后端分布式系列:分布式存储-HDFS 异常处理与恢复
在前面的文章 《HDFS DataNode 设计实现解析》 中我们对文件操作进行了描述,但并未展开讲述其中涉及的异常错误处理与恢复机制。 本文将深入探讨 HDFS 文件操作涉及的错误处理与恢复过程。
读异常与恢复
读文件可能发生的异常有两种:
- 读取过程中 DataNode 挂了
- 读取到的文件数据损坏
HDFS 的文件块多副本分散存储机制保障了数据存储的可靠性, 对于第一种情况 DataNode 挂了只需要失败转移到其他副本所在的 DataNode 继续读取, 而对于第二种情况读取到的文件数据块若校验失败可认定为损坏,依然可以转移到读取其他完好的副本, 并向 NameNode 汇报该文件 block 损坏,后续处理由 NameNode 通知 DataNode 删除损坏文件 block, 并根据完好的副本来复制一份新的文件 block 副本。
因为读文件不涉及数据的改变,所以处理起来相对简单,恢复机制的透明性和易用性都非常好。
写异常与恢复
之前的文章中对写文件的过程做了描述,这个过程中可能发生多种不同的错误异常对应着不同的处理方式。 先看看有哪些可能的异常?
异常模式
可能的异常模式如下所列:
- Client 在写入过程中,自己挂了
- Client 在写入过程中,有 DataNode 挂了
- Client 在写入过程中,NameNode 挂了
对于以上所列的异常模式,都有分别对应的恢复模式。
恢复模式
当 Client 在写入过程中,自己挂了。由于 Client 在写文件之前需要向 NameNode 申请该文件的租约(lease), 只有持有租约才允许写入,而且租约需要定期续约。所以当 Client 挂了后租约会超时,HDFS 在超时后会释放该文件的租约并关闭该文件, 避免文件一直被这个挂掉的 Client 独占导致其他人不能写入。这个过程称为 lease recovery。
在发起 lease recovery 时,若多个文件 block 副本在多个 DataNodes 上处于不一致的状态,首先需要将其恢复到一致长度的状态。 这个过程称为 block recovery。 这个过程只能在 lease recovery 过程中发起。
当 Client 在写入过程中,有 DataNode 挂了。写入过程不会立刻终止(如果立刻终止,易用性和可用性都太不友好), 取而代之 HDFS 尝试从流水线中摘除挂了的 DataNode 并恢复写入,这个过程称为 pipeline recovery。
当 Client 在写入过程中,NameNode 挂了。这里的前提是已经开始写入了,所以 NameNode 已经完成了对 DataNode 的分配, 若一开始 NameNode 就挂了,整个 HDFS 是不可用的所以也无法开始写入。流水线写入过程中,当一个 block 写完后需向 NameNode 报告其状态, 这时 NameNode 挂了,状态报告失败,但不影响 DataNode 的流线工作,数据先被保存下来, 但最后一步 Client 写完向 NameNode 请求关闭文件时会出错,由于 NameNode 的单点特性,所以无法自动恢复,需人工介入恢复。
上面先简单介绍了对应异常的恢复模式,详细过程后文再描述。在介绍详细恢复过程前,需要了解文件数据状态的概念。 因为写文件过程中异常和恢复会对数据状态产生影响,我们知道 HDFS 文件至少由 1 个或多个 block 构成,因此每个 block 都有其相应的状态, 由于文件的元数据在 NameNode 中管理而文件数据本身在 DataNode 中管理,为了区分文件 block 分别在 NameNode 和 DataNode 上下文语境中的区别, 下面我们会用 replica(副本)特指在 DataNode 中的 block,而 block 则限定为在 NameNode 中的文件块元数据信息。 在这个语义限定下 NameNode 中的 block 实际对应 DataNodes 上的多个 replicas,它们分别有不同的数据状态。 我们先看看 replica 和 block 分别在 DataNode 和 NameNode 中都存在哪些状态?
Replica 状态
Replica 在 DataNode 中存在的状态列表如下:
- FINALIZED: 表明 replica 的写入已经完成,长度已确定,除非该 replica 被重新打开并追加写入。
- RBW: 该状态是 Replica Being Written 的缩写,表明该 replica 正在被写入,正在被写入的 replica 总是打开文件的最后一个块。
- RWR: 该状态是 Replica Waiting to be Recovered 的缩写,假如写入过程中 DataNode 挂了重启后, 其上处于 RBW 状态的 replica 将被变更为 RWR 状态,这个状态说明其数据需要恢复,因为在 DataNode 挂掉期间其上的数据可能过时了。
- RUR: 该状态是 Replica Under Recovery 的缩写,表明该 replica 正处于恢复过程中。
- TEMPORARY: 一个临时状态的 replica 是因为复制或者集群平衡的需要而创建的,若复制失败或其所在的 DataNode 发生重启,所有临时状态的 replica 会被删除。 临时态的 replica 对外部 Client 来说是不可见的。
DataNode 会持久化存储 replica 的状态,每个数据目录都包含了三个子目录:
- current:目录包含了
FINALIZED状态 replicas。 - tmp:目录包含了
TEMPORARY状态的 replicas。 - rbw:目录则包含了
RBW、RWR和RUR三种状态的 relicas,从该目录下加载的 replicas 默认都处于RWR状态。
从目录看出实际上只持久化了三种状态,而在内存中则有五种状态,从下面的 replica 状态变迁图也可以看出这点。 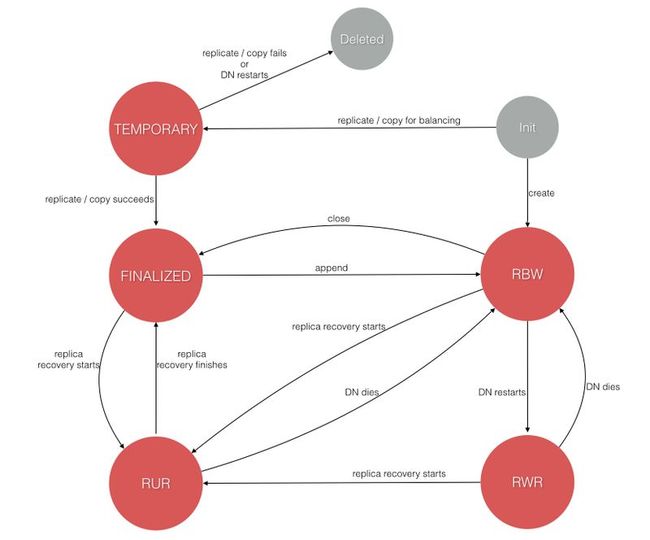
我们从 Init 开始简单描述下 replica 的状态变迁图。
- 从
Init出发,一个新创建的 replica 初始化为两种状态:- 由 Client 请求新建的 replica 用于写入,状态为
RBW。 - 由 NameNode 请求新建的 replica 用于复制或集群间再平衡拷贝,状态为
TEMPORARY。
- 由 Client 请求新建的 replica 用于写入,状态为
- 从
RBW出发,有三种情况:- Client 写完并关闭文件后,切换到
FINALIZED状态。 - replica 所在的 DataNode 发生重启,切换到
RWR状态,重启期间数据可能过时了,可以被丢弃。 - replica 参与 block recovery 过程(详见后文),切换到
RUR状态。
- Client 写完并关闭文件后,切换到
- 从
TEMPORARY出发,有两种情况:- 复制或集群间再平衡拷贝成功后,切换到
FINALIZED状态。 - 复制或集群间再平衡拷贝失败或者所在 DataNode 发生重启,该状态下的 replica 将被删除
- 复制或集群间再平衡拷贝成功后,切换到
- 从
RWR出发,有两种情况:- 所在 DataNode 挂了,就变回了
RBW状态,因为持久化目录rbw包含了三种状态,重启后又回到RWR状态。 - replica 参与 block recovery 过程(详见后文),切换到
RUR状态。
- 所在 DataNode 挂了,就变回了
- 从
RUR出发,有两种情况:- 如上,所在 DataNode 挂了,就变回了
RBW状态,重启后只会回到RWR状态,看是否还有必要参与恢复还是过时直接被丢弃。 - 恢复完成,切换到
FINALIZED状态。
- 如上,所在 DataNode 挂了,就变回了
- 从
FINALIZED出发,有两种情况:- 文件重新被打开追加写入,文件的最后一个 block 对应的所有 replicas 切换到
RBW。 - replica 参与 block recovery 过程(详见后文),切换到
RUR状态。
- 文件重新被打开追加写入,文件的最后一个 block 对应的所有 replicas 切换到
接下我们再看看 NameNode 上 block 的状态有哪些以及时如何变化的。
Block 状态
Block 在 NameNode 中存在的状态列表如下:
- UNDER_CONSTRUCTION: 当新创建一个 block 或一个旧的 block 被重新打开追加时处于该状态,处于改状态的总是一个打开文件的最后一个 block。
- UNDER_RECOVERY: 当文件租约超时,一个处于
UNDER_CONSTRUCTION状态下 block 在 block recovery 过程开始后会变更为该状态。 - COMMITTED: 表明 block 数据已经不会发生变化,但向 NameNode 报告处于
FINALIZED状态的 replica 数量少于最小副本数要求。 - COMPLETE: 当 NameNode 收到处于
FINALIZED状态的 replica 数量达到最小副本数要求后,则切换到该状态。只有当文件的所有 block 处于该状态才可被关闭。
NameNode 不会持久化存储这些状态,一旦 NameNode 发生重启,它将所有打开文件的最后一个 block 设置为 UNDER_CONSTRUCTION 状态, 其他则全部设置为 COMPLETE 状态。
下图展示了 block 的状态变化过程。 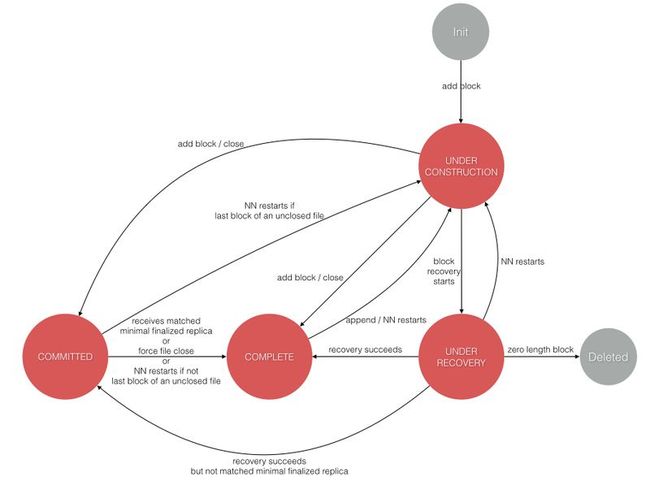
我们还是从 Init 开始简单描述下 block 的状态变迁图。
- 从
Init出发,只有当 Client 新建或追加文件写入时新创建的 block 处于UNDER_CONSTRUCTION状态。 - 从
UNDER_CONSTRUCTION出发,有三种情况:- 当客户端发起 add block 或 close 请求,若处于
FINALIZED状态的 replica 数量少于最小副本数要求,则切换到COMMITTED状态, 这里 add block 操作影响的是文件的倒数第二个 block 的状态,而 close 影响文件最后一个 block 的状态。 - 当客户端发起 add block 或 close 请求,若处于
FINALIZED状态的 replica 数量达到最小副本数要求,则切换到COMPLETE状态 - 若发生 block recovery,状态切换到
UNDER_RECOVERY。
- 当客户端发起 add block 或 close 请求,若处于
- 从
UNDER_RECOVERY,有三种情况:- 0 字节长度的 replica 将直接被删除。
- 恢复成功,切换到
COMPLETE。 - NameNode 发生重启,所有打开文件的最后一个 block 会恢复成
UNDER_CONSTRUCTION状态。
- 从
COMMITTED出发,有两种情况:- 若处于
FINALIZED状态的 replica 数量达到最小副本数要求或者文件被强制关闭或者 NameNode 重启且不是最后一个 block, 则直接切换为COMPLETE状态。 - NameNode 发生重启,所有打开文件的最后一个 block 会恢复成
UNDER_CONSTRUCTION状态。
- 若处于
- 从
COMPLETE出发,只有在 NameNode 发生重启,其打开文件的最后一个 block 会恢复成UNDER_CONSTRUCTION状态。 这种情况,若 Client 依然存活,有 Client 来关闭文件,否则由 lease recovery 过程来恢复(详见下文)。
理解了 block 和 replica 的状态及其变化过程,我们就可以进一步详细分析上述简要提及的几种自动恢复模式。
Lease Recovery 和 Block Recovery
前面讲了 lease recovery 的目的是当 Client 在写入过程中挂了后,经过一定的超时时间后,收回租约并关闭文件。 但在收回租约关闭文件前,需要确保文件 block 的多个副本数据一致(分布式环境下很多异常情况都可能导致多个数据节点副本不一致), 若不一致就会引入 block recovery 过程进行恢复。下面是整个恢复处理流程的简要算法描述:
- 获取包含文件最后一个 block 的所有 DataNodes。
- 指定其中一个 DataNode 作为主导恢复的节点。
- 主导节点向其他节点请求获得它们上面存储的 replica 信息。
- 主导节点收集了所有节点上的 replica 信息后,就可以比较计算出各节点上不同 replica 的最小长度。
- 主导节点向其他节点发起更新,将各自 replica 更新为最小长度值,保持各节点 replica 长度一致。
- 所有 DataNode 都同步后,主导节点向 NameNode 报告更新一致后的最终结果。
- NameNode 更新文件 block 元数据信息,收回该文件租约,并关闭文件。
其中 3~6 步就属于 block recovery 的处理过程,这里有个疑问为什么在多个副本中选择最小长度作为最终更新一致的标准? 想想写入流水线过程,如果 Client 挂掉导致写入中断后,对于流水线上的多个 DataNode 收到的数据在正常情况下应该是一致的。 但在异常情况下,排在首位的收到的数据理论上最多,末位的最少,由于数据接收的确认是从末位按反方向传递到首位再到 Client 端。 所以排在末位的 DataNode 上存储的数据都是实际已被确认的数据,而它上面的数据实际在不一致的情况也是最少的, 所以算法里选择多个节点上最小的数据长度为标准来同步到一致状态。
Pipeline Recovery
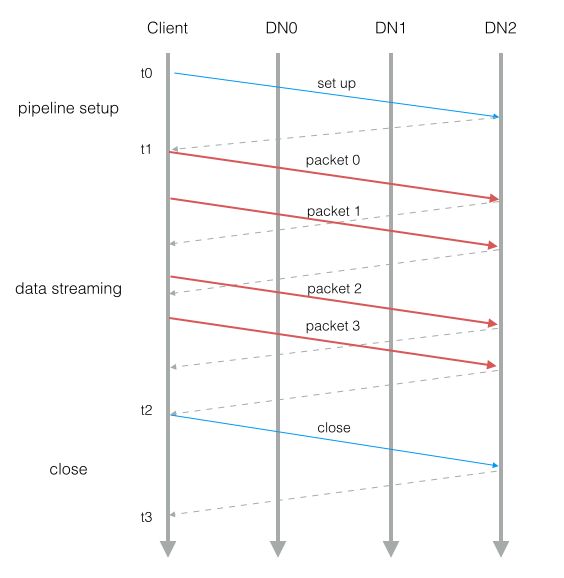
如上图所示,pipeline 写入包括三个阶段
- pipeline setup: Client 发送一个写请求沿着 pipeline 传递下去,最后一个 DataNode 收到后发回一个确认消息。 Client 收到确认后,pipeline 设置准备完毕,可以往里面发送数据了。
- data streaming: Client 将一个 block 拆分为多个 packet 来发送(默认一个 block 64MB,太大所以需要拆分)。 Client 持续往 pipeline 发送 packet,在收到 packet ack 之前允许发送 n 个 packet,n 就是 Client 的发送窗口大小(类似 TCP 滑动窗口)。
- close: Client 在所有发出的 packet 都收到确认后发送一个 Close 请求, pipeline 上的 DataNode 收到 Close 后将相应 replica 修改为
FINALIZED状态,并向 NameNode 发送 block 报告。 NameNode 将根据报告的FINALIZED状态的 replica 数量是否达到最小副本要求来改变相应 block 状态为COMPLETE。
Pipeline recovery 可以发生在这三个阶段中的任意一个, 只要在写入过程中一个或多个 DataNode 遭遇网络或自身故障。我们来分别分析下。
从 pipeline setup 错误中恢复
在 pipeline 准备阶段发生错误,分两种情况:
- 新写文件:Client 重新请求 NameNode 分配 block 和 DataNodes,重新设置 pipeline。
- 追加文件:Client 从 pipeline 中移除出错的 DataNode,然后继续。
从 data streaming 错误中恢复
- 当 pipeline 中的某个 DataNode 检测到写入磁盘出错(可能是磁盘故障),它自动退出 pipeline,关闭相关的 TCP 连接。
- 当 Client 检测到 pipeline 有 DataNode 出错,先停止发送数据,并基于剩下正常的 DataNode 重新构建 pipeline 再继续发送数据。
- Client 恢复发送数据后,从没有收到确认的 packet 开始重发,其中有些 packet 前面的 DataNode 可能已经收过了,则忽略存储过程直接传递到下游节点。
从 close 错误中恢复
到了 close 阶段才出错,实际数据已经全部写入了 DataNodes 中,所以影响很小了。 Client 依然根据剩下正常的 DataNode 重建 pipeline,让剩下的 DataNode 继续完成 close 阶段需要做的工作。
以上就是 pipeline recovery 三个阶段的处理过程,这里还有点小小的细节可说。 当 pipeline 中一个 DataNode 挂了,Client 重建 pipeline 时是可以移除挂了的 DataNode,也可以使用新的 DataNode 来替换。 这里有策略是可配置的,称为 DataNode Replacement Policy upon Failure,包括下面几种情况:
- NEVER:从不替换,针对 Client 的行为
- DISABLE:禁止替换,DataNode 服务端抛出异常,表现行为类似 Client 的 NEVER 策略
- DEFAULT:默认根据副本数要求来决定,简单来说若配置的副本数为 3,如果坏了 2 个 DataNode,则会替换,否则不替换
- ALWAYS:总是替换
总结
本文讲述了 HDFS 异常处理与恢复的处理流程和细节,它确保 HDFS 在面对网络和节点错误的情况下保证数据写入的持久性和一致性。 读完本篇相信你会对 HDFS 内部的一些设计和工作状态有更深的认识,本文特地抽象的描述了一些涉及具体算法的部分。 因为 HDFS 作为一个开源软件还在不断发展演变,具体算法代码实现总会变化, 但设计理念和 design for failure 的设计思考要点的持续性要长久的多,会更具参考价值。 如果你还想对某些特定细节的实现做进一步的了解,只能去深入阅读对应部分的代码,这无法通过阅读文档或相关文章来获得,这也是代码开源的价值所在。
参考
[1] Hadoop Documentation. HDFS Architecture.
[2] Robert Chansler, Hairong Kuang, Sanjay Radia, Konstantin Shvachko, and Suresh Srinivas. The Hadoop Distributed File System
[3] Tom White. Hadoop: The Definitive Guide. O'Reilly Media(2012-05), pp 94-96
[4] Yongjun Zhang. Understanding HDFS Recovery Processes
[5] Hairong
Kuang,
Konstantin
Shvachko,
Nicholas
Sze,
Sanjay
Radia,
Robert
Chansler
, Yahoo!
HDFS
team
Design Specification: Append/Hflush/Read
Design
[6] HDFSteam. Design Specification: HDFS Append and Truncates