springrain vs jfianl的开发对比
废话不说,上实例
使用 jfinal最新版本 1.4 的 blog demo.
如果使用springrain 该怎么做呢?
总共分三步:
1.编写blog.sql 建表语句,花费2分钟左右时间
2.执行代码生成器,gen blog 并把生成文件拷贝到项目.di_car/freemarker 对应拷贝到 springrain/WebROOT/WEB-INF/freemarker
di_car/js 对应拷贝到 springrain/WebROOT/js
di_car/src_main 对应拷贝到 springrain/src
3.执行权限语句,springrain使用shiro控制权限,需要导入菜单和按钮的url才能让admin正常访问.初始化的语句也已经生成,执行以下就可以了
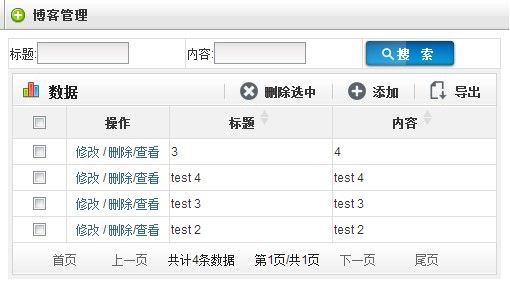
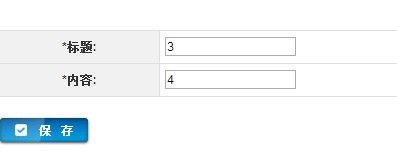
以上3步,大概花费3分钟左右.就此blog管理功能已经全部实现,包括 列表字段排序,增删改查,导出,(ps:其实导入也已经做好了,我只是没有把使用方法写入文档)
界面截图如下,也可以访问 springrain.9iu.org 在线访问,国外免费主机,速度较慢......

-----------------我是小小分割线-----------------------------------------------------------
会有人说,生成的代码好维护吗?
代码自动生成了 controller,service,html页面,js文件
html页面都是原生的freemarker 文件,js也很少东西
service 不是强制的,可以直接使用baseDemoService,其实,只要你想,一个项目只需要一个service
controller 生成了 增删改查 导入 导出的处理方法
因为 save update delete 都是orm对象操作,和jfinal差别也不大
重点说下查询.springrain所有的sql语句都是通过Finder 工具类封装,finder承载了 sql语句和响应的参数,而且是强制行为,因为底层没有直接执行sql的接口.看下finder带来的方便和优势,就会明白这样设计的原因
springrain的sql语句 使用命名参数 没有使用?,在拼接?不太直观和方便,特别是在动态条件较多的时候.
查询列表 org.springrain.demo.service.impl.BlogServiceImpl.findListDataByFinder(Finder, Page, Class<T>, Object) 只有一句话 return super.findListDataByFinder(finder,page,clazz,o);
简单查询,父类已经完全封装好了.如果你想手动控制 代码就是
finder=new Finder("select * from blog where 1=1 ");
//拼装动态where 条件,当然,你也可以手动拼装
getFinderWhereByQueryBean(finder, o);
//拼装 动态 order by ,用于列表字段排序
getFinderOrderBy(finder, page);
return super.queryForList(finder, clazz, page); springrain的查询方法都可以返回 实体类或者map 根据需要自行选择使用
具体参见 基本接口
因为和jfinal理念不同,springrain 默认生成了service层,再强调一次,这个service不是必要的.可以直接使用baseDemoService
我们现在很快做出模型草稿,让用户确认,这些模型页面和代码就能直接转入开发阶段.