列式存储 Parquet
本文涉及的Parquet的一些基本原理,可以参考网页:http://www.infoq.com/cn/articles/in-depth-analysis-of-parquet-column-storage-format
1. 最初创建Parquet的目的是:要在Hadoop生态系统中,充分利用数据压缩、有效列式存储的优势。Parquet面向复杂的嵌套数据结构,使用Dremel中的record shredding and assembly算法,其与简单命名空间嵌套的方法相比更加高效。Parquet支持有效的数据压缩和编码方式,甚至允许为不同列单独设置压缩方式。
2. 名词术语:block(数据块)、file(文件)、column chunk(列块):将数据按列存储时,每一列数据被分割成多个列块、row group(行组):每一列一个列块组合起来就构成行组、page(页):每一个列块被分割成很多页,页是压缩和编码的最小单元。分层次来看,Parquet中的一个文件包含一个或者多个行组,一个行组包含多个列块且每一列仅对应一个列块,每个列块包含一个或者多个页。需要说明的是:在parquet相关资料和源码中,block等同于row group,而非HDFS中的数据块。
3. 元数据(metadata):Parquet包括3种类型的元数据,文件元数据、行组元数据和列块元数据。
Parquet支持的原始数据类型有:1个bit的BOOLEAN、32个bit的INT32、64个bit的INT64、96个bit的INT96、32个bit的FLOAT、64个bit的DOUBLE、任意长度的字节数组BYTE_ARRAY。为了拓展原始数据类型,Parquet引入了逻辑类型,指定原始数据类型的解读方式。例如:字符串被保存为一个包含UTF8编码注解(annotation)的字节数组,注解定义了如何解读保存成原始数据类型的数据。注解在文件元数据中,被保存为一个ConvertedType类型的对象,在文档LogicalTypes.md中有逻辑类型注解的说明。
为了编码嵌套的列,Parquet引入了Dremel编码机制:加入了列定义深度以及列重复元素深度的概念。列定义深度指定到当前列元素的字段路径中,有值的可选(optional)字段的数量;列重复元素深度记录该重复出现的列元素的深度。从记录的数据中,可以计算出最大列定义深度和最大列重复元素深度。
空值被编码在列定义深度中,不会额外的存储空值。
4. 在MapReduce中使用Parquet File Format。Parquet文件格式的如下特性,使得其非常适合数据仓库类型的操作:分层列式存储,灵活的压缩策略,创新的编码模式,文件大小从几兆到几GB。MapReduce需要将thrift加入CLASSPATH和libraries中,来使用Parquet文件。
5. Parquet源码分析
Parquet采用参数:pageSizeThreshold,控制每一个Column Chunk中的Page大小,类ColumnWriterImpl实现了ColumnWriter接口,负责将输入数据的每一列写到文件中,其依赖于实现PageWriter的类,去完成将每一个Page写到文件输出流。在parquet-hadoop包中,ColumnChunkPageWriter类是PageWriter的实现类。在类ColumnWriterImpl中的accountForValueWritten函数,不断检测当前列所占的内存大小,一旦超过pageSizeThreshold参数时,会触发PageWriter的writePage操作,将当前内存中的所有数据都写到一个Page中。从这里来看,Parquet中每一个Page的大小并不严格确定,但是近似等于参数pageSizeThreshold的值。ColumnWriterImpl类采用ValuesWriter的实现类,例如:PlainValuesWriter等,实现将各种数据类型写到内存中,每一列的每一个Page中,又分别分成repetitionLevelColumn、definitionLevelColumn、dataColumn三块数据。在一个Page中,这三块数据是分块保存的。需要说明的是,parquet采用了优化的CapacityByteArrayOutputStream在内存中保存字节数据,该类维护了一个内存块列表,在当前内存大小不够的情况下,只需重新申请一块内存,并将它插入内存块列表中,不需要再移动之前内存块中的数据。Parquet实现了一个LittleEndianDataOutputStream将各种数据类型按照little endian的格式写成字节码。
ParquetRecordWriter关键类依赖关系,如下图所示
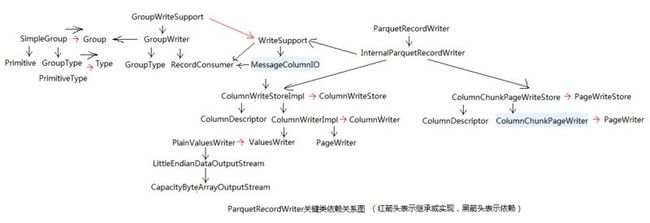
抽象类Type封装了当前字段的名称、重复类型(Repetition)、以及逻辑类型(OriginalType)。其中OriginalType可以是MAP、LIST、UTF8、MAP_KEY_VALUE、ENUM、DECIMAL,分别代表当前字段是一个哈希映射表Map、线性表List、UTF8编码的字符串、包含键值对的Map、枚举类型、十进制数。PrimitiveType和GroupType是抽象类Type的两个子类,分别代表Parquet支持的原始数据类型和Group多个字段的组合类型。MessageType是GroupType的子类,代表Parquet描述数据字段的schema的根节点。Parquet中抽象类Group表示包含一组字段的Parquet schema节点类型,SimpleGroup是Group的一个子类,顾名思义,其定义了一个最简单形式的Group,仅包含一个GroupType表示Group类型和一个List数组保存该Group中的字段数据,各字段在List数组中的顺序和在GroupType中定义的一致,每个List中可以保存Primitive类型的原始数据类型,也可以保存一个Group。也就是说一个SimpleGroup类型可以表示由schema表示的一行记录。
从上面的类依赖关系图中,我们可以看到两个相对分离的类的集合。第一个是由Group和Type组成的,描述数据字段以及数据模式schema(schema的概念可参考本文开头url),另一个是由ColumnWriter和PageWriter为核心构成的一组类,完成将数据分行分页的保存操作。从InternalParquetRecordWriter的函数checkBlockSizeReached,可以发现每写入一定数量的数据时,该方法会检测当前block size(这里的block其实指的是RowGroup的大小),默认的block size是128MB,当大于128MB时,该函数会触发将block数据写入HDFS文件的操作,这种机制和上述的page size处理方式类似。
从本人对源码的分析,可以总结出在MapReduce中使用ParquetRecordWriter的方法。WriterSupport可以使用GroupWriteSupport,另外还需要通过文本创建schema,提供给ParquetRecordWriter的构造函数,其它构造参数可以使用默认值。从Parquet源码中现有的ExampleOutputFormat即实现了上述功能,默认使用GroupWriteSupport,只需要设置一下schema。ExampleOutputFormat实现了将Group类型的数据,分RowGroup,分Column Chunk,分Page保存的功能。若是简单的只使用Parquet的列式存储的功能,可以直接使用ExampleOutputFormat,然后使用Void作为输出的key,Group的实现类SimpleGroup类作为value。其它的使用方法和MR中TextOutputFormat等一致。最后输出的文件就是Parquet file format。
ParquetMetaData类封装了Parquet文件的元数据信息,其包含一个FileMetaData类和一个BlockMetaData List,并且提供静态方法,采用org.codehaus.jackson包将ParquetMetaData变成json格式,当然也提供函数将json格式的元数据转换成一个ParquetMetaData对象。FileMetaData类包含文件的元数据,包含数据描述信息schema、String键值对Map<String,String>、以及文件创建版本信息。
6. 在MapReduce中使用Parquet
Parquet提供了一个类ParquetOutputFormat,继承自FileOutputFormat,可以直接被MapReduce使用。ExampleOutputFormat继承自ParquetOutputFormat,指定写入的key value类型分别为Void和Group。ParquetOutputFormat提供函数,设置block size(RowGroup的大小)、page size、page的压缩方式。Parquet实现了一个ParquetFileWriter,包装了写Parquet文件的ColumnChunkMetaData、BlockMetaData以及FileMetaData的过程。在开始写Parquet文件时,必须首先调用start函数,该函数会往Parquet文件中写入一个字符串“PAR1”,表征进入文件写状态。在开始写入一个block之前,必须先调用startBlock函数,并传入该block中包含的字段数量作为参数,startBlock函数会创建一个空的BlockMetaData对象,并记录在变量currentRecordCount中记录block中字段总数量。在写一列之前,必须先调用startColumn函数,该函数会记录当前Column Chunk的编码方式、文件路径、Chunk类型、压缩方式、字段数量、起始Data Page在文件中的偏移量,并初始化当前Column Chunk的压缩前和压缩后的数据长度为0。随后便可以一次或者多次调用writeDictionaryPage和writeDataPage操作。writeDataPage函数会给每一个Page数据添加一个Page Header,Page Header包括了当前Page未压缩之前的大小、压缩后的大小、字段数量、repetition leval编码方式、definition leval编码方式、数据编码方式、当前字段的最大值最小值等统计信息,然后将Page数据写入文件。在结束当前block当前列的写操作时,先调用endColumn函数,该函数负责创建刚写入的ColumnChunk的MetaData,并插入当前Block MetaData的ColumnChunkMetaData List中,并计算当前block的总大小。在完成所有列的写操作之后,需先调用endBlock函数,该函数将BlockMetaData插入List之中。在完成所有block的写操作之前,需先调用end函数,该函数会创建一个ParquetMetaData对象,并写入Parquet文件中,然后关闭文件,完成整个Parquet文件的写操作。
10. 如何为parquet文件格式添加分块索引功能?
parquet自带的ExampleOutputFormat,继承自ParquetOutputFormat,实现了数据的分列分块保存的功能。但是却没有为每一个block(row group添加索引),因此,比如说我要读某一个字段为一个固定值的所有记录,则需要遍历整个parquet文件。如果针对某个字段,读取其为固定值的所有记录的情况比较频繁,这时我们便可以考虑为该字段建立一个索引。建立索引的方法可能根据不同数据而不同,但是基本的原理都类似,主要是利用FileMetaData(文件元数据)、BlockMetaData(row group元数据)、ColumnChunkMetaData(列块元数据)记录数据的索引信息。本文将针对作者遇见的情况,为parquet文件添加分块索引。这里的背景是这样的,有一批日志文件,分别是不同活动不同时间不同用户的接触记录。读数据的时候,经常遇到读一个活动的所有记录的情况,考虑到活动数量小于10000,以及一个活动的数据量,我选择采用的一个方案是:我们在写文件的时候,将数据记录按照活动排序,一个block(row group)只保存一个活动的数据,考虑到有些活动可能数据量较大,允许其占用多个block,然后在文件元数据中记录block和活动id的对应关系就可以为活动建立分块索引的功能。
具体如何实现上面的思想呢?下面是作者对parquet中,和建立分块索引相关的关键类的一些分析。
通过上面的源码分析,我们锁定了InternalRecordWriter类。该类的write(T value)函数负责将一条记录写入内存中,并且调用checkBlockSizeReached()函数定期监测block使用内存大小,一旦超过内存,立即将block写入文件。因此,我们首先要改写的就是write函数,改为write(String caid,T value),在写记录T value之前,首先调用函数checkCaidBegin()函数,检查是否是一个新的活动,如果是一个新的活动,则将当前内存中的数据作为一个block写入parquet文件中,并且记录下block index和caid的对应关系。在结束写文件之前,会调用该类的close()函数,该函数负责将所有元数据写入parquet文件的末尾,因此,重写该函数,将之前记录下的caid和block index的对应关系加入文件元数据中。通过查看函数close()的源码,可以发现,该函数会首先合并两个Map<String, String>对象,其中extraMetaData是该类的数据成员,通过构造函数传入,另一个是FinalizedWriteContext的数据成员,WriteContext是WriteSupport的内部类,WriteSupport对象也是通过构造函数传入的。因此,我们可以考虑,将caid和block index按一定格式,写入到这两个Map<String, String>对象中,那究竟选择哪个Map写入分块索引信息呢?我们则要看看在哪构造了InternalRecordWriter对象,是ParquetRecordWriter类,但是该类也只是简单的传递了一下构造函数,我们继续看看在哪构造了ParquetRecordWriter对象,是ParquetOutputFormat类。ParquetOutputFormat类的getRecorWriter函数首先调用getWriteSupport(conf)函数,构造一个WriteSupport对象。WriteContext类很简单,就是包含一个MessageType对象和一个Map<String, String>对象的普通类。WriteContext对象由WriteSupport调用init(conf)函数产生,从WriteSupport的一个实现类GroupWriteSupport的init函数来看,其给WriteContext传入的是一个空的HashMap<String, String>。在WriteSupport的方法finalizeWrite()中可以发现,其用于构造FinalizedWriteContext的也是一个空的HashMap<String, String>。因此,基本可以得出结论:在InternalRecordWriter类函数close中合并的两个Map,默认情况下都是空值。因此,可以任选一个Map<String, String>写入Caid和block index的对应关系。
上面解决了写parquet文件分块索引信息的问题,那么如何按活动读取parquet分块索引文件呢?
同样,我们锁定了InternalParquetRecordReader类,该类包含一个数据成员filter,并将其通过构造函数传入RecordReader对象中,可以推测该filter是在记录级别进行过滤。那么在哪进行block(row group)级别的过滤呢?我们往上锁定ParquetInputFormat类。该类最重要的是重载了其父类FileInputFormat的List<InputSplit> getSplit(JobContext jobContext)方法。ParquetInputFormat支持两种ParquetMataData文件元数据的处理方式,第一种方式是在task side(也就是执行map函数的executor机器)读取Parquet文件的元数据,另一种方式是在master side(也就是MR job提交到的机器上),并将Parquet文件切分成多个ParquetInputSplit,在ParquetRecordReader的initialize函数中,调用initializeInternalReader函数,如果是第一种方式,在该函数中将完成FileSplit到ParquetInputSpllit的转换。这两种方式都调用了RowGroupFilter的filterRowGroup函数,过滤掉不需要读取的block(row group)。因此,为了实现上述索引文件的读取,我们需要重写RowGroupFilter的filterRowGroup方法,在该方法中需要传入FileMetaData中的数据成员Map<String, String> keyValueMetaData,其包含了parquet文件分块索引信息。
到这里我们就完成了为parquet文件建立分块索引的文件读写功能。
11. Parquet当前支持两种指定filter(过滤器)的方式:第一种方式定义在parquet-column项目的parquet.filter中,支持在字段组装阶段,过滤某些不需要的字段;第二种方式定义在parquet.filter2库中,支持在不读取row group的情况下,过滤整个row group。定义在parquet-hadoop项目的parquet.filter2.compat包中的RowGroupFilter类就是一个row group过滤器。Filter可以是旧版API中的UnboundRecordFilter,也可以是新版API中的FilterPredicate。
12. ParquetInputFormat相关类分析
在MapReduce中,和ParquetOutputFormat对应的类是ParquetInputFormat。该类继承了FileInputFormat类,并重载了createRecordReader和getSplits方法,分别完成数据字段的组装和parquet文件的分片功能。Parquet文件的一个分片被封装成一个继承自FileSplit的ParquetInputSplit对象,记录了文件分片的路径、在文件中的起始位置、分片长度、保存有该分片数据的机器名、该分片中各row group的起始位置、row group的结束位置。