ECMAScript 6 promises(上):基本概念
原文地址: http://www.2ality.com/2014/09/es6-promises-foundations.html
原文作者:Dr. Axel Rauschmayer
译者:倪颖峰
尽管原博客已经标明:本博客文档已经过时,可进一步阅读“Exploring ES6”中的 “Asynchronous programming (background)”。但仔细对比了下,两者行文没有什么太大区别。另外相对原来的译文,修订了其中的一些错误,增补了event loop图。
本文主要介绍一下JS中异步编程的基础。这是一个主体两篇博文的第一部分,第二部分会涵盖在 ES6 中 promises 的API。
1. JavaScript 中的调用堆栈
当函数 f 调用一个函数 g,g 就需要知道它完成后在哪里返回(在 f 内部)。这里的主要方式是使用栈进行管理,即调用堆栈。来看一个实例。
function h( z ){
// Print stack trace
console.log( new Error.stack ); // (A)
}
function g( y ){
h( y+1 ); // (B)
}
function f( x ){
g( x+1 ); // (C)
}
f( 3 ); // (D)
return;
开始,当上面的程序运行时,调用堆栈为空。
当在 D 处函数调用 f( 3 )时,栈中有了一个项:
当前的全局作用域
当在 C 处调用函数 g( x+1 )时,栈中就有了两个项:
当前的 f
当前的全局作用域
在当 B 处调用函数 h( y+1 )时,栈中含有了三项:
当前的 g
当前的 f
当前的全局作用域
在 A 处的栈跟踪内会展示出下面的调用堆栈:
Error at h (stack_trace.js:2:17) at g (stack_trace.js:6:5) at f (stack_trace.js:9:5) at <global> (stack_trace.js:11:1)
接下来,每当一个函数执行结束,栈中就会相应的删除顶部的对应项。当函数 f 结束后,就会回到全局作用域,然后调用栈变为空。在 E 处,返回是栈为空,意味着程序的结束。
2. 浏览器的事件循环
简而言之,每一个浏览器页面tab都有独立的进程,事件循环。该循环会执行浏览器相关的由一个任务队列分发的事务(称为 任务)。任务实例有:
1. 解析 HTML
2. 执行 script 标签中的 JS 代码
3. 处理用户交互(点击鼠标,键盘输入等)
4. 处理网络异步请求结果
2 - 4任务均是通过浏览器内置引擎来执行JS代码。在代码结束时结束。然后队列中的下一项任务开始被执行。下面图片展示了所有的机制是如何连接起来的。
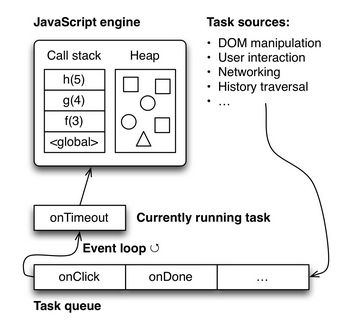
事件循环是掺杂在其他并行运行的各种进程中(定时器,输入处理器等)。这些进程同通过向其队列添加任务进行通信。
2.1. 定时器
浏览器具有定时器,setTimeout() 来创建定时器,等到触发时刻就会向其队列添加一个任务。如下标识:
setTimeout( callback, ms );
在ms毫秒之后, callback 回调函数就被添加到任务队列中。需要注意的是 ms 只是指定回调函数添加的事件,并不保证被执行。特别是如果事件循环被阻塞,那可能会在很久才执行(文章后面会提到)。
当 setTimeout() ms 设置为零是一个较为通用的方法来向队列立即添加任务。然而一些浏览器并不与许 ms 设置低于最小限度(FF 中为4ms);如果小于最小限度,那也会将被设置成最小限度值。
2.2. 显示DOM的变化
对于许多的DOM变化(特别是会引起重排的),也不会立即更新显示。“布局每16ms才会刷新一次”而且必须给予其通过事件循环执行的机会。
有一些办法来协调浏览器频繁的DOM更新,来避免布局结果的冲突。查询一下关于 requestAnimationFrame() 的详细文档吧。
2.3. 运行至完成 的语义
JS 所谓的运行至完成语义:当前任务总是在下一个任务执行前完成。这意味着每一个任务都可以完全控制所有的当前状态,并且不需要担心并发的修改。
看个例子:
setTimeout( function(){
console,log('Second'); // (A)
}, 0 );
console,log('First'); // (B)
在A处开始的函数是被立即添加到队列中的,但是只有在当前代码块完成之后(具体就是 B 处),才能执行。意味着代码输出永远是:
First Second
2.4. 阻塞事件循环
我们可以发现,每个tab(在一些浏览器,完整的浏览器)被单独的进程控制-包括用户界面和其它所有的运算。这意味着你在进程中执行长时间的运算将会使得用户界面被定格。延时代码如下:
<a id="block" href="">Block for 5 seconds</a>
<p>
<button>Simple button</button>
<script>
...
function onClick(event) {
event.preventDefault();
console.log('Blocking...');
sleep(5000);
console.log('Done');
}
function sleep(milliseconds) {
var start = Date.now();
while ((Date.now() - start) < milliseconds);
}
</script>
当函数执行时,同步的函数 sleep() 阻塞事件循环5秒钟,在这些时间里用户界面将被锁定。
2.5. 避免阻塞
你可以使用两种方式来避免阻塞事件循环:
首先,不要在主进程中执行长时间的计算,将其移到其他进程中。可以通过 Worker API 来实现。
其次,不应该(以同步方式)等待一个长时间运算的结果( 在Worker进程中运行你的算法,或者以网络请求等 ),你可以继续执行事件循环,是运算在完成的时候通知你。事实上,在浏览器中你没有什么选择,而只能这么做。比如,并没有内置的 sleep 同步(例如之前使用的 sleep() 方法)。取而代之的是 setTimeout() 异步的sleep方法。
下面部分将会讲解一下关于异步等待结果的技术。
3. 异步处理结果
异步处理结果的两个常见部分:事件与回调函数。
3.1 通过事件异步处理结果
在这部分的异步处理结果内容中,你需要为每一个请求创建一个对象,对其注册事件绑定:一个为计算成功,一个为出错。下面代码展示对于 XMLHttpRequest API的工作原理:
var req = new XMLHttpRequest();
req.open('GET', url);
req.onload = function(){
if( req.status === 200 ){
processData( req.response );
}else{
console.log( 'ERROR', req.statusText );
}
};
req.onerror = function(){
console.log('Network Error');
};
req.send();// add request to task queue
记住,事实上最后一行并不执行结果,它只是将其添加到任务队列。因此你也可以在 设置 onload和onerror之前,open() 之后正确的调用该方法。将会一样的执行,由于JS代码的 运行至完成的特性。
如果你使用多线程语言,indexedDB(索引型数据库)请求可能会引起相竞争的情况。因此,运行至完成的特性使得在JS变得安全可靠。
var openRequest = indexedDB.open( 'test', 1 );
openRequest.onsuccess = function( event ){
console.log('Success!');
var db = event.target.result;
}
openRequest.onerror = function( error ){
cosole.log( error );
}
open() 不会立即打开数据库,它会在队列中添加一个任务,该任务会在当前所有任务执行完毕之后执行。这就是为何你可以(事实上也是必须可以)在调用 open() 之后注册事件句柄的原因。
3.2. 通过回调函数异步处理结果
如果使用回调函数来异步处理结果,你需要将回调函数作为链接参数传递给异步函数或者方法进行调用。
下面为 Node.js 的实例。通过 fs.readFile() 异步读取文件内容:
// Node.js
fs.readFile( 'myfile.txt', { encoding: 'utf8' },
function(error, text){
if (error){ // (A)
// ...
}
console.log( text );
});
如果 readFile() 成功,在A处的回调函数就会通过参数 text 来传递结果值。如果失败,回调函数会通过第一个参数获取一个错误(一般来说是一个Error或者其子类)。
在经典的函数式编程风格中,代码可以是这样的:
// Functional
readFileFunctional( 'myfile.txt', { encoding: 'utf8' },
function( text ){
console.log( text ); // success
},
function( error ){ // failure
// .....
}
);
3.3. 连续传递风格
使用回调函数的编程风格(特别是之前展示的函数式编程方式)又叫做连续传递式(Continuation-Passing Style:CPS),因为下一步(the continuation)是当做一个参数被传递的。这使得调用函数可以得到更多的对于接下来运行的和什么时候运行的控制。
下面代码显示了所谓的CPS:
console.log('A');
identity('B', function step2(result2) {
console.log(result2);
identity('C', function step3(result3) {
console.log(result3);
});
console.log('D');
});
console.log('E');
// Output: A E B D C
function identity(input, callback) {
setTimeout(function () {
callback(input);
}, 0);
}
对于每一步,都在程序的控制流内进行回调。这就导致了有时被称为回调地狱的嵌套函数。当然,你完全可以避免嵌套,因为JS的函数声明是被提升的(它们被计算定义是在它们作用域的最开始阶段)。这意味着你可以提前调用和使用定义在程序后面的函数声明。下面代码就是使用提升使得之前的例子扁平化。
console.log('A');
identity('B', step2);
function step2(result2) {
// The program continues here
console.log(result2);
identity('C', step3);
console.log('D');
}
function step3(result3) {
console.log(result3);
}
console.log('E');
3.4. CPS中编写代码
在一般的JS风格中,我们使用以下方式来组合代码块:
1. 将其一个接一个放置。使代码变得一目了然,普通风格的级联式代码可以帮助我们提醒记住代码的正确组合顺序。
2. Array 的方法,比如 map(),filter() 和 forEach()。
3. 如 for 或者 while 的循环。
Async.js 这个库提供了让我们用 CPS 做的更简单的操作符,NodeJS 风格的回调函数。下面是一个被使用来加载存在数组中的三个文件内容。
var async = require('async');
var fileNames = [ 'foo.txt', 'bar.txt', 'baz.txt' ];
async.map( fileNames,
function( fileName, callback ){
fs.readFile( fileName, { encoding: 'utf8' }, callBack );
},
function( error, textArray ){
if( error ){
cosole.log( error );
return;
}
console.log( 'TEXTS:' + textArray.join( " " ) );
});
3.5. 回调函数的利弊
使用回调函数处理结果是一种完全不同的编程风格,CPS。CPS主要优点是很容易理解。当然,他有一些缺点:
1. 错误监控变的较为复杂:一般通过两种方式来处理报错,通过回调函数和异常。也需要小心两者相结合的情况。
2. 更少的信息:在同步函数中对于输入(参数)和输出(函数的返回值)会有一个明确的关系。在异步函数中使用回调函数,他们被混在一起:函数结果并不重要,并且一些参数作为输入,一些参数作为输出。
3. 组合变的更为复杂:因为有些输出就在参数中,这变成了更为复杂的组合器。
在 NodeJS 风格中回调函数有三个弊端(与函数式风格相比较):
1. 使用 if 语句处理错误状态增加了复杂程度。
2. 重用绑定函数较为困难。
3. 提供一个默认的错误处理函数也很困难。如果你对自己的函数调用不想写处理函数,那么默认的错误处理函数是非常有用的。它可以被使用在函数调用者没有指定特定的处理函数的时候。
4. 展望一下
第二部分主要包括了 promises 以及 ES6 中 promise API。Promises 底层的实现比回调函数复杂很多。当然,它也带来了挺多优势之处。