲突的发生。2)如果两台服务器在处于不一致状态下发生故障,有些事务将会丢失,这也是异步复制的硬伤,不过你可以通过使用半同步复制(MySQL 5.5引入)来限制事务丢失的个数。
对于active-passive型的来说,你可能使用passive的Master来做服务器升级这样的管理工作。active-passive有一个根本性的问题需要解决。split-brain syndrome:当网络连接短时间内中断,从而使得从服务器主动升级为主服务器,然后网络又恢复了。如果在他们各自为主服务器的时间里,更改在两台服务器上都执行就会产生冲突。当使用共享磁盘的方式时,两台服务器同时写磁盘会产生有趣的问题。
对于如何实现双Master直接的同步,有几种方案。
共享磁盘(Shared Disks)
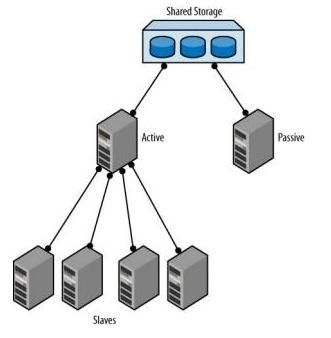
这是最直接的双Master方案:两个Master通过一个像SAN(Storage Area Network)的共享磁盘架构连接在一起,并被设置成使用相同的文件。因为其中一个是passive,它不会写任何东西到文件中,
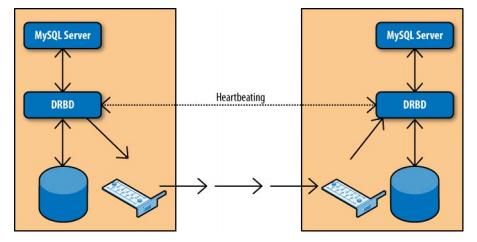
使用DRBD复制磁盘(Replicated disks using DRBD)
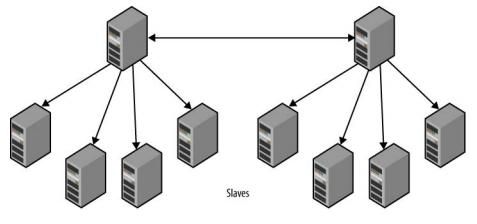
双向复制(bidirectional replication)
半同步复制(Semisynchronous Replication)
Slave提升(Slave Promotion)